
手把手教你使用 Spring Boot 3 开发上线一个前后端分离的生产级系统(二) - 数据库设计
数据库设计规约
数据库设计遵循以下的阿里开发手册(嵩山版)MySQL 数据库规约:
1. 表达是与否概念的字段,必须使用 is_xxx 的方式命名,数据类型是 unsigned tinyint( 1 表示是, 0 表示否)。
说明: 任何字段如果为非负数,必须是 unsigned,坚持 is_xxx 的命名方式是为了明确其取值含义与取值范围。
正例: 表达逻辑删除的字段名 is_deleted, 1 表示删除, 0 表示未删除。
2. 表名、字段名必须使用小写字母或数字, 禁止出现数字开头,禁止两个下划线中间只出现数字。数据库字段名的修改代价很大,字段名称需要慎重考虑。
说明: MySQL 在 Windows 下不区分大小写,但在 Linux 下默认是区分大小写。因此,数据库名、表名、字段名,都不允许出现任何大写字母,避免节外生枝。
3. 表名不使用复数名词。
说明: 表名应该仅仅表示表里面的实体内容,不应该表示实体数量,对应于 DO 类名也是单数形式,符合表达习惯。
4. 禁用保留字,如 desc、 range、 match、 delayed 等, 请参考 MySQL 官方保留字。
5. 主键索引名为 pk_字段名;唯一索引名为 uk_字段名; 普通索引名则为 idx_字段名。
说明: pk_ 即 primary key; uk_ 即 unique key; idx_ 即 index 的简称。
6. 小数类型为 decimal,禁止使用 float 和 double。
说明: 在存储的时候, float 和 double 都存在精度损失的问题,很可能在比较值的时候,得到不正确的结果。如果存储的数据范围超过 decimal 的范围,建议将数据拆成整数和小数并分开存储。
7. 如果存储的字符串长度几乎相等,使用 char 定长字符串类型。
8. varchar 是可变长字符串,不预先分配存储空间,长度不要超过 5000,如果存储长度大于此值,定义字段类型为 text,独立出来一张表,用主键来对应,避免影响其它字段索引效率。
9. 表必备三字段: id, create_time, update_time。
说明: 其中 id 必为主键,类型为 bigint unsigned、单表时自增、步长为 1。 create_time, update_time的类型均为 datetime 类型,前者现在时表示主动式创建,后者过去分词表示被动式更新。
注意:更新数据表记录时,必须同时更新记录对应的 update_time 字段值为当前时间。
10. 表的命名最好是遵循“业务名称_表的作用” 。
正例:book_info / book_chapter / user_bookshelf / user_comment / author_info
11. 库名与应用名称尽量一致。
12. 如果修改字段含义或对字段表示的状态追加时,需要及时更新字段注释。
