第一次的博客编程作业
一.作业提交与作业链接
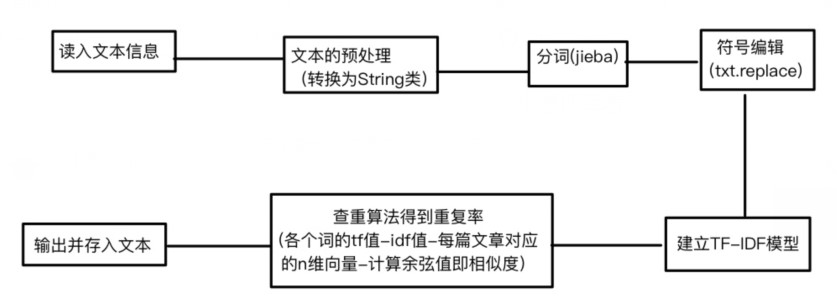
二.计算模块接口的设计与实现功能。
1.流程图
2.样例
原文示例:今天是星期天,天气晴,今天晚上我要去看电影。
抄袭示例:今天是周天,天气晴朗,我晚上要去看电影。
- 分词的实现(jieba.cut())
import jieba txt1='今天是星期天,天气晴,今天晚上我要去看电影' txt2='今天是周天,天气晴朗,我晚上要去看电影' all_txt=[] all_txt.append(txt1) all_txt.append(txt2) all_txt_list=[] for txt in all_txt: txt_list=[word for word in jieba.cut(txt)] all_txt_list.append(txt_list) for word in all_txt_list: print(word)
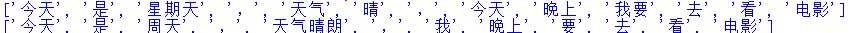
调用jieba库中的cut函数可以直接实现对String类的分词。
- TF-IDF模型的简介与实现
TF-IDF模型最常是被搜索引擎所用,作为文件与用户查询之间相关程度的度量或评级。而这通过对文本进行分词,求其每一个此的词频将一个句子或者文本转换为向量,以向量代表文本信息,求向量的相似度。
TF的实现过程(以余弦相似度为例):
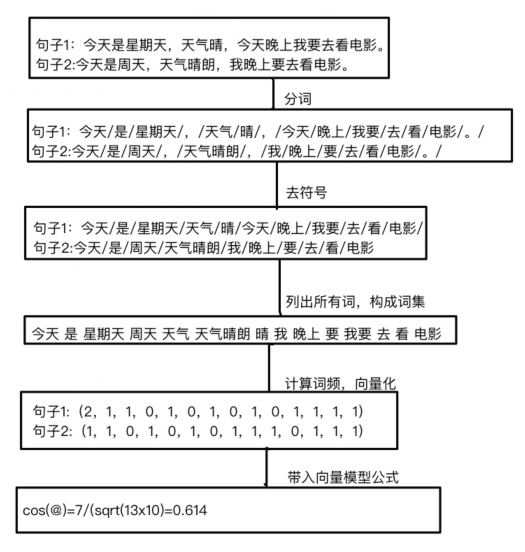
但在计算词频TF中会有“的,地,嗯”等一些对文段或者文章的行文思想无意义的词(停用词),对重复率的判断有极大的影响,需要将其去除,故而就需要反文档频率(IDF)。
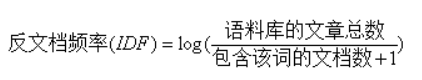
TF-IDF=词频(IF)*反文档频率(LDF)
- 相似度的求取方法
2.余弦相似度
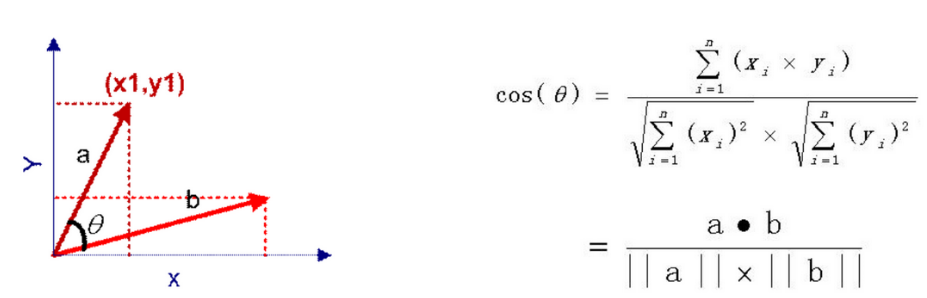
def cosine(vector1,vector2): dot_product = 0.0 normA = 0.0 normB = 0.0 for a,b in zip(vector1,vector2): dot_product += a*b normA += a**2 normB += b**2 if normA == 0.0 or normB==0.0: return None else: return dot_product / ((normA*normB)**0.5)
3.jaccard系数(与Tanimoto系数类似)
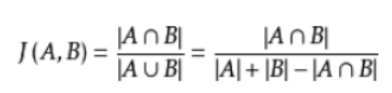
