第一次作业——结合三次小作业
作业①:
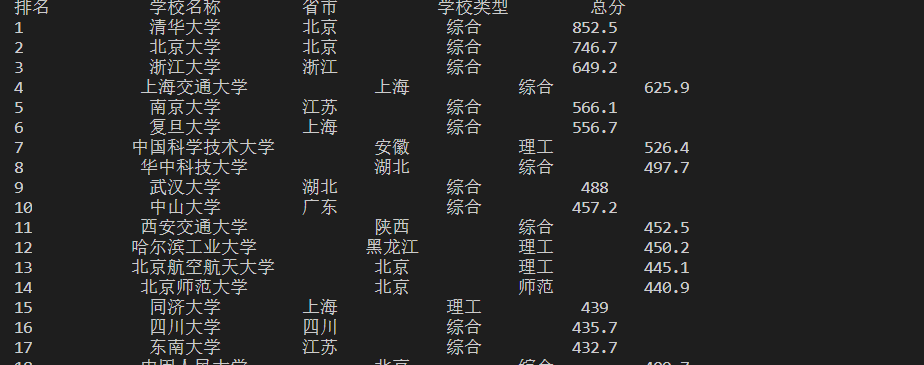
- 要求:用requests和BeautifulSoup库方法定向爬取给定网址(http://www.shanghairanking.cn/rankings/bcur/2020 )的数据,屏幕打印爬取的大学排名信息。
- 输出信息:
| 排名 | 学校名称 | 省市 | 学校类型 | 总分 |
|---|---|---|---|---|
| 1 | 清华大学 | 北京 | 综合 | 852.5 |
| 2...... |
实现代码:
import requests import bs4 from bs4 import BeautifulSoup url='http://www.shanghairanking.cn/rankings/bcur/2020' ls=[] r = requests.get(url) r.raise_for_status() r.encoding = r.apparent_encoding soup = BeautifulSoup(r.text, "html.parser") gro=soup.select('tbody tr') print('{0:^10}\t{1:^10}\t{2:^10}\t{3:^10}\t{4:^10}'.format('排名', '学校名称', '省市', '学校类型', '总分' )) for key in gro: if isinstance(key, bs4.element.Tag): tds = key('td') ls.append([tds[0].text.strip(), tds[1].text.strip(), tds[2].text.strip(), tds[3].text.strip(),tds[4].text.strip()]) for i in range(40): u=ls[i] print('{0:^10}\t{1:^10}\t{2:^10}\t{3:^10}\t{4:^10}'.format(u[0], u[1], u[2], u[3] , u[4]))
实验结果
心得体会:
第一次的爬虫实验,了解到了爬虫的基本实现过程和相关函数使用方法,但对爬取的数据的处理尚有不足。
作业②:
- 要求:用requests和re库方法设计某个商城(自已选择)商品比价定向爬虫,爬取该商城,以关键词“书包”搜索页面的数据,爬取商品名称和价格。
- 输出信息:
| 序号 | 价格 | 商品名 |
|---|---|---|
| 1 | 65.00 | xxx |
| 2...... |
实现代码:
import requests import re import bs4 from bs4 import BeautifulSoup headers = {"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.102 Safari/537.36 Edg/85.0.564.51"} url={"https://search.jd.com/Search?keyword=%E9%BC%A0%E6%A0%87&enc=utf-8&wq=%E9%BC%A0%E6%A0%87&pvid=b19a979767044334b9bc7391e8a29b8f"} try: r=requests.get(url,headers) r.encoding=r.apparent_encoding html =r.text except: print(" ") ls_title=[] ls_price=[] print("{0:^10}\t{1:^10}\t{2:^10}".format('序号','价格','商品名')) try: soup=BeautifulSoup(html,"html.parser") price=soup.select("div",{"class":"p-price"}) title=soup.select("div",{"class":"p-name p-name-type-2"}) for key in price: key=key.find("strong").find("i") ls_price.append(key.text ) for key in title: key=key.find("em") ls_title.append(key.text ) for i in range(len(ls_price)): print("{0:^10}\t{1:^10}\t{2:^10}".format(str(i),ls_title[i].strip(),ls_price[i].strip())) except: print(" ")
实验结果:

心得体会:
对深层次的数据爬取有了深一步的了解,同时对html的结构有了进一步的认识。
作业③:
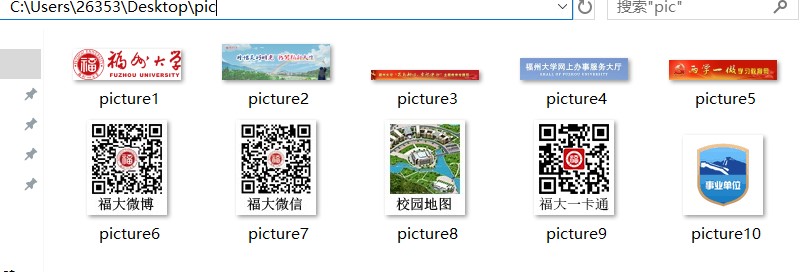
- 要求:爬取一个给定网页(http://xcb.fzu.edu.cn/html/2019ztjy)或者自选网页的所有JPG格式文件
- 输出信息:将自选网页内的所有jpg文件保存在一个文件夹中
实现代码:
import urllib.request import bs4 import re import requests import os from bs4 import BeautifulSoup url ="https://www.fzu.edu.cn/" headers ={"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.102 Safari/537.36 Edg/85.0.564.51"} path =r"C:\Users\26353\Desktop\pic" r = requests.get(url,headers=headers) r.raise_for_status r.encoding =r.apparent_encoding html = r.text soup =BeautifulSoup(html,"html.parser") pic_group=soup.select("img") pic_url =[] for key in pic_group: pic_url.append("https://www.fzu.edu.cn"+key["src"]) os.chdir(path) i=1 for key in pic_url: #if key.endswith(".jpg") #urllib.request.urlretrieve(key,"picture"+str(i)+".jpg") urllib.request.urlretrieve(key,"picture"+str(i)+key[-4:]) print("picture("+str(i)+")has been saved") i=i+1
实验结果:
心得体会:
通过对JPG图片的爬取,了解到爬取图片的前提下,区分不同类型图片的方式。通过查找资料也了解到如何对网页上的数据进行下载保存。

