python collections模块
collections.Counter([iterable-or-mapping]
Counter是用来对对象进行计数,主要是针对于重复元素的个数的计数,详细如下:
from collections import Counter
c = Counter('gallahad')
print(c)
c = Counter({'red': 4, 'blue': 2})
print(c)
c = Counter(cats=4, dogs=8)
print(c)
Counter({'a': 3, 'l': 2, 'g': 1, 'h': 1, 'd': 1})
Counter({'red': 4, 'blue': 2})
Counter({'dogs': 8, 'cats': 4})
由此可见Counter返回的是以(元素:个数)为键值对组成的字典,如果传入的是字典或者是关键字参数,则之间返回对应字典。
由上述结构可见,Counter是dict的一个子类,用于计数可哈希对象。它是一个集合,元素像字典键(key)一样存储,它们的计数存储为值。因此我们可以单独取出对应元素的个数,之间使用字典的取值方法即可,当然删除字典元素也是如此,删除元素后再去访问对应的元素,虽然没有了对应的键,但不会报错,只会返回0,如下:
from collections import Counter
c = Counter('gallahad')
print(c)
print(c['a'])
del c['a']
print(c)
print(c['a'])
Counter({'a': 3, 'l': 2, 'g': 1, 'h': 1, 'd': 1})
3
Counter({'l': 2, 'g': 1, 'h': 1, 'd': 1})
0
python3.7后继承了字典的记住插入顺序的功能,在 Counter 对象上的许多操作也会保持顺序。
由于Counter是dict的子类,因此可以使用字典的方法或属性,除此之外,还有如下方法:
- elements(): 返回计数后的字典的所有的key,是不重复的
from collections import Counter
c = Counter('gallahad')
for item in c:
print(item)
g
a
l
h
d
- most_common([n]):按照元素的出现频率,返回出现次数最高的元素(以字典形式)
from collections import Counter
c = Counter('gallahad')
print(c.most_common(2))
[('a', 3), ('l', 2)]
- subtract([iterable-or-mapping]) 3.2新增: 将Counter对象做减法处理,即将对应key的value相减
from collections import Counter
c = Counter({'red': 4, 'blue': 2, 'green': 5})
print(c)
c2 = Counter({'red': 0, 'blue': 4})
print(c2)
c.subtract(c2)
print(c)
Counter({'green': 5, 'red': 4, 'blue': 2})
Counter({'blue': 4, 'red': 0})
Counter({'green': 5, 'red': 4, 'blue': -2})
由结果可见,当两个Counter对象中存在的元素不一致时,会默认显示多出的元素的数据。
- total():3.10新增,计
Counter对象的结果的字典的所有value的总和。
from collections import Counter
c = Counter({'red': 4, 'blue': 2, 'green': 5})
print(c)
print(c.total())
Counter({'green': 5, 'red': 4, 'blue': 2})
11
- update([iterable-or-mapping]): 将;两个或者多个
Counter对象合并,类似于dict.update
from collections import Counter
c = Counter({'red': 4, 'blue': 2, 'green': 5})
c2 = Counter({'red': 2, 'blue': 1, 'green': 4})
c.update(c2)
print(c)
Counter({'green': 9, 'red': 6, 'blue': 3})
Counter常用方法
c.total() # 统计Counter对象中的所有元素的个数
c.clear() # 情况Counter对象
list(c) # 去重、获取数据中的唯一的值(Counter中的key)
set(c) # 将Counter对象转为集合类型,只会有key
dict(c) # 将Counter对象转为字典类型
c.items() # 获取Counter对象的键值对,以元组形式(key, value)
Counter(dict(list_of_pairs)) # 将列表中元素为(key, value)转为字典
c.most_common()[:-n-1:-1] # 获取Counter对象前n个元素最小的元素
+c # 移除Counter对象中的元素个数为0的元素
Counter支持集合的交、并、减、加等,是对Counter对象中的元素操作
from collections import Counter
c = Counter({'red': 4, 'blue': 2, 'green': -5, "black": 0})
c2 = Counter({'red': 2, 'blue': 1, 'green': 4})
print(c - c2)
print(c + c2)
print(c & c2)
print(c | c2)
print(+c)
print(-c)
Counter({'red': 2, 'blue': 1})
Counter({'red': 6, 'blue': 3})
Counter({'red': 2, 'blue': 1})
