python 链表、堆、栈
简介
很多开发在开发中并没有过多的关注数据结构,当然我也是,因此,我写这篇文章就是想要带大家了解一下这些分别是什么东西。
链表
概念:数据随机存储,并且通过指针表示数据之间的逻辑关系的存储结构。
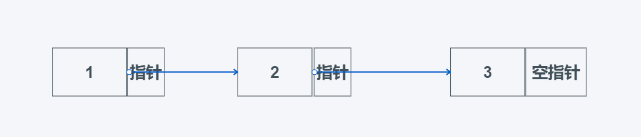
链表由两个部分组成
- 数据域:存放数据的地方
- 指针域:存放指针的地方
![image]()
需要注意的是,链表无序数据顺序存储,可以随机存储,例如下面:
![image]()

链表的特性
- 添加和删除元素速度快
添加
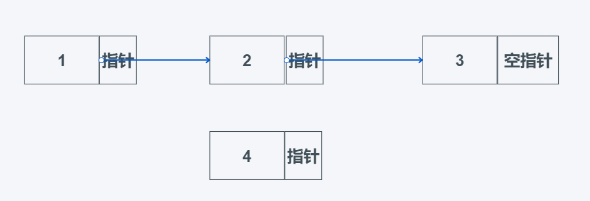
如下需要将4添加到1-2中间:
![image]()
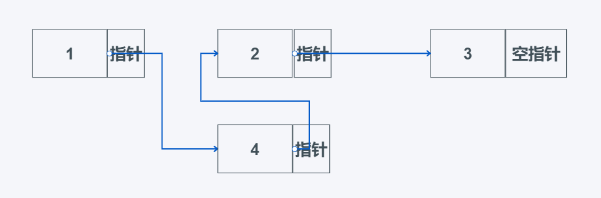
只需要将1的指针指向4的数据域,再将4的指针指向2的数据域即可。详细如下:
![image]()
删除
还是上述的链表图,需要将2删除,只需将1的指针指向3的数据域,详细如下:
![image]()
- 查找速度慢
因为是元素一个接着一个,因此查找前面的元素还好,但是如果是最后一个元素的话,则需要遍历整个链表。
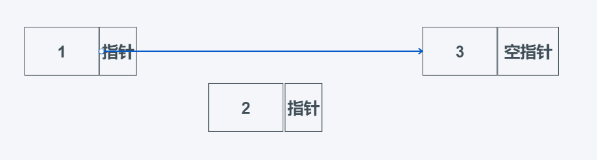
栈(stack)
栈是很多数据的集合,支持一端添加或者删除元素的线性表或者说是容器,与此很相似的现实中的常见便是放置盘子时从下往上一个螺着一个放,但是拿盘子时需要从上往下依次去拿,这也就是栈的一个特性先进后出,也可以说是后进先出。
在性能上,当需要对栈的靠前面的元素进行操作是,性能较差,因为需要操作从后到所需元素的所有元素移动,比较适合直接在末尾进行操作。
python的内置栈
其实python内置的列表和栈有着相似之处,例如只能从一端(右端)进行数据的增删;因此列表适合在末尾进行操作,否则性能会稍差,需要移动元素。
列表是基于动态数组创建的,当列表中进行元素的增删时,会创建新的内存空间,将元素迁移``复制过去,然后销毁原有的内存空间,较为耗时。
动态数组
优点:支持随机存取,时间复杂度为O(1)
缺点:虽然动态数组克服了静态数组容量固定的缺点,可以进行扩容,但是扩容的过程要拷贝整个数组,效率不高。另外在头部插入和删除元素需要移动大量的元素,时间复杂度为O(n).
python的双向队列(栈)
collections.deque是python内置的双向队列,可以选择从两边进行操作,由于其基于双向链表实现,因此他的添加、删除性能出色,复杂度为o(1);但访问元素的性能就显得差了些,尤其是查找靠中间的元素,复杂度为o(n)。
from collections import deque
from typing import Iterable
d = deque(maxlen=5)
for i in range(4):
d.append(i)
d.appendleft(5)
print(d)
print(isinstance(d, Iterable))
d.append(10)
print(d)
d.pop()
d.popleft()
print(d)
deque([5, 0, 1, 2, 3], maxlen=5)
True
deque([0, 1, 2, 3, 10], maxlen=5)
deque([1, 2, 3], maxlen=5)
由上述结果可知,deque返回的对象是可迭代对象,并且当设置了最大长度时,添加元素时超过最大长度时会将前面的元素给移除。
堆
由百度百科可知,堆是一种特殊的数据结构,是最高效的优先级队列,可以看作是一个完全二叉树的数据对象。
那么什么是完全二叉树呢?