13. 字段允许适当冗余,以提高查询性能,但必须考虑数据一致。冗余字段应遵循:
- 不是频繁修改的字段。
- 不是唯一索引的字段。
- 不是 varchar 超长字段,更不能是 text 字段。
正例: 各业务线经常冗余存储小说名称,避免查询时需要连表(单体应用)或跨服务(微服务应用)获取。
14. 单表行数超过 500 万行或者单表容量超过 2GB,才推荐进行分库分表。
说明: 如果预计三年后的数据量根本达不到这个级别,请不要在创建表时就分库分表。
15. 合适的字符存储长度,不但节约数据库表空间、节约索引存储,更重要的是提升检索速度。
正例: 无符号值可以避免误存负数, 且扩大了表示范围。
16. 业务上具有唯一特性的字段,即使是组合字段,也必须建成唯一索引。
说明: 不要以为唯一索引影响了 insert 速度,这个速度损耗可以忽略,但提高查找速度是明显的; 另外,即使在应用层做了非常完善的校验控制,只要没有唯一索引,根据墨菲定律,必然有脏数据产生。
17. 超过三个表禁止 join。需要 join 的字段,数据类型保持绝对一致; 多表关联查询时,保证被关联的字段需要有索引。
说明: 即使双表 join 也要注意表索引、 SQL 性能。
18. 在 varchar 字段上建立索引时,必须指定索引长度,没必要对全字段建立索引,根据实际文本区分度决定索引长度。
说明: 索引的长度与区分度是一对矛盾体,一般对字符串类型数据,长度为 20 的索引,区分度会高达 90%以上,可以使用 count(distinct left(列名, 索引长度))/count(*)的区分度来确定。
19. 创建索引时避免有如下极端误解:
- 索引宁滥勿缺。 认为一个查询就需要建一个索引。
- 吝啬索引的创建。 认为索引会消耗空间、 严重拖慢记录的更新以及行的新增速度。
- 抵制惟一索引。 认为惟一索引一律需要在应用层通过“先查后插” 方式解决。
数据库建模工具
项目使用 PDManer 对数据库进行设计、版本管理等。
介绍
PDManer 元数建模,是一款多操作系统开源免费的桌面版关系数据库模型建模工具,基于 ES6 + React + Electron + Java 构建,相对于 PowerDesigner,他具备界面简洁美观,操作简单,上手容易等特点。支持 Windows, Mac, Linux 等操作系统,也能够支持国产操作系统,能够支持的数据库如下:
- MySQL, PostgreSQL, Oracle, SQLServer等常见数据库
- 支持达梦,GuassDB 等国产数据库
- 支持 Hive,MaxCompute 等大数据方向的数据库
- 用户还可以自行添加更多的数据库扩展
主要功能
数据表管理: 数据表,字段,注释,索引等基本功能。
视图管理: 实现选择多张表多个字段后,组合一个新的视图对象,视图可生成 DDL 以及相关程序代码,例如 Java 的 DTO 等。
ER关系图: 数据表可绘制ER关系图至画布,也支持概念模型等高阶抽像设计。
数据字典: 代码映射表管理,例如 1 表示男,2 表示女,并且实现数据字典与数据表字段的关联。