Counter({'red': 4, 'green': 4, 'blue': 2})
Counter({'red': 4, 'blue': 2})
Counter({'green': 5})
-相当于是subtract,不过-返回的是最小集,并且是直接返回,subtract对调用元素进行操作,并且返回的是最大集。
+相当于update, 与上述-与subtract区别类似。
&相当于选取Counter对象中的公共属性的最小值
|相当于选取Counter对象中的公共属性的最大值
+只显示Counter对象中的元素值为正数的
-只显示Counter对象中元素值为负数的,显示时显示负数的绝对值
collections.defaultdict
collections.deque([iterable[, maxlen]])
- iterable: 基于创建的对象,如果没有指定,则队列为空
- maxlen:队列的最大长度,如果不设置则无限制
返回一个双向队列,从iterable迭代对象中创建,基于栈和队列生成,顾名思义,可以进行双向的操作,拥有列表的大部分方法,除此之外,由于可以进行双向操作,插入和删除时可以指定操作的方向(从左向右还是从右向左)。
- 注意,当设置了
maxlen最大长度之后,如果队列中元素已经满了,在对应侧添加元素将会弹出另一侧的元素,例如在左侧添加了一个元素,右侧的一个元素将会被弹出。 - 索引访问在两端的复杂度均为 O(1) 但在中间则会低至 O(n)。 如需快速随机访问,请改用列表。
deque内置的方法:
上面介绍中有说,队列具有列表的大部分方法,例如:
- append(x): 将x添加至队列的右端
- clear(): 清空队列
- copy(): 浅拷贝,拷贝的是引用,修改数据会影响原数据
- count(x): 3.5新增,计算某个元素的出现次数
- extend(iterable): 扩展列表
- index(x[, start[, stop]]):返回x元素在队列中的位置,可以指定查找的索引区间
- insert(i, x):在索引为i的位置插入元素x
- pop():删除队列中最右侧的一个元素并返回
- remove(value):删除值为value的元素
- reverse(): 将队列进行降序排序
除此之外,由于是双向队列,会存在双向的操作,因此额外存在如下方法: - appendleft(x):将元素x添加至队列的最左侧
- extendleft(iterable):在队列的最左侧扩展可迭代对象
- popleft():删除队列中的最左侧的元素并返回
- rotate(n=1): 当n>0时,向右循环n步,相当于
appendleft(pop())当n<0,向左循环n步,相当于append(popleft()),为了更加直观的了解这个方法,下面将进行举例说明:
from collections import deque
d = deque([1, 2, 3], 4)
print(d)
d.rotate(1)
print(d)
d.rotate(2)
print(d)
执行流程如下:
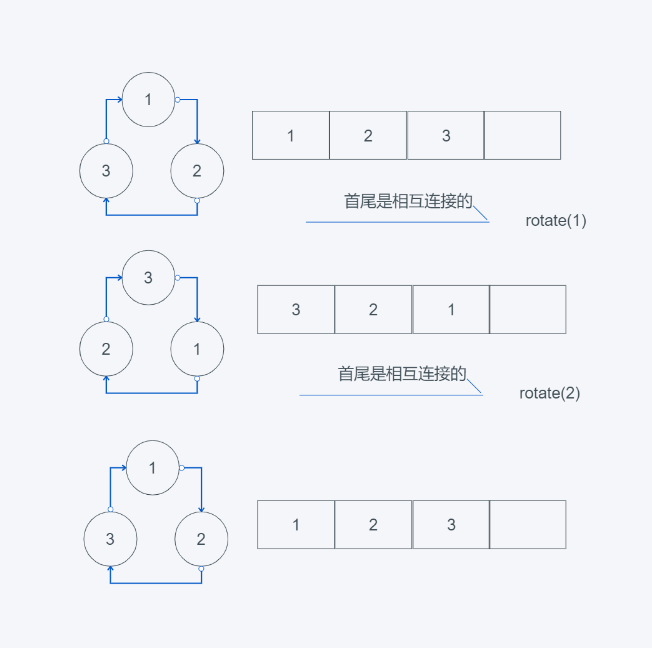
由此可以看出一个特性,当队列使用rorate执行了len(deque) * n次后,队列元素值不变。
常见使用场景
1.当需要对序列中的元素进行频繁的添加、删除操作时,建议使用双向队列,而不是列表;当需要进行随机访问序列中的元素时,建议使用列表。
2.实现类似于unix的tail过滤功能:
例如存在如下test.txt
test1
test2
test3
test4
test5
test6
test7
test8
test9
from collections import deque
from pathlib import Path
def tail(file_path, n=5):
with open(file_path, mode="r", encoding="utf-8") as f:
return deque(f, n)
file = Path(__file__).parent.joinpath("test.txt")
print(tail(file))
deque(['test5\n', 'test6\n', 'test7\n', 'test8\n', 'test9'], maxlen=5)
3.可以使用rorate实现切片和删除队列中的元素
from collections import deque
from typing import Deque
list_data = [1, 2, 3, 4, 5]
d = deque(list_data)
def slice(d: Deque, start: int, stop: int, step: int):
d.rotate(-start)
for i in range(stop):
d.pop()
d = filter(lambda n: n % step == 0, d)
return deque(d)
print(slice(d, 1, 3, 2))
list_data = [1, 2, 3, 4, 5]
d = deque(list_data)
def del_n(d: Deque, n):
"""删除索引为n的元素"""
d.rotate(-n)
d.popleft()
d.rotate(n)
return d
print(del_n(d, 3))
4.轮询调度器,可以在不同的迭代器中依次进行轮询第一个元素、第二个元素、第n个元素,直至迭代器结束。
def roundrobin(*iterables):
"roundrobin('ABC', 'D', 'EF') --> A D E B F C"
iterators = deque(map(iter, iterables))
print(list(iterators))
while iterators:
try:
while True:
yield next(iterators[0])
iterators.rotate(-1)
except StopIteration:
# 移除迭代完成的迭代器
iterators.popleft()
collections.defaultdict(default_factory=None, /[, ...])
