第三次作业
-
作业①:
-
要求:指定一个网站,爬取这个网站中的所有的所有图片,例如中国气象网(http://www.weather.com.cn)。分别使用单线程和多线程的方式爬取。
-
输出信息:
将下载的Url信息在控制台输出,并将下载的图片存储在images子文件中,并给出截图。
-
代码实现(单线程):
from bs4 import BeautifulSoup from bs4 import UnicodeDammit import urllib.request def imageSpider(start_url): try: urls=[] req=urllib.request.Request(start_url,headers=headers) data=urllib.request.urlopen(req) data=data.read() dammit = UnicodeDammit(data, ["utf-8", "gbk"]) data = dammit.unicode_markup soup = BeautifulSoup(data, "lxml") images = soup.select("img") for image in images: try: src = image["src"] url = urllib.request.urljoin(start_url, src) if url not in urls: urls.append(url) print(url) download(url) except Exception as err: print(err) except Exception as err: print(err) def download(url): global count try: count=count+1 # 提取文件后缀扩展名 if (url[len(url) - 4] == "."): ext = url[len(url) - 4:] else: ext = "" req = urllib.request.Request(url,headers=headers) data = urllib.request.urlopen(req, timeout=100) data = data.read() fobj = open("images\\" + str(count) + ext, "wb") fobj.write(data) fobj.close() print("downloaded " + str(count) + ext) except Exception as err: print(err) start_url="http://www.weather.com.cn/weather/101280601.shtml" headers = {"User-Agent": "Mozilla/5.0 (Windows; U; Windows NT 6.0 x64; en-US; rv:1.9pre) Gecko/2008072421 Minefield/3.0.2pre"} count=0 imageSpider(start_url)
实验结果(单线程):

代码实现(多线程):
from bs4 import BeautifulSoup from bs4 import UnicodeDammit import urllib.request import threading def imageSpider(start_url): global threads global count try: urls = [] req = urllib.request.Request(start_url, headers=headers) data = urllib.request.urlopen(req) data = data.read() dammit = UnicodeDammit(data, ["utf-8", "gbk"]) data = dammit.unicode_markup soup = BeautifulSoup(data, "lxml") images1 = soup.select("img") for image in images1: try: src = image["src"] url = urllib.request.urljoin(start_url, src) if url not in urls: urls.append(url) print(url) count = count + 1 T = threading.Thread(target=download, args=(url, count)) T.setDaemon(False) T.start() threads.append(T) except Exception as err: print(err) except Exception as err: print(err) def download(url, count): try: if (url[len(url)-4] == "."): ext = url[len(url)-4:] else: ext = "" req = urllib.request.Request(url, headers=headers) data = urllib.request.urlopen(req, timeout=100) data = data.read() fobj = open("images\\" + str(count) + ext, "wb") fobj.write(data) fobj.close() print("downloaded " + str(count) + ext) except Exception as err: print(err) start_url = "http://www.weather.com.cn/weather/101280601.shtml" headers = {"User-Agent": "Mozilla/5.0 (Windows; U; Windows NT 6.0 x64; en-US;rv:1.9pre) Gecko/2008072421 Minefield/3.0.2pre"} count = 0 threads = [] imageSpider(start_url) for t in threads: t.join() print("the End")
实验结果(多线程):
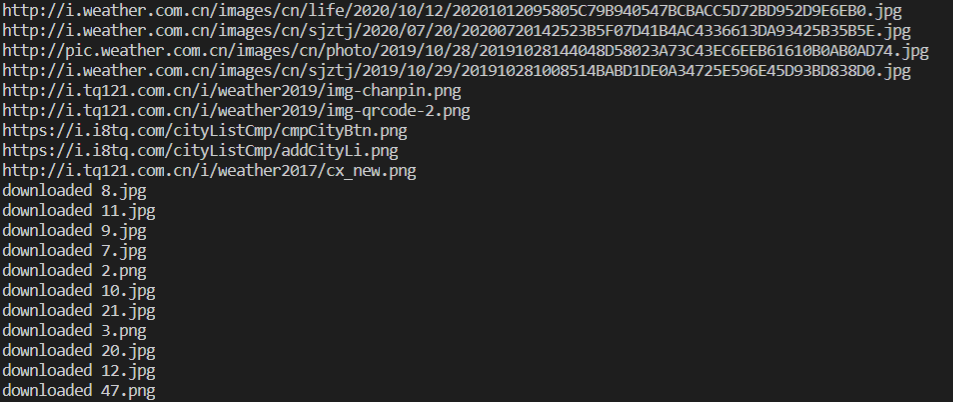
心得体会:
通过单线程和多线程的爬取,理解了两者之间的区别,下载进程的运行顺序和运行时间的差别。
-
作业②
-
要求:使用scrapy框架复现作业①。
-
输出信息:
同作业①
-
代码实现(单线程):
MySpider.py:
import scrapy from ..items import PictureItem class MySpider(scrapy.Spider): name = 'mySpider' start_url = ["http://www.weather.com.cn/weather/101280601.shtml"] def parse(self,response): data = response.body.decode() selector = scrapy.Selector(text=data) srcs=selector.xpath("//img/@src").extract() for src in srcs: item = PictureItem() item["src"] = src yield item
items.py:
import scrapy class PictureItem(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() pic = scrapy.Field()
piplines.py:
from itemadapter import ItemAdapter from bs4 import BeautifulSoup from bs4 import UnicodeDammit import urllib.request class PicPipeline: count = 0 def process_item(self, item, spider):#download下载并计数 count = count+1 url = item["src"] if (url[len(url) - 4] == "."): ext = url[len(url) - 4:] else: ext = "" req = urllib.request.Request(url) data = urllib.request.urlopen(req, timeout=100) data = data.read() fobj = open("C:/example/demo/demo/images/" + str(PicPipeline.count) + ext, "wb") fobj.write(data) fobj.close() print("downloaded " + str(count) + ext)
return item
setting.py:
BOT_NAME = 'demo'
SPIDER_MODULES = ['demo.spiders'] NEWSPIDER_MODULE = 'demo.spiders' ROBOTSTXT_OBEY = True
#前半部分在创建项目时自动生成
ITEM_PIPELINES = {
'demo.pipelines.PicPipeline': 300, # 管道传输
}
run.py:
from scrapy import cmdline cmdline.execute("scrapy crawl mySpider -s LOG_ENABLED=False".split())
实验结果:
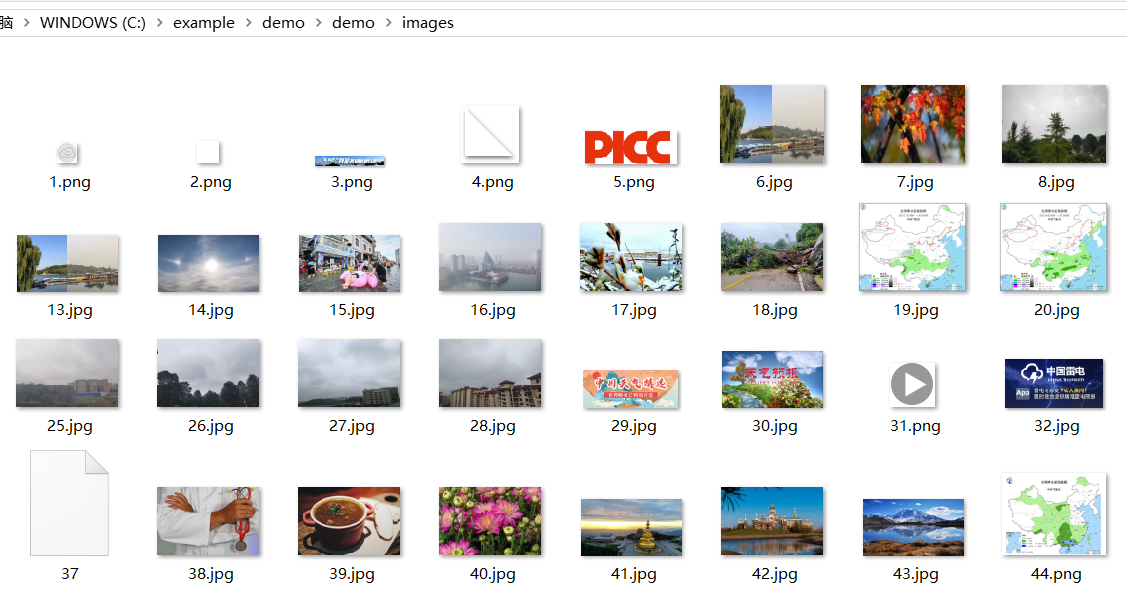
心得体会:
通过运用scrapy框架进行复现,,对比于单线程的实现过程,了解到各个模块的作用,以及各模块之间的关系
-
作业③:
-
要求:使用scrapy框架爬取股票相关信息。
-
候选网站:东方财富网:https://www.eastmoney.com/
-
输出信息:
序号 股票代码 股票名称 最新报价 涨跌幅 涨跌额 成交量 成交额 振幅 最高 最低 今开 昨收 1 688093 N世华 28.47 62.22% 10.92 26.13万 7.6亿 22.34 32.0 28.08 30.2 17.55 2......