数据类型: 系统实现了基础数据类型,基础数据类型在不同数据库下表现为不同数据库类型的方言,这是实现多数据**库支持的基础,为更贴近业务,引入了PowerDesigner的数据域这一概念,用于统一同一类具有同样业务属性字段的批量设置类型,长度等。基础数据类型以及数据域,用户均可自行添加,自行定义。
多数据库: 内置主流常见数据库,如 MySQL,PostgreSQL,SQLServer,Oracle等,并且支持用户自行添加新的数据库。
代码生成: 内置 Java,Mybatis,MyBatisPlus 等常规情况下 Controller,Service,Mapper 的生成,也添加了 C# 语言支持,可自行扩展对其他语言的支持,如Python 等。
版本管理: 实现数据表的版本管理,可生成增量DDL脚本。
生态对接: 能够导入PowerDesigner的pdm文件,老版本的PDMan文件,也能导出为word文档,导出相关设置等。
软件下载
https://gitee.com/robergroup/pdmaner/releases
系统功能概要
-
前台门户系统
- 首页: 轮播图、本周推荐、热门推荐、精品推荐、点击榜单、新书榜单、更新榜单、最新新闻、友情链接、反馈留言
- 新闻模块: 新闻分类、新闻列表、新闻阅读
- 小说检索: 根据书名、作者名等关键词和作品频道、分类、是否完结、字数、更新方式等筛选条件检索小说
- 小说详情页: 小说信息展示、作家信息展示、最新章节概要、最新评论、评论发表、加入书架、同类推荐
- 小说评论页: 小说评论区,评论展示、发表评论
- 小说目录页: 小说目录展示
- 小说内容页: 小说章节订阅、小说内容阅读、小说段落评论
- 排行榜: 点击榜、更新榜、新书榜、评论榜
- 充值: 支付宝/微信购买虚拟币
- 会员中心: 登录注册、账号信息、账号设置、书架、阅读历史、书评、充值/消费记录、用户反馈
-
作家后台管理系统
- 作家申请: 获取邀请码、作家信息提交
- 小说管理: 小说发布、章节管理、薪酬查询、作品信息
- 稿费收入: 订阅明细、稿费汇总
-
平台后台管理系统
- 系统管理: 用户管理、角色管理、权限管理、菜单管理
- 首页管理: 小说推荐管理、新闻发布管理、友情链接管理
- 会员管理: 网站会员管理、反馈管理、评论管理
- 作家管理: 作家邀请码管理、作家信息管理
- 小说管理: 小说管理、小说章节管理
- 订单管理: 充值订单、订阅订单
- 统计报表: 会员、作家、小说、交易等数据的统计报表
数据库关系图
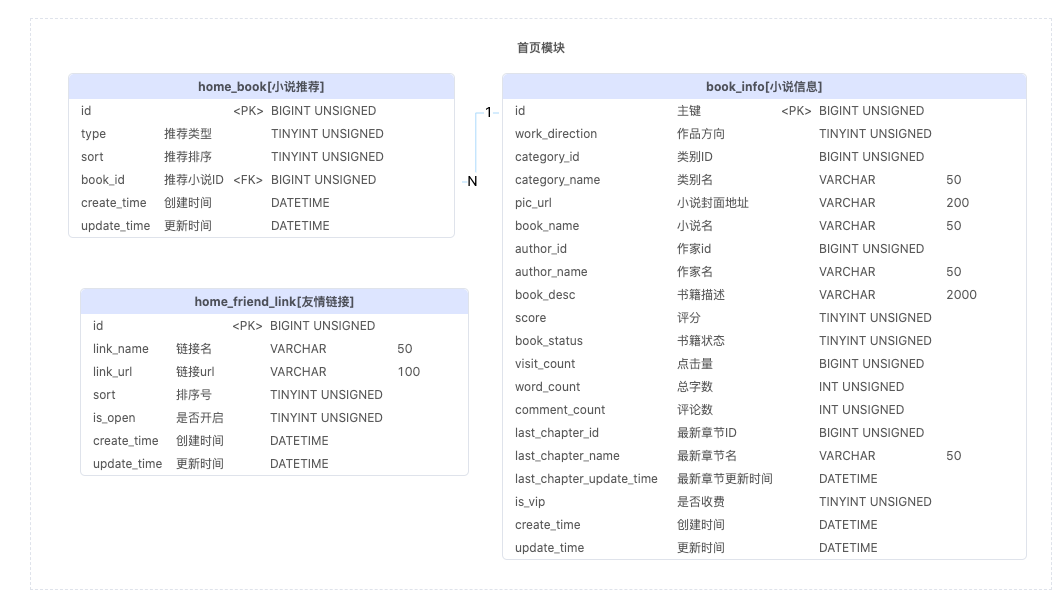
首页模块
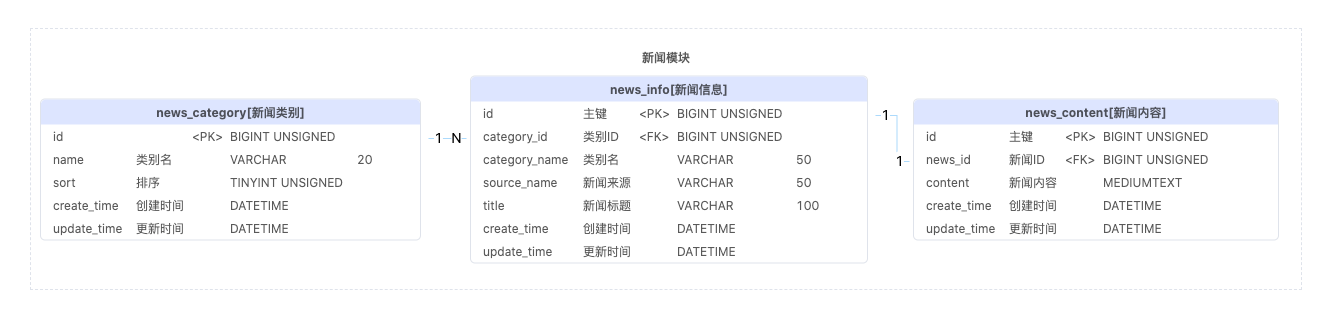
新闻模块
小说模块

用户模块

作家模块

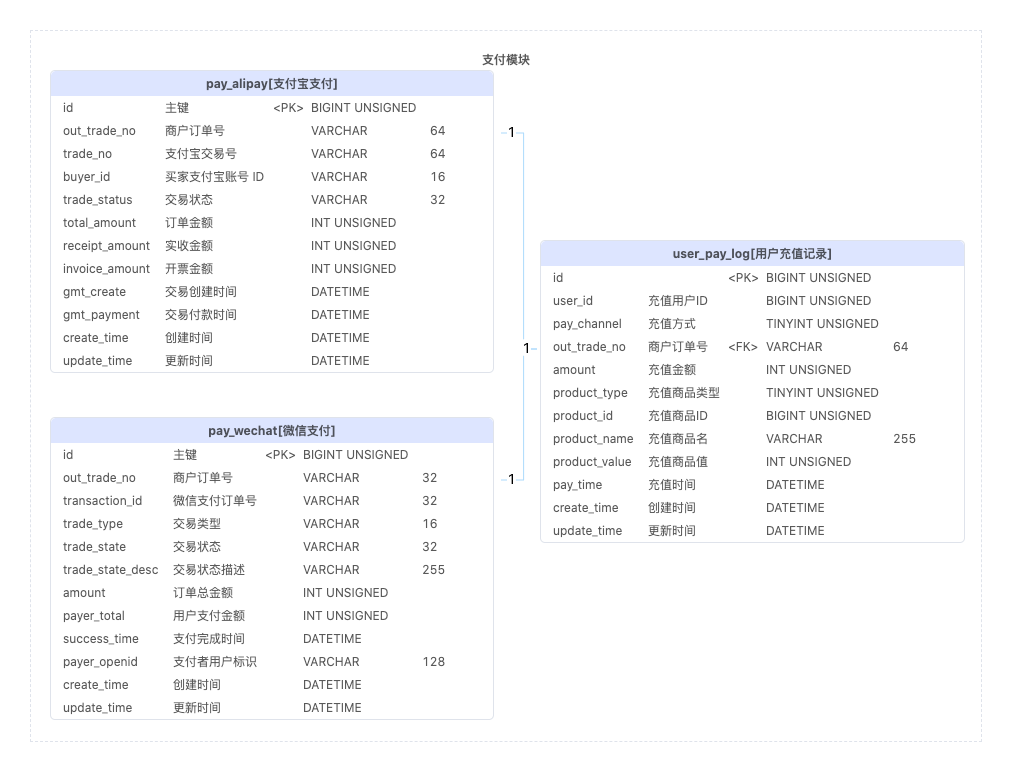
支付模块
系统模块


 浙公网安备 33010602011771号
浙公网安备 33010602011771号