- default_factory:默认的工厂,类似于是指定了字典的value值的类型。如果 default_factory 属性为 None,则调用本方法会抛出 KeyError 异常,附带参数 key。如果 default_factory 不为 None,则它会被(不带参数地)调用来为 key 提供一个默认值,这个值和 key 作为一对键值对被插入到字典中,并作为本方法的返回值返回。
返回一个新的类似字典的对象。defaultdict 是内置dict类的子类。它重载了一个方法并添加了一个可写的实例变量。
常用使用场景
1.将列表中存在重复元素的元组,转成字典,会自动将重复元素的value值添加至列表中
from collections import defaultdict
s = [('yellow', 1), ('blue', 2), ('yellow', 3), ('blue', 4), ('red', 1)]
d = defaultdict(list)
for k, v in s:
d[k].append(v)
print(d)
defaultdict(<class 'list'>, {'yellow': [1, 3], 'blue': [2, 4], 'red': [1]})
与使用dict.setdefault类似
d = {}
for k, v in s:
# 获取key并设置默认值为[], 由于赋值赋的是列表,因此返回的类型也是列表
data: List = d.setdefault(k, [])
print(isinstance(data, List))
# 向列表中添加元素
data.append(v)
{'yellow': [1, 3], 'blue': [2, 4], 'red': [1]}
使用default_dict相比较setdefault,将设置默认值省去了。
2.统计可迭代对象的元素个数,就是将default_factory变为int, 相当于是Counter统计元素个数一样
from collections import defaultdict
d = defaultdict(int)
data = "asdadwqeqdfa"
for k in data:
d[k] += 1
print(d)
defaultdict(<class 'int'>, {'a': 3, 's': 1, 'd': 3, 'w': 1, 'q': 2, 'e': 1, 'f': 1})
直接使用可迭代对象的count也可以, 不过可能会出现重复操作,之所以值不会重复,是因为字典默认是无序,不可重复的。
data = "asdadwqeqdfa"
d = {}
for k in data:
d[k] = data.count(k)
print(d)
{'a': 3, 's': 1, 'd': 3, 'w': 1, 'q': 2, 'e': 1, 'f': 1}
3.default_factory设置set构建字典集合,它可以帮助我们去重。
from collections import defaultdict
s = [('red', 1), ('blue', 2), ('red', 3), ('blue', 4), ('red', 1), ('blue', 4)]
d = defaultdict(set)
for k, v in s:
d[k].add(v)
print(d)
也可以使用setdefault
from typing import Set
data = [('red', 1), ('blue', 2), ('red', 3), ('blue', 4), ('red', 1), ('blue', 4)]
d = {}
for k, v in data:
set_data: Set = d.setdefault(k, set())
set_data.add(v)
print(d)
'red': {1, 3}, 'blue': {2, 4}}
collections.namedtuple(typename, field_names, *, rename=False, defaults=None, module=None)
命名元组,命名元组赋予每个位置一个含义,提供可读性和自文档性。它们可以用于任何普通元组,并添加了通过名字获取值的能力,通过索引值也是可以的。相当于是使用命令元组可以创建了一个类,类似于type()创建类,但它可以将类的属性一一对应。
- typename:元组子类的名称,就是创建的类的名称
- field_names:类中的参数,可以是序列,例如
['x', 'y'], 也可以是纯字符串,'x y' 或者 'x, y' - rename: 对于无效关键字的重命名,默认为
False, 当为True时,则会对关键字进行重命名,以下划线+当前位置的索引表示,例如_3, 需要注意的是字符串的关键字是针对于field_names中的内容,不能使用python的关键字,对于无效关键字的认定还有重复的属性名称,。 - defaults:默认对
field_names中属性的批量赋值,可以为None或者可迭代对象,注意defaults中的属性是与靠右侧属性对齐。 命名元组实例没有字典,所以它们要更轻量,并且占用更小内存。
基本示例
1.下面创建了一个Person子类,并且设置其中的属性及默认值,命名元组尤其有用于赋值 csv sqlite3 模块返回的元组.
