【强化学习】阶段总结
-
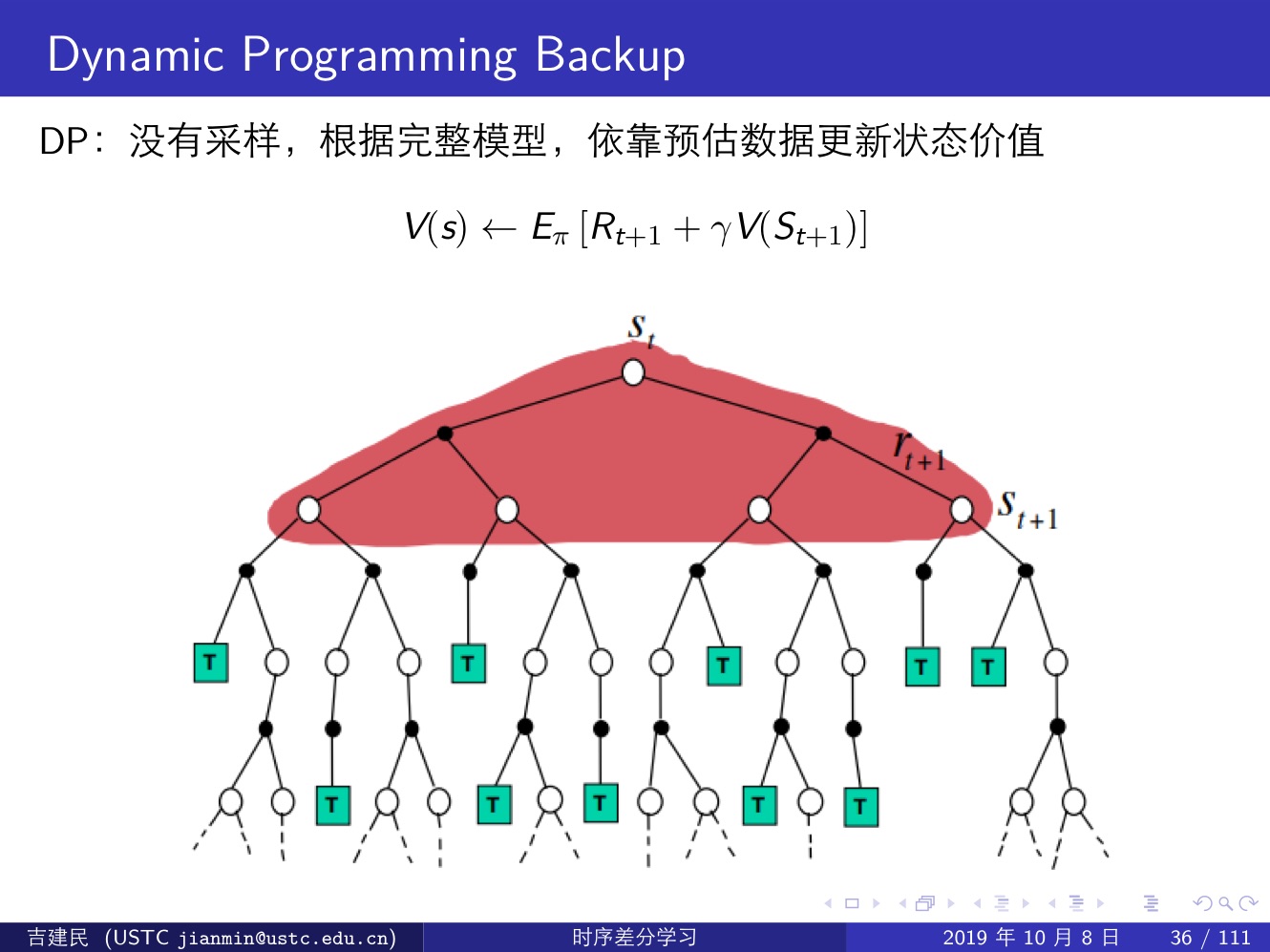
基于模型的动态规划方法(Model-Based,DP)
-
策略搜索
-
策略迭代
-
值迭代
-
-
无模型的强化学习方法(Model-Free)
-
