常见排序梳理及实现
简介
本文将介绍常见的排序算法的思路及使用python代码去实现排序。
常用的术语
稳定
如果a原本在b前面,而a=b,排序之后a仍然在b的前面
不稳定
如果a原本在b的前面,而a=b,排序之后a可能会出现在b的后面
时间复杂度
一个算法执行所耗费的时间,正常来说就是每行代码执行的次数之和
for循环一般为 n,有几重循环就是指数级的循环
普通代码则为 1
while 则为 log n
空间复杂度
运行程序所需要的内存大小
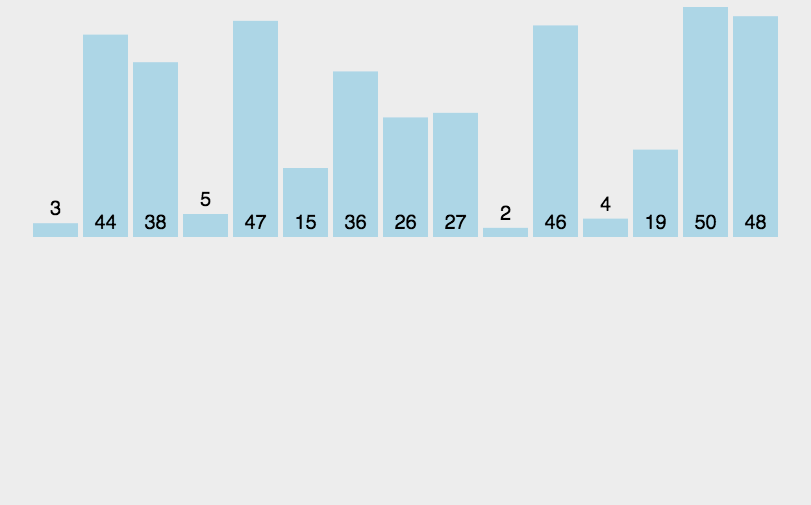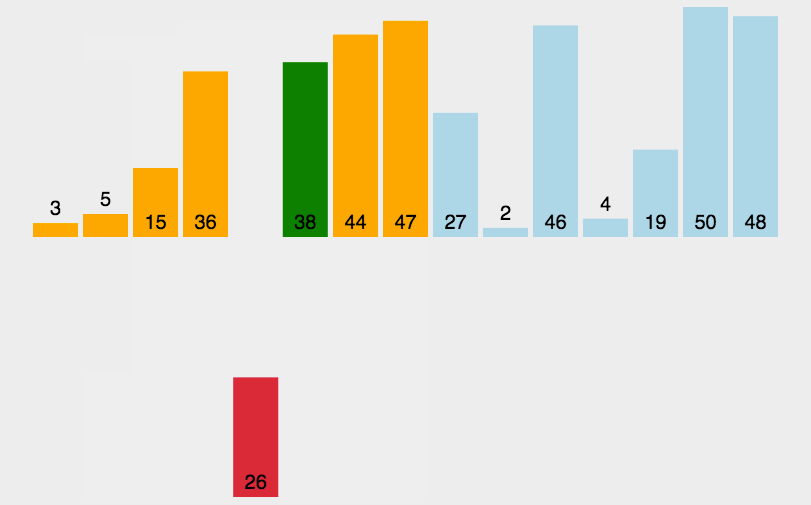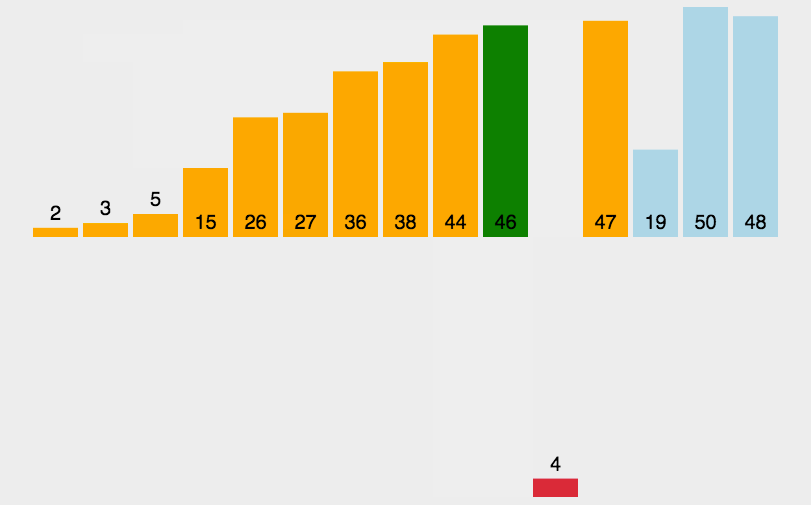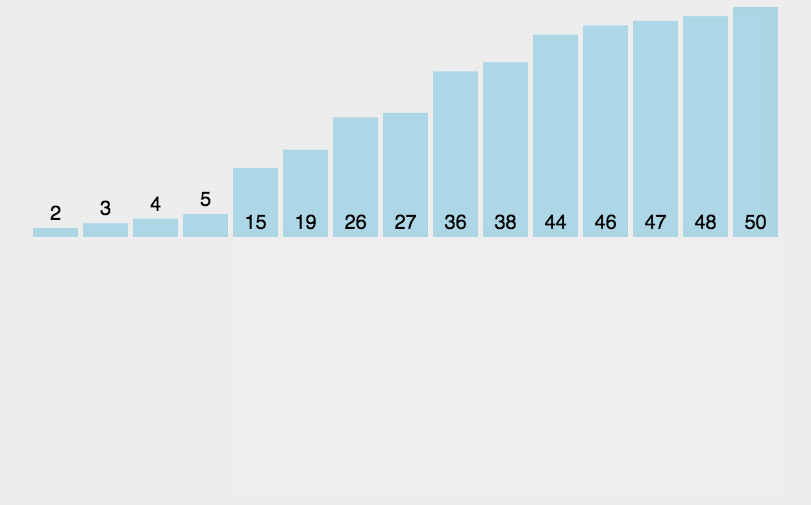
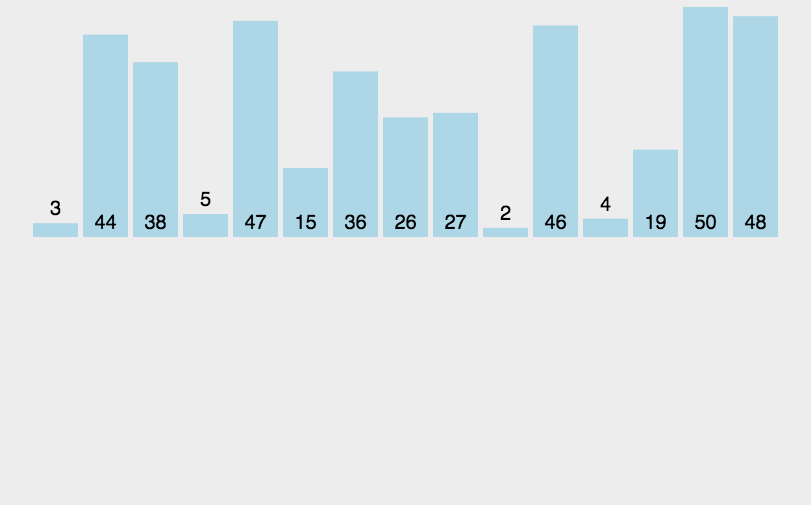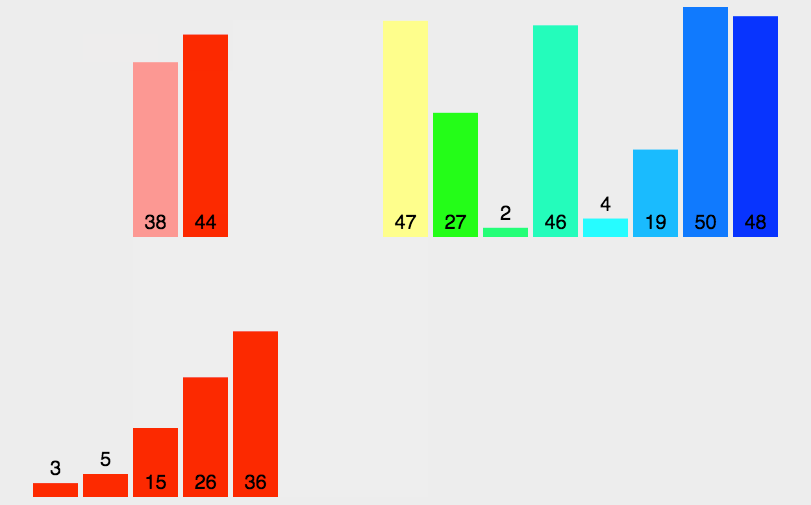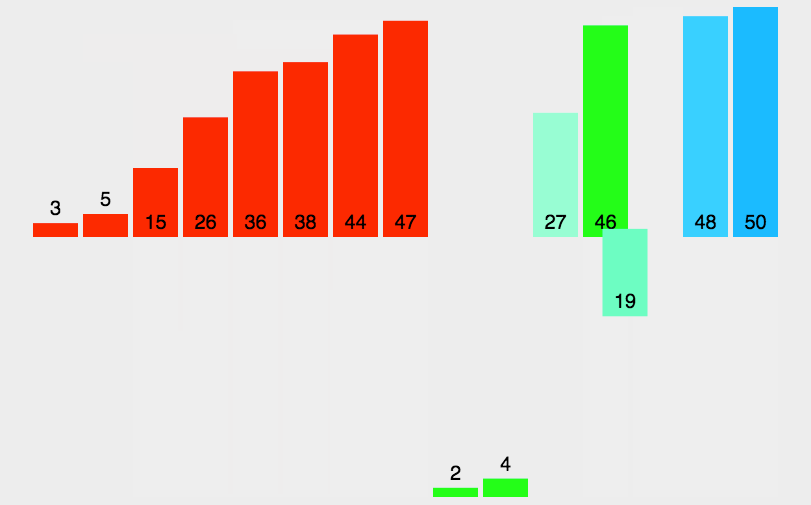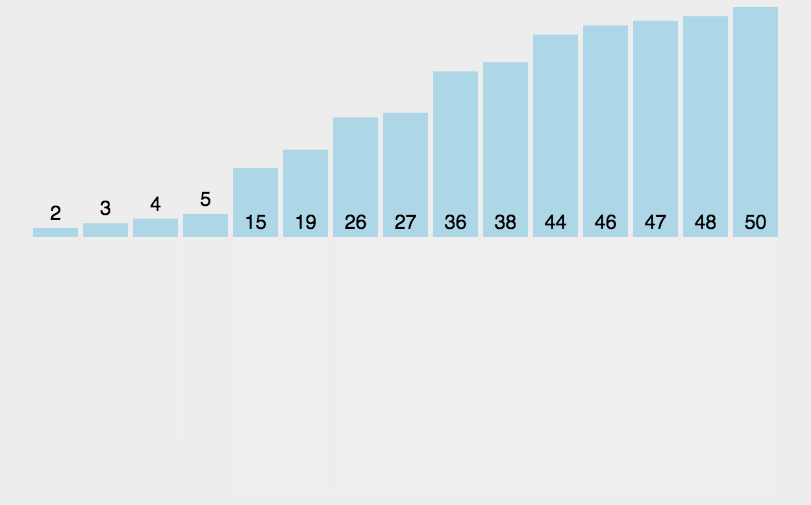