from collections import namedtuple
Person = namedtuple("Person", ["name", "age", "city"], rename=True, defaults=["南京"])
p1 = Person(name="tom", age=19, city="北京")
print(p1)
p2 = Person(name="mike", age=20)
print(p2)
Person(name='tom', age=19, city='北京')
Person(name='mike', age=20, city='南京')
常用方法
- namedtuple._make(iterable):
基于iterable创建一个新的实例,相当于实例化了一个对象.
需要注意的是,当使用_make时默认值失效,必须要传递默认值。
from collections import namedtuple
Person = namedtuple("Person", ["name", "age", "city"], rename=True, defaults=["南京"])
data = ["tom", 10, "北京"]
p = Person._make(data)
print(p)
Person(name='tom', age=10, city='北京')
namedtuple._asdict():返回实例对象的字典形式
from collections import namedtuple
Person = namedtuple("Person", ["name", "age", "city"], rename=True, defaults=["南京"])
p1 = Person(name="tom", age=19, city="北京")
print(p1)
print(p1._asdict())
Person(name='tom', age=19, city='北京')
{'name': 'tom', 'age': 19, 'city': '北京'}
- namedtuple._replace(**kwargs): 替换实例对象中的部分属性并返回新的实例对象
from collections import namedtuple
Person = namedtuple("Person", ["name", "age", "city"], rename=True, defaults=["南京"])
p1 = Person(name="tom", age=19, city="北京")
print(p1)
print(p1._replace(city="南京"))
print(p1)
Person(name='tom', age=19, city='北京')
Person(name='tom', age=19, city='南京')
Person(name='tom', age=19, city='北京')
- namedtuple._fields: 返回当前实例对象的所有属性名,以元组形式返回
from collections import namedtuple
Person = namedtuple("Person", ["name", "age", "city"], rename=True, defaults=["南京"])
p1 = Person(name="tom", age=19, city="北京")
print(p1)
print(p1._fields)
Person(name='tom', age=19, city='北京')
('name', 'age', 'city')
- namedtuple._field_defaults: 返回命名元组的设置的默认属性及默认值,以字典形式返回
from collections import namedtuple
Person = namedtuple("Person", ["name", "age", "city"], rename=True, defaults=["南京"])
p1 = Person(name="tom", age=19, city="北京")
print(p1)
print(p1._field_defaults)
Person(name='tom', age=19, city='北京')
{'city': '南京'}
常用实践
1.获取实例对象的属性的值,可以使用对象.属性,也可以使用getattr(对象,属性)。
from collections import namedtuple
Person = namedtuple("Person", ["name", "age", "city"], rename=True, defaults=["南京"])
p1 = Person(name="tom", age=19, city="北京")
print(p1)
print(p1.name)
print(getattr(p1, "name"))
2.转换一个字典到命名元组,使用 ** 两星操作符
from collections import namedtuple
Person = namedtuple("Person", ["name", "age", "city"], rename=True, defaults=["南京"])
dict_data = {'name': 'tom', 'age': 19, 'city': '北京'}
print(Person(**dict_data))
Person(name='tom', age=19, city='北京')
3.可以通过继承命名元素,实现类,移除__dict__从而降低内存开销
from collections import namedtuple
Person = namedtuple("Person", ["name", "age", "city"], rename=True, defaults=["南京"])
class Person(Person):
__slot__ = []
def run(self):
print(self.name, self.age, self.city)
p = Person(name='TOM', age=12)
print(p)
Person(name='TOM', age=12, city='南京')