- 一棵深度为k且有2k次方 - 1 个结点的二叉树称为满二叉树。
- 根据二叉树的性质2, 满二叉树每一层的结点个数都达到了最大值, 即满二叉树的第i层上有 个结点 (i≥1) 。
- 如果对满二叉树的结点进行编号, 约定编号从根结点起, 自上而下, 自左而右。则深度为k的, 有n个结点的二叉树, 当且仅当其每一个结点都与深度为k的满二叉树中编号从1至n的结点一一对应时, 称之为完全二叉树。
- 从满二叉树和完全二叉树的定义可以看出, 满二叉树是完全二叉树的特殊形态, 即如果一棵二叉树是满二叉树, 则它必定是完全二叉树。
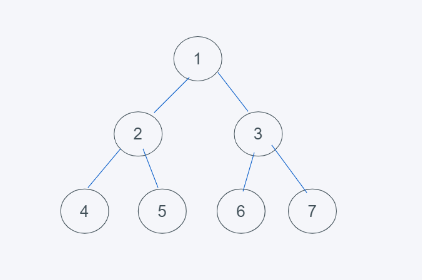
如下是满二叉树
![image]()
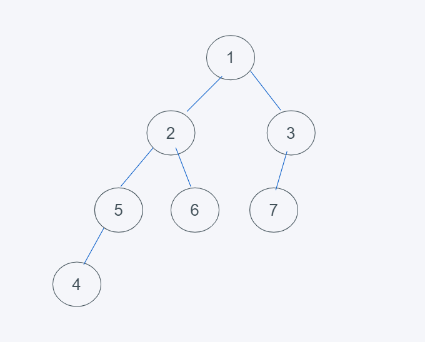
如下则是完全二叉树
![image]()
由此可以总结出,完全二叉树的概念,当一个深度为k的二叉树,自上而下,自左向右依次都有对应的元素,且不需要子节点数完全满子节点,只需要保证自上而下、自左向右均存在子节点即可。
堆的特性
- 堆中某个结点的值总是不小于其父结点的值;
- 堆总是一棵完全二叉树。
堆的特性判断
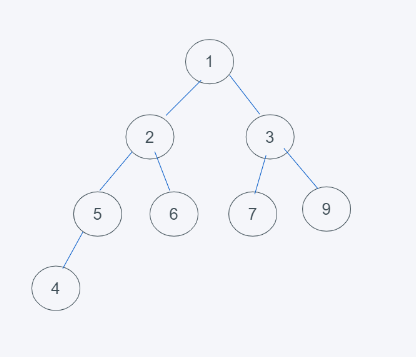
如下有几个堆,判断是否是堆?
如下图,不是堆,因为它不满足完全二叉树并且子节点元素存在不一致
如下图,不是堆,虽然是完全二叉树,但是不满足根节点元素均小于子节点元素
如下图,不是堆,既不是完全二叉树,也不满足根节点元素小于节点元素
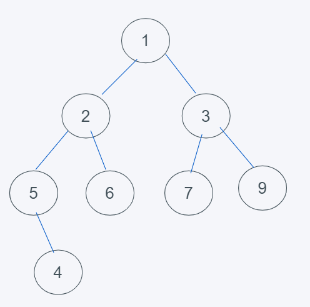
如下图,不是堆,是完全二叉树,但不满足根节点元素小于节点元素
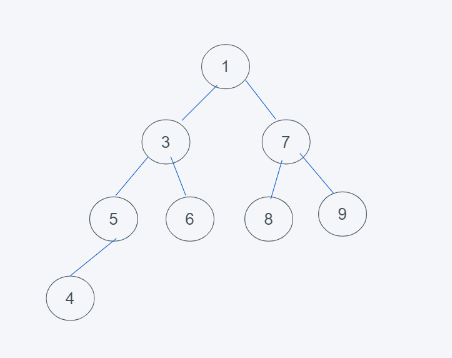
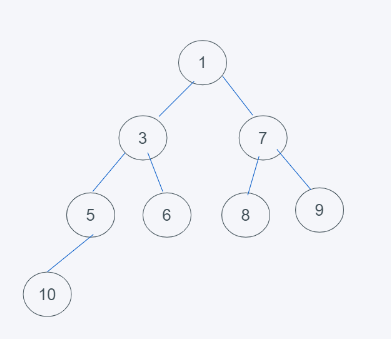
如下图,满足完全二叉树和根节点小于节点元素要求
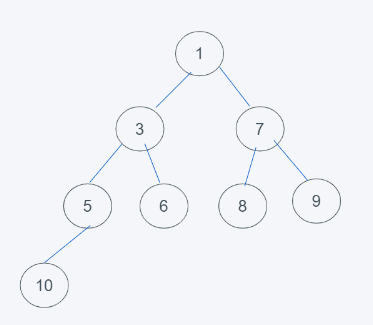