需要排序的数据
data = [3, 44, 38, 5, 47, 15, 36, 26, 27, 2, 46, 4, 19, 50, 48]
冒泡排序
描述:从头到尾依次比较相邻的两个元素,大的放后面,小的放前面,这样就能帮忙最大的在最后面,以此类推,因此需要(n-1)!次比较。动图如下:
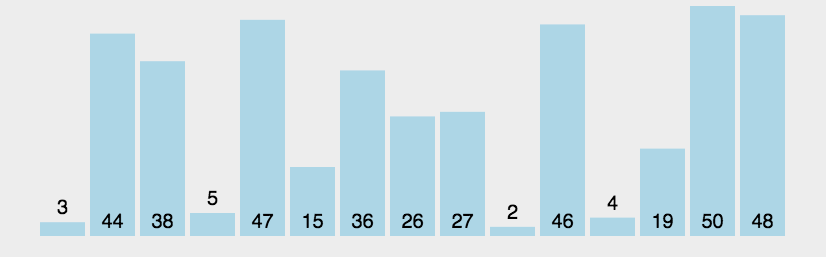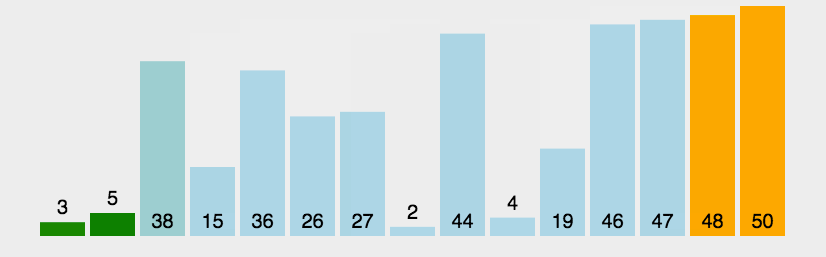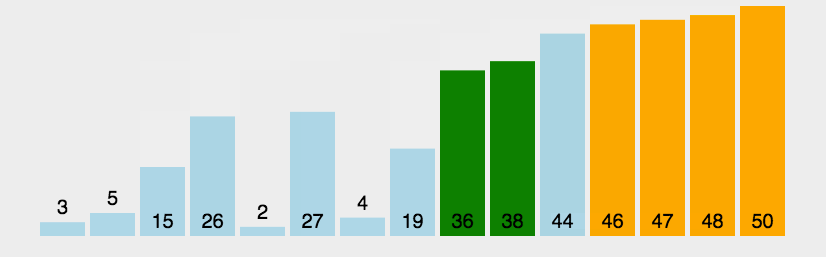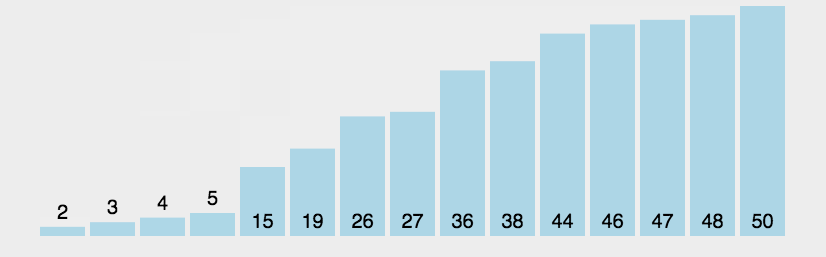
代码实现
def maopao(data):
data_len = len(data)
for j in range(data_len):
for i in range(1, data_len):
if data[i - 1] > data[i]:
data[i - 1], data[i] = data[i], data[i - 1]