-
实现代码:
MySpider.py
import scrapy from ..items import GPItem import re class MySpider(scrapy.Spider): name = 'mySpider'start_urls=["http://73.push2.eastmoney.com/api/qt/clist/get?&pn=1&pz=20&po=1&np=1&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt=2&invt=2&fid=f3&fs=m:1+t:2,m:1+t:23&fields=f2,f3,f4,f5,f6,f7,f12,f13,f14,f15,f16,f17,f18&_=1602901412583%20Request%20Method:%20GET"] #{"f2":14.11,"f3":38.74,"f4":3.94,"f5":1503670,"f6":2115845584.0,"f7":23.99,"f12":"601568","f13":1,"f14":"N北元","f15":14.64,"f16":12.2,"f17":12.2,"f18":10.17} def parse(self,response): data = response.text pat = '"diff":\[\{(.*?)\}\]' data_t = re.compile(pat, re.S).findall(data) datas = data_t[0].strip("{").strip("}").split('},{') print("序号\t\t代码\t\t名称\t\t最新价\t\t涨跌幅\t跌涨额\t\t成交量\t\t成交额\t\t涨幅\t\t最高价\t\t最低价\t\t今开\t\t昨开") for i in range(len(datas)): item = GPItem() datab = data[i].replace('"', "").split(',')#获取第i条数据中的各个元素 item["count"] = str(i) item['code'] = datab[6].split(":")[1] item['name'] = datab[8].split(":")[1] item['new_pr'] = datab[0].split(":")[1] item['rd_ran'] = datab[1].split(":")[1] item['rd_pr'] = datab[2].split(":")[1] item['deal_n'] = datab[3].split(":")[1] item['deal_pr'] = datab[4].split(":")[1] item['rdp'] = datab[5].split(":")[1] item['new_hpr'] = datab[9].split(":")[1] item['new_lpr'] = datab[10].split(":")[1] item['to_op'] = datab[11].split(":")[1] item['yes_op'] = datab[12].split(":")[1] yield item
items.py:
import scrapy class GPItem(scrapy.Item):
count = scrapy.Field() code = scrapy.Field() name = scrapy.Field() new_pr = scrapy.Field() rd_ran = scrapy.Field() rd_pr = scrapy.Field() deal_n = scrapy.Field() deal_pr = scrapy.Field() rpd = scrapy.Field() zf = scrapy.Field() new_hpr = scrapy.Field() new_lpr = scrapy.Field() to_op = scrapy.Field() yes_op = scrapy.Field()
piplines.py;
from itemadapter import ItemAdapter class GPPipeline: def process_item(self, item, spider): print(item["count"]+ '\t' + item['code']+ '\t' + item['name'] + '\t' + item['new_pr']+ '\t' + item['rd_ran']+ '\t' + item['rd_pr']+ '\t' + item['deal_n']+ '\t' + item['deal_pr']+ '\t' + item['rdp']+ '\t' + item['new_hpr']+ '\t' + item['new_lpr']+ '\t' + item['to_op']+ '\t' + item['yes_op'] return item
settings:
BOT_NAME = 'demo' SPIDER_MODULES = ['demo.spiders'] NEWSPIDER_MODULE = 'demo.spiders' # Crawl responsibly by identifying yourself (and your website) on the user-agent #USER_AGENT = 'demo (+http://www.yourdomain.com)' # Obey robots.txt rules ROBOTSTXT_OBEY = True ITEM_PIPELINES = { 'demo.pipelines.GPPipeline': 300,# 管道传输 }
实验结果:

心得体会:
这个实验与作业2的相似,通过更改一些实现和参数而实现,但开始在信息截选获取时出现了些差错

