第二次作业
-
作业①:
-
要求:在中国气象网(http://www.weather.com.cn)给定城市集的7日天气预报,并保存在数据库。
-
输出信息:
序号 地区 日期 天气信息 温度 1 北京 7日(今天) 晴间多云,北部山区有阵雨或雷阵雨转晴转多云 31℃/17℃ 2 北京 8日(明天) 多云转晴,北部地区有分散阵雨或雷阵雨转晴 34℃/20℃ 3 北京 9日(后台) 晴转多云 36℃/22℃ 4 北京 10日(周六) 阴转阵雨 30℃/19℃ 5 北京 11日(周日) 阵雨 27℃/18℃ 6......
实现代码:
from bs4 import BeautifulSoup from bs4 import UnicodeDammit import urllib.request import sqlite3 class weatherDB: def openDB(self): self.con = sqlite3.connect("weather.db") self.cursor = self.con.cursor() try: self.cursor.execute( "create table weathers (wcity varchar(16),wdate varchar(16),wweather varchar(64),wtemp varchar(32),constraint pk_weather primary key(wcity,wdate))") except: self.cursor.execute("delete from weathers") def closeDB(self): self.con.commit() self.con.close() def insert(self, city, date, weather, temp): try: self.cursor.execute("insert into weathers (wcity,wdate,wweather,wtemp) values(?,?,?,?)", (city, date, weather, temp)) except: print("err") def show(self): self.cursor.execute("select * from weathers") rows = self.cursor.fetchall() print("%-16s%-16s%-32s%-16s" % ("city", "date", "weather", "temp")) for row in rows: print("%-16s%-16s%-32s%-16s" % (row[0], row[1], row[2], row[3])) class weatherforecast(): def __init__(self): self.headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) " "Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3775.400 QQBrowser/10.6.4209.400"} self.citycode = {"北京": "101010100", "上海": "101020100", "广州": "101280101", "深圳": "101280601"} def forecastcity(self, city): if city not in self.citycode.keys(): print(city + "code not found") return url = "http://www.weather.com.cn/weather/" + self.citycode[city] + ".shtml" try: req = urllib.request.Request(url, headers=self.headers) data = urllib.request.urlopen(req) data = data.read() dammit = UnicodeDammit(data, ["utf-8", "gbk"]) data = dammit.unicode_markup soup = BeautifulSoup(data, 'html.parser') lis = soup.select("ul[class='t clearfix'] li") for li in lis: try: date_ = li.select('h1')[0].text weather_ = li.select('p[class="wea"]')[0].text temp_ = li.select('p[class="tem"] span')[0].text + '℃/' + li.select("p[class='tem'] i")[0].text print(city, date_, weather_, temp_) self.db.insert(city, date_, weather_, temp_) except: print('err1') except: print('err2') def precess(self, cities): self.db = weatherDB() self.db.openDB() for city in cities: self.forecastcity(city) self.db.show() self.db.closeDB() ws = weatherforecast() ws.precess(["北京", '上海', '广州', '深圳']) print('finish')