return data
时间复杂度
1.最好情况,所有元素默认都是有序的,则只需要一次for循环遍历即可,为o(n)
2.最坏情况,所有元素都是无序的,每次都需要交换,需要进行两次for循环遍历,为o(n2)
3.平均为o(n2)
选择排序
描述:将序列分为有序和无序两个区域,每次从无序区域依次遍历选择最小的元素放置于有序区域的前面,这样就能保证有序区域前面都是最小的,以此类推。
代码实现
def xuanze(data):
data_len = len(data)
for i in range(data_len):
min_data = data[i]
min_index = i
for j in range(i, data_len):
if data[j] < min_data:
min_data = data[j]
min_index = j
data[i], data[min_index] = data[min_index], data[i]
return data
时间复杂度
1.由于选择排序在选择最小元素时都需要依次遍历序列,次数为n * (n-1) * (n-2)...1,即为n!,为(n-1) * n /2,即时间复杂度为o(n2),最好、最坏、平均时间复杂度为o(n2)
直接插入排序
描述:默认将第一个元素视为已排序,后续元素依次与前面已排序的元素(从后向前)进行比较,放置于大小合适的位置,每次排序完,前面的元素都是已排序好的状态, 直接插入排序,相当于就是两两比较,相互替换,和冒泡排序类似,不过是在有序的元素中进行排序,不需要进行多次比较。
代码
def charu(data):
data_len = len(data)
# 后面待排序的元素
for i in range(1, data_len):
# 前面已经排序好的元素, 从后向前排序
for j in range(i-1, -1, -1):
if data[i] < data[j]:
data[j], data[i] = data[i], data[j]
i = j
return data
时间复杂度
1.最坏情况,每次无序元素都需要与前面有序元素进行比较,代码执行次数为(n-1) * (n-2) * (n-3) ...1, 为n * n /2 时间复杂度为o(n2).