总结,需要是堆的话,需要是完全二叉树,并且根节点与子节点之间的关系必须满足大于等于或者小于等于。
大顶堆
当一个堆,根节点的值均大于两个子节点的值,则称此堆为最大堆,如下:
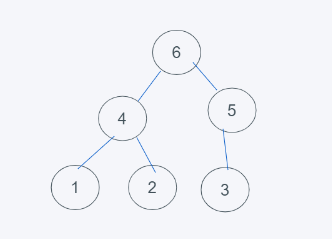
由于根节点都大于子节点,因此最上层的根节点将是最大值。
小顶堆
当一个堆,根节点均小于两个子节点的值,则称此堆为最小堆,如下:
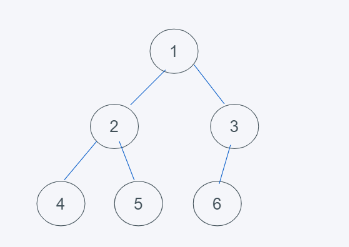
由于根节点都小于子节点,因此最上层的根节点将是最小值。
堆的元素的表示
此处以如下堆为示例,表示方法为从上到下、从左到右,此处的表示为[6, 4, 5, 1, 2, 3]
堆中元素的添加与删除
添加元素
如图,需要将4添加至堆中:
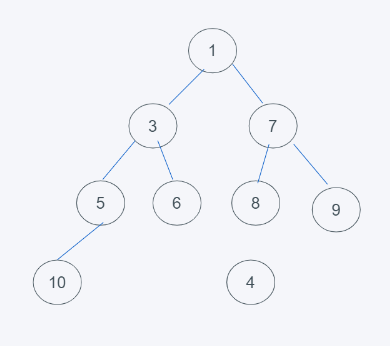
1.首先将4添加至堆的末尾
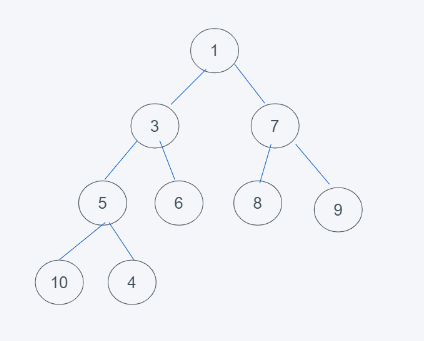
2.由于本堆是子节点元素都大于根节点元素,因此4不大于5,将4与5进行调换,如下
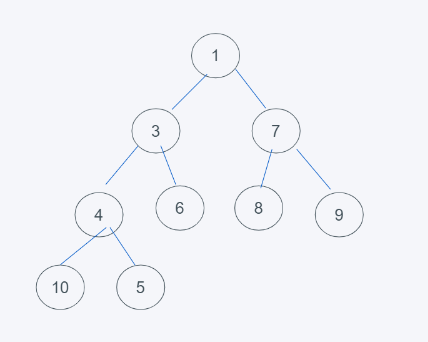
3.由此可见,5大于4并且4大于3,插入完毕,以此类推。
步骤总结就是,依据完全二叉树的定义插入到末尾,依据堆的整体特性进行大小比较位置调换即可。
删除元素
此处以上述插入元素后的堆为例,删除一般删除的都是堆顶元素,那就是1.
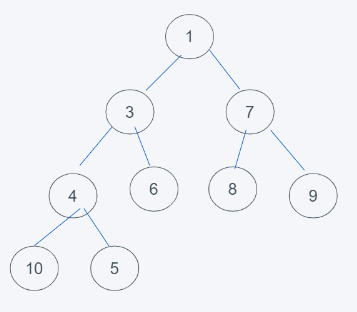
1.当堆顶元素删除后,使用末尾元素顶替,就是5.
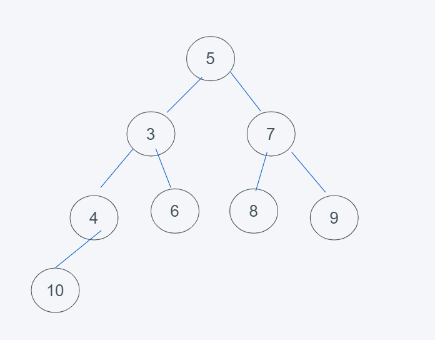
2.由于堆是根节点小于子节点,因此5与3进行调换
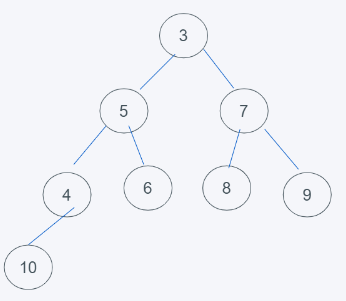
3.调换完成后,发现符合堆的要求了,删除结束。
总结,删除一般都是堆顶元素,删除完成后一般使用末尾元素进行替代,然后依据堆的性质进行调换即可。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号