collections.ChainMap(*maps)
将多个字典或者其他映射组合在一起,创建一个单独的可更新的视图,说通俗点就是将多个字典合起来,
对于重复的key值默认会取第一个字典中的值
from collections import ChainMap
from typing import Iterable
a = {"x": 1, "y": 2}
b = {"x": 2, "z": 3}
c = {"y": 3, "z": 4}
d = ChainMap(a, b, c)
print(d)
print(isinstance(d, Iterable))
print(d.get("x", None))
print(d.get("y", None))
print(d.get("z", None))
ChainMap({'x': 1, 'y': 2}, {'x': 2, 'z': 3}, {'y': 3, 'z': 4})
True
1
2
3
由结果可以看出,虽然结合在了一起,但是内部还是存储的字典,并且返回的是一个可迭代对象,重复元素取的都是第一个获取到的元素
对于新增或者修改元素时,只会更新第一个字典 ;对于删除时,默认只会删除第一个字典中的数据,如果第一个字典中没有需要删除的元素,则会直接报错
from collections import ChainMap
from typing import Iterable
a = {"x": 1, "y": 2}
b = {"x": 2, "z": 3}
c = {"y": 3, "z": 4}
d = ChainMap(a, b, c)
print(d)
d['x'] = 2
print(d)
d['z'] = 3
print(d)
del d['x']
del d['w']
ChainMap({'x': 1, 'y': 2}, {'x': 2, 'z': 3}, {'y': 3, 'z': 4})
ChainMap({'x': 2, 'y': 2}, {'x': 2, 'z': 3}, {'y': 3, 'z': 4})
ChainMap({'x': 2, 'y': 2, 'z': 3}, {'x': 2, 'z': 3}, {'y': 3, 'z': 4})
Traceback (most recent call last):
File "D:\programs\python3.10\lib\collections\__init__.py", line 1042, in __delitem__
del self.maps[0][key]
KeyError: 'w'
KeyError: "Key not found in the first mapping: 'w'"
由结果也可以看出,对于新增、更新、删除只会操作第一个字典。
对字典操作的影响会直接影响到第一个字典
还是沿用上述的字典
from collections import ChainMap
from typing import Iterable
a = {"x": 1, "y": 2}
b = {"x": 2, "z": 3}
c = {"y": 3, "z": 4}
d = ChainMap(a, b, c)
print(d)
d['x'] = 2
print(d)
d['z'] = 3
print(d)
print(a)
hainMap({'x': 1, 'y': 2}, {'x': 2, 'z': 3}, {'y': 3, 'z': 4})
ChainMap({'x': 2, 'y': 2}, {'x': 2, 'z': 3}, {'y': 3, 'z': 4})
ChainMap({'x': 2, 'y': 2, 'z': 3}, {'x': 2, 'z': 3}, {'y': 3, 'z': 4})
{'x': 2, 'y': 2, 'z': 3}
由结果可以看出,对于d的操作影响到了它的第一个字典c,相当于是浅拷贝
说了这么多,其实对于字典的合并还有一个自带的update,不过它会另外破坏字典的原始结构,并且创建后的字典于创建之前的字典没有任何关系,相当于深拷贝。
collections.OrderedDict()
通过名称,我们可以得知,这个其实也是一个字典,不过它可以记住插入时的顺序,从而在输出时按照插入时的顺序进行输出,但是此对象会占用较大内存,为一个普通字典的两倍。主要用于修改字典中的顺序。
from collections import OrderedDict
dict_data = OrderedDict()
dict_data["key1"] = 1
dict_data["key2"] = 2
dict_data["key3"] = 3
dict_data["key4"] = 4
for key, val in dict_data.items():
print(key, val)
data = OrderedDict.fromkeys("abcvn")
data.move_to_end("b", last=True)
print(data)
data.move_to_end("n", last=False)
print(data)
key1 1
key2 2
key3 3
key4 4
OrderedDict([('a', None), ('c', None), ('v', None), ('n', None), ('b', None)])
OrderedDict([('n', None), ('a', None), ('c', None), ('v', None), ('b', None)])
注意事项
-
OrderedDict 内部维护着一个根据键插入顺序排序的双向链表。每次当一个新的元素插入进来的时候, 它会被放到链表的尾部。对于一个已经存在的键的重复赋值不会改变键的顺序。
-
一个 OrderedDict 的大小是一个普通字典的两倍,因为它内部维护着另外一个链表。 所以如果你要构建一个需要大量 OrderedDict 实例的数据结构的时候(比如读取 100,000 行 CSV 数据到一个 OrderedDict 列表中去), 那么你就得仔细权衡一下是否使用 OrderedDict 带来的好处要大过额外内存消耗的影响。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号