2.最好情况,每次无需元素进行一次比较后即可有序,代码执行次数为n-1, 时间复杂度为o(n)
3.综上,平均复杂度为o(n2)
希尔排序
描述:将需要排序的元素,按照一定的增量因子分成不同的组,例如10个元素按照增量因子(gap/2)分为5组,需要注意的是,分完组后的元素遵循最大间隔,即第一个元素和第六个元素为一组,第二个元素与第七个元素为一组,依次类推,当一次分完组后,对每组进行直接插入排序,继续缩小增量因子,当增量因子(gap/2)为1时,算法终止。
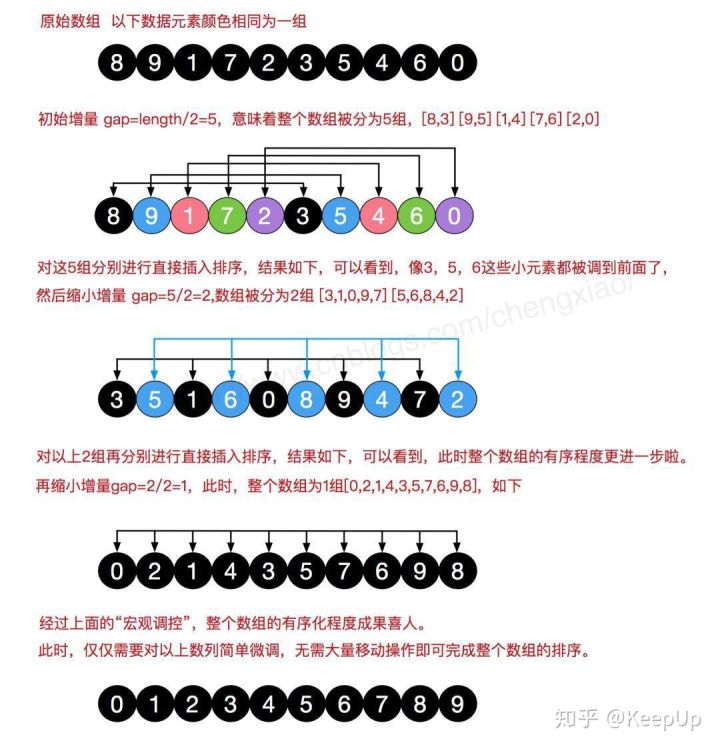
代码实现
def xier(data):
data_len = len(data)
group = int(data_len / 2)
while group > 0:
# 根据增量因子遍历最小集,依次叠加增量因子进行判断
for i in range(group):
# 获取增量因子分成的组
for j in range(i, data_len - group, group):
# 进行插入排序,需要注意的是当前面数据大于后面数据时,
# 还需要比较后面数据与前前面数据的,以此类推
while data[j] > data[j + group]:
data[j], data[j + group] = data[j + group], data[j]
if j > group - 1:
j -= group
group = int(group / 2)
return data
时间复杂度
由于必须要对增量因子做处理,由代码看出,无论最好还是最佳,都需要遍历分组集,因此时间复杂度为nlog2nn
归并排序
描述:与选择排序类似,采用分治法,把长度为n的输入序列分成两个长度为n/2的子序列;对这两个子序列分别采用归并排序;将两个排序好的子序列合并成一个最终的排序序列。
代码实现
快速排序
描述:也是采用分治法,选择一个基准元素,比它大的元素放在基准元素的后面,比它小的元素放在基准元素的前面。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号