def Jaccrad(model, reference): # terms_reference为源句子,terms_model为候选句子 terms_reference = jieba.cut(reference) # 默认精准模式 terms_model = jieba.cut(model) grams_reference = set(terms_reference) # 去重;如果不需要就改为list grams_model = set(terms_model) temp = 0 for i in grams_reference: if i in grams_model: temp = temp + 1 fenmu = len(grams_model) + len(grams_reference) - temp # 并集 jaccard_coefficient = float(temp / fenmu) # 交集 return jaccard_coefficient
而cosine和jaccard系数函数可以直接调用python函数库
三.计算模块部分单元测试
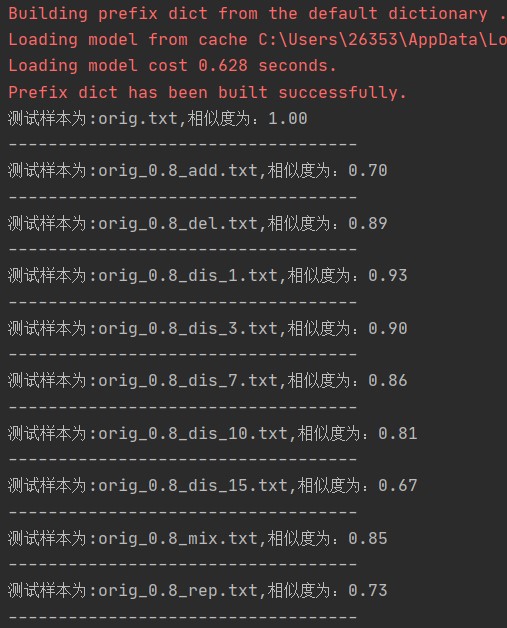
基于以上的初步设计过程而有了对测试样本的相似度计算
import jieba import os path1=os.path.abspath('.') #读取停用词,创建一个停用词表 stwlist= [line.strip() for line in open(path1+'\\'+'baidu_stopwords.txt',encoding='utf-8').readlines()] test ={} test['orig.txt'] = open(path1+'\\'+'orig.txt', 'r', encoding='utf-8').read() test['orig_0.8_add.txt'] = open(path1+'\\'+'orig_0.8_add.txt', 'r', encoding='utf-8').read() test['orig_0.8_del.txt'] = open(path1+'\\'+'orig_0.8_del.txt', 'r', encoding='utf-8').read() test['orig_0.8_dis_1.txt'] = open(path1+'\\'+'orig_0.8_dis_1.txt', 'r', encoding='utf-8').read() test['orig_0.8_dis_3.txt'] = open(path1+'\\'+'orig_0.8_dis_3.txt', 