实验结果;
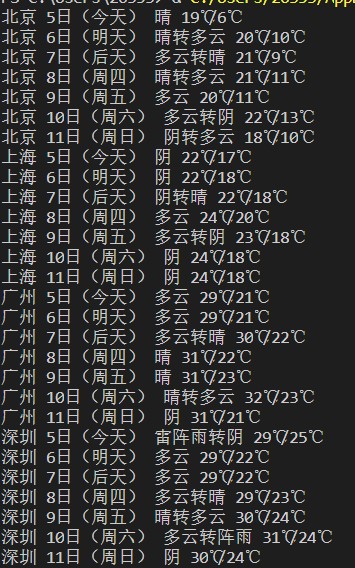
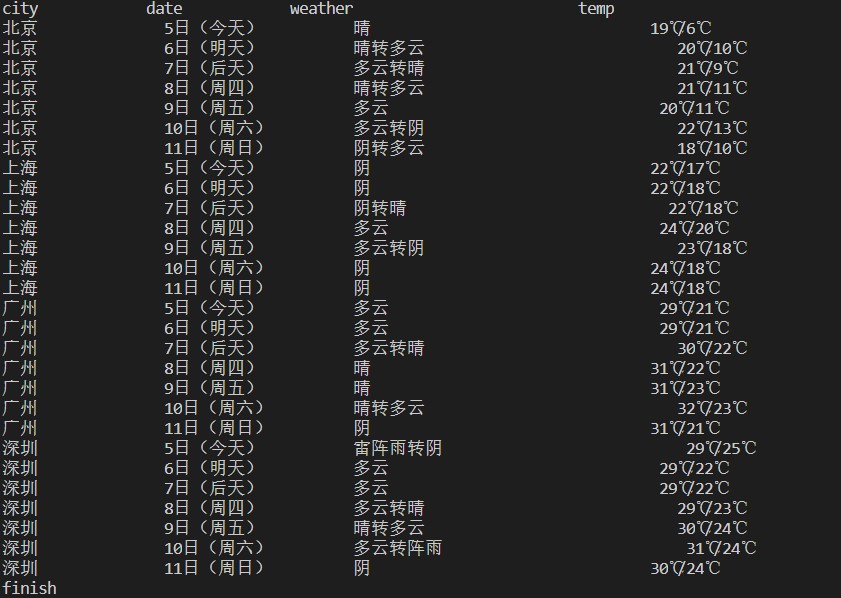
其中数据库中原有的数据:
心得体会:
这个实验的代码是源自书上的。在抄写的过程中一步一步地理解,了解各个函数的用法和参数意义。而在抄写的过程中,发现了一些格式上的问题,通过修改最终而有以上结果。
作业②
-
要求:用requests和BeautifulSoup库方法定向爬取股票相关信息。
-
候选网站:东方财富网:https://www.eastmoney.com/
-
技巧:在谷歌浏览器中进入F12调试模式进行抓包,查找股票列表加载使用的url,并分析api返回的值,并根据所要求的参数可适当更改api的请求参数。根据URL可观察请求的参数f1、f2可获取不同的数值,根据情况可删减请求的参数。
-
输出信息:
| 序号 | 股票代码 | 股票名称 | 最新报价 | 涨跌幅 | 涨跌额 | 成交量 | 成交额 | 振幅 | 最高 | 最低 | 今开 | 昨收 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 688093 | N世华 | 28.47 | 62.22% | 10.92 | 26.13万 | 7.6亿 | 22.34 | 32.0 | 28.08 | 30.2 | 17.55 |
| 2...... |
实现代码:
import bs4 import requests import re from bs4 import BeautifulSoup headers = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3775.400 QQBrowser/10.6.4205.400"} def get_html_data(pn,fs):#pn:页码,fs:股票名号 url = "http://57.push2.eastmoney.com/api/qt/clist/get?cb=jQuery1124023699367386040748_1601445755722&pn=" + str( pn) + "&pz=20&po=1&np=1&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt=2&invt=2&fid=f3&fs="+ fs +"&fields=f12,f14,f2,f3,f4,f5,f6,f7&_=1601445756033" #f12:代码,f14:名称,f2:最新价,f3:涨跌幅,f4:涨跌额,f5:成交量,f6:成交额,f7:涨幅 html = requests.get(url,headers=headers) data = re.findall(r'"diff":\[(.*?)]', html.text) return data #{"f2":28.47,"f3":62.22,"f4":10.92,"f5":261362,"f6":760131008.0,"f7":22.34,"f12":"688093","f14":"N世华"} def get_stocks_show(data): data = data[0].strip('{').strip('}').split('},{') stocks = [] ls = [0 for i in range(8)] print("序号" + "\t" + "代码" + "\t\t" + "名称" + "\t\t" + "最新价" + "\t\t" + "涨跌幅" + "\t\t" + "跌涨额" + "\t\t" + "成交量" + "\t\t" + "成交额" + "\t\t" + "涨幅") for i in range(len(data)): sto = data[i].replace('"', "").split(",") stocks.append(sto) for i in range(len(stocks)): for j in range(len(stocks[i])): stock = stocks[i][j].split(':')#f[i]_:[j]_ ls[j] = stock[1] print(str(i+1)+ '\t' + str(ls[6]) + '\t\t' + str(ls[7]) + '\t\t' + str(ls[0]) + '\t\t' + str(ls[1]) + '\t\t' + str(ls[2]) + '\t\t' + str(ls[3]) + '\t\t' + str(ls[4]) + '\t\t' + str(ls[5]) + '\n') def main(): fs = 'm:0+t:6,m:0+t:13,m:0+t:80,m:1+t:2,m:1+t:23'#沪深A股 pn_all = 2#查找2页 for pn in range(pn_all): print('开始打印第'+ str(pn+1) + '页') pn +=1 data = get_html_data(pn,fs) get_stocks_show(data) if __name__ == '__main__': main()
实验结果:
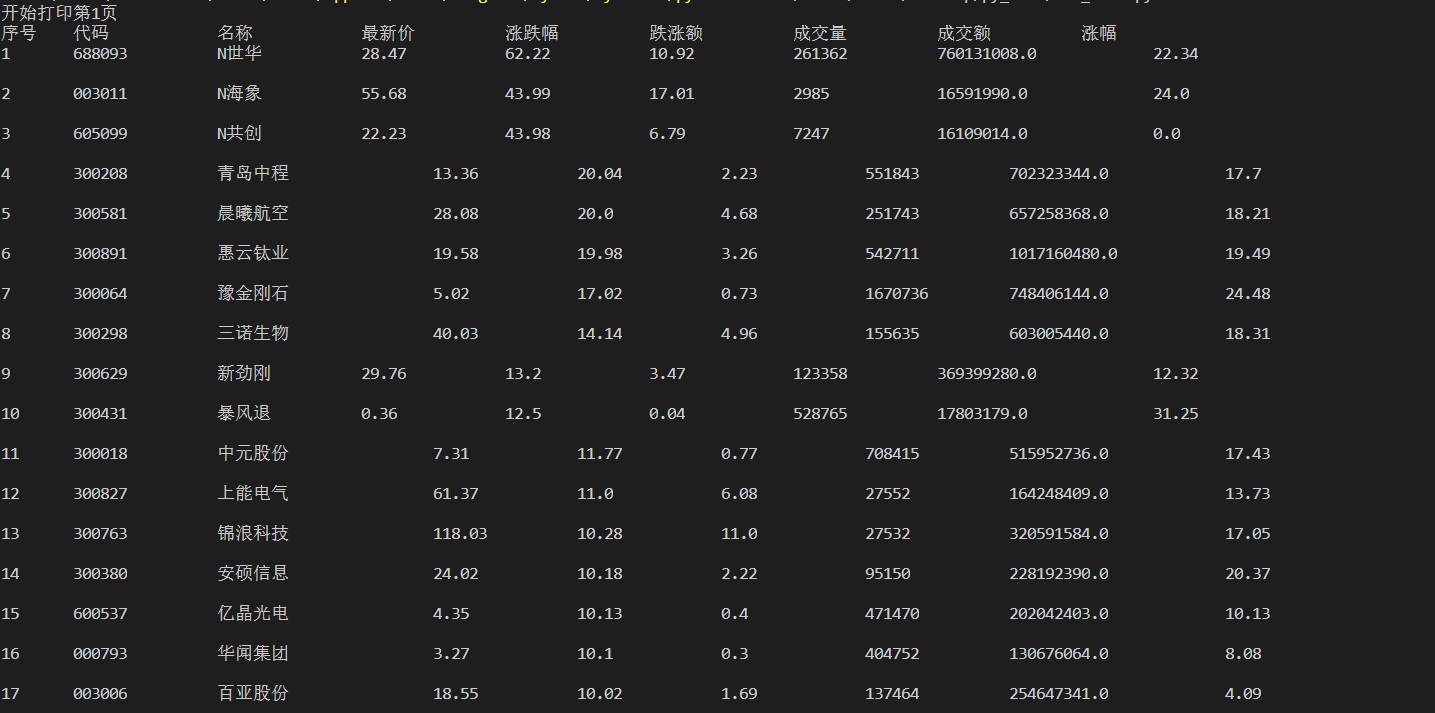
心得体会:
通过这次的实验了解到获取单页数据的过程,从对数据的提取中了解到js筛选后url不同参数的意义。
作业③: 加分题10分
-
要求:根据自选3位数+学号后3位选取股票,获取印股票信息。抓包方法同作②。
-
候选网站:东方财富网:https://www.eastmoney.com/
-
输出信息:
| 股票代码号 | 股票名称 | 今日开 | 今日最高 | 今日最低 |
|---|---|---|---|---|
| 605006 | 山东玻纤 | 9.04 | 8,58 | 8.13 |
实现代码:
import bs4 import requests import re from bs4 import BeautifulSoup headers = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3775.400 QQBrowser/10.6.4205.400"} def get_html_data(pn,fs):#pn:页码,fs:股票名号 url = "http://57.push2.eastmoney.com/api/qt/clist/get?cb=jQuery1124023699367386040748_1601445755722&pn=" + str( pn) + "&pz=20&po=1&np=1&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt=2&invt=2&fid=f3&fs="+ fs +"&fields=f12,f14,f15,f16,f17&_=1601445756033" #f12:股票代码,f14:股票名称,f15:最高,f16:最低,f17:今开 html = requests.get(url,headers=headers) data = re.findall(r'"diff":\[(.*?)]', html.text) return data #{"f12":"688093","f14":"N世华","f15":32.0,"f16":28.08,"f17":30.2} def get_stocks_show(data): data = data[0].strip('{').strip('}').split('},{') stocks = [] ls = [0 for i in range(8)] for i in range(len(data)): sto = data[i].replace('"', "").split(",") stocks.append(sto) for i in range(len(stocks)): for j in range(len(stocks[i])): stock = stocks[i][j].split(':')#f[i]_:[j]_ ls[j] = stock[1] if(str(ls[0]).endswith('228')): print(str(ls[0]) + '\t\t' + str(ls[1]) + '\t\t' + str(ls[4]) + '\t\t' + str(ls[2]) + '\t\t' + str(ls[3])) def main(): fs = 'm:0+t:6,m:0+t:13,m:0+t:80,m:1+t:2,m:1+t:23'#沪深A股 pn_all = 50#查找前50页中 print("代码" + "\t\t" + "名称" + "\t\t\t" + "今开" + "\t\t" + "最高" + "\t\t" + "最低") for pn in range(pn_all): pn +=1 data = get_html_data(pn,fs) get_stocks_show(data) if __name__ == '__main__': main()
实验结果:

心得体会:
第三个实验是在第二个基础上的修改(多了一个筛选条件),通过两次的实验了解到通过变换url中的参数值达到筛选的效果,得到需求的数据集和内容,方便爬虫的实现。