'r', encoding='utf-8').read() test['orig_0.8_dis_7.txt'] = open(path1+'\\'+'orig_0.8_dis_7.txt', 'r', encoding='utf-8').read() test['orig_0.8_dis_10.txt'] = open(path1+'\\'+'orig_0.8_dis_10.txt', 'r', encoding='utf-8').read() test['orig_0.8_dis_15.txt'] = open(path1+'\\'+'orig_0.8_dis_15.txt', 'r', encoding='utf-8').read() test['orig_0.8_mix.txt'] = open(path1+'\\'+'orig_0.8_mix.txt', 'r', encoding='utf-8').read() test['orig_0.8_rep.txt'] = open(path1+'\\'+'orig_0.8_rep.txt', 'r', encoding='utf-8').read() def jaccard(): #预处理:去分词,去停用词,去符号 test_word=[] i=0 for key in test.keys(): test_word.append([]) words = jieba.cut(test[key],cut_all =False) for word in words: if word.strip() not in stwlist: if word !='\t': if word !='\r\n': test_word[i].append(word) i=i+1 #jaccard系数的计算 j=0 for key in test.keys(): temp=0 for word in test_word[0]: if word in test_word[j]: temp =temp +1 fenmu = len(test_word[0]) + len(test_word[j]) -temp jaccard_coefficient =float(temp/fenmu) print('测试样本为:%s,相似度为:%.2f'%(key,jaccard_coefficient)) print('-----------------------------------') j=j+1 if __name__=='__main__': jaccard()
得到打印结果:
四. 计算模块部分异常处理说明。
try: except FileNotFoundError: print("文件未找到") except TimeoutError: print("文件读取超时") except FileEmpty: print("文件为空文件") else: print("无异常出现")
通过try...except...else...对异常现象进行处理,打印出现的异常类型。其中FileEmpty为自定义的异常情况。


五.性能测试和分析
运用pycharm自带的profile进行性能分析:
主要的耗时点:
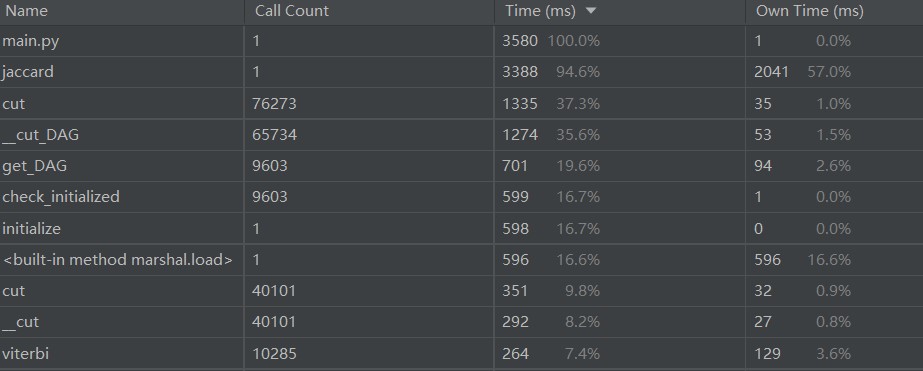
图像表现:
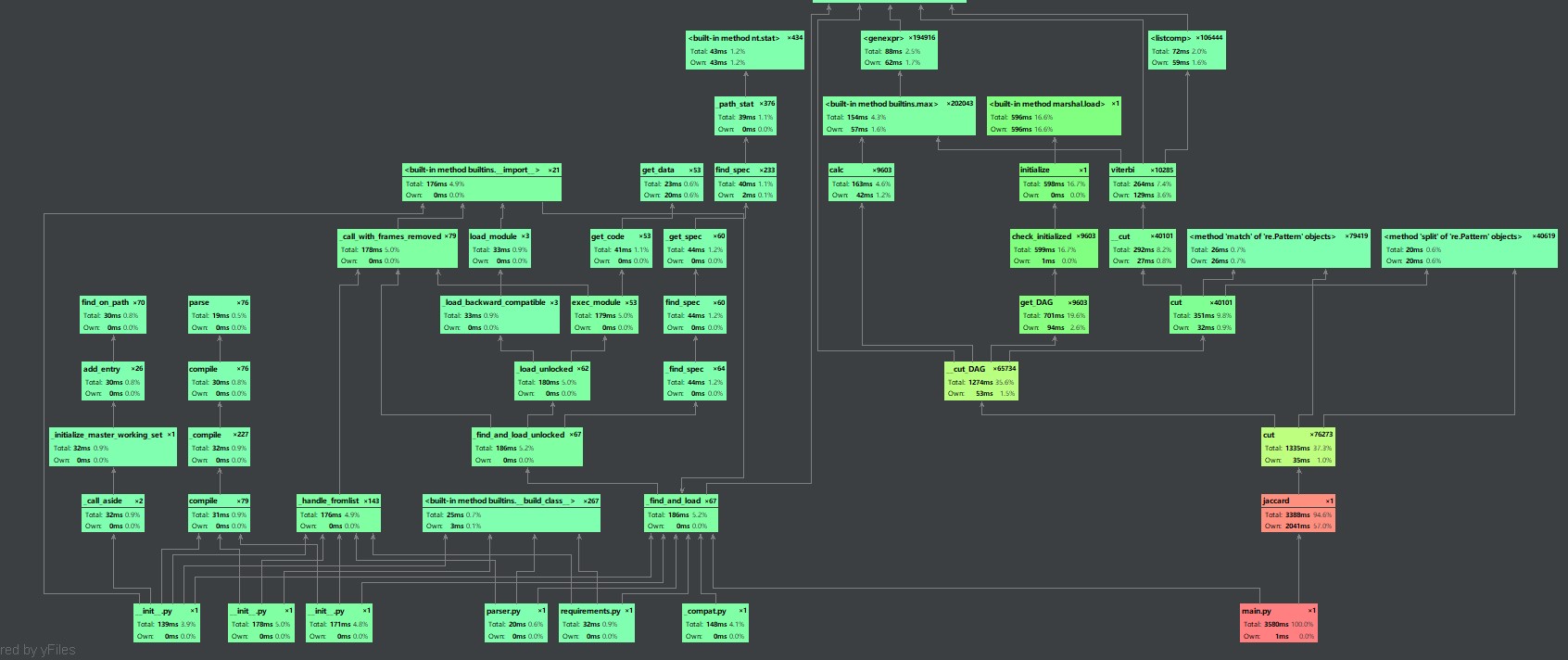
六.P2P表格分析
| psp2.1 | Personal Software Porcess Stages | 预估耗时(分钟) | 实际耗时(分钟) |
| Plaining | 计划 | 30 | 60 |
| Estimate | 估计这个任务需要多少时间 | 60 | 30 |
| Development | 开发 | 300 | 500 |
| Analysis | 需求设计(包括学习新技术) | 120 | 120 |
| Design Spec | 生成设计文档 | 60 | 90 |
| Design Review | 设计复审 | 10 | 20 |
| Coding Standard | 代码规范(为目前的开发制定合适的规范) | 10 | 10 |
| Design | 具体设计 | 80 | 60 |
| Coding | 具体编码 | 60 | 80 |
| Code Review | 代码复审 | 20 | 30 |
| Test | 测试(自我测试,修改代码,提交修改) | 60 | 150 |
| Reporting | 报告 | 100 | 200 |
| Test repor | 测试报告 | 30 | 80 |
| Size measurement | 计算工作量 | 10 | 10 |
| Postmortem & Process Improvement Plan | 事后总结,并提出过程的改进计划 | 60 | 30 |
| 合计 | 1110 | 1470 |
七.总结
通过这次的博客作业了解到要完成一个项目,需要的不仅仅是实现,更多的是对此的前期计划和设计,以及初步完成后的分析和改进。
在完成本次作业的过程中碰到了许多问题,通过百度,查阅资料,逐一解决,可谓收获良多。
参考网址:
https://www.cnblogs.com/chenxiangzhen/p/10648503.html
https://blog.csdn.net/weixin_40547993/article/details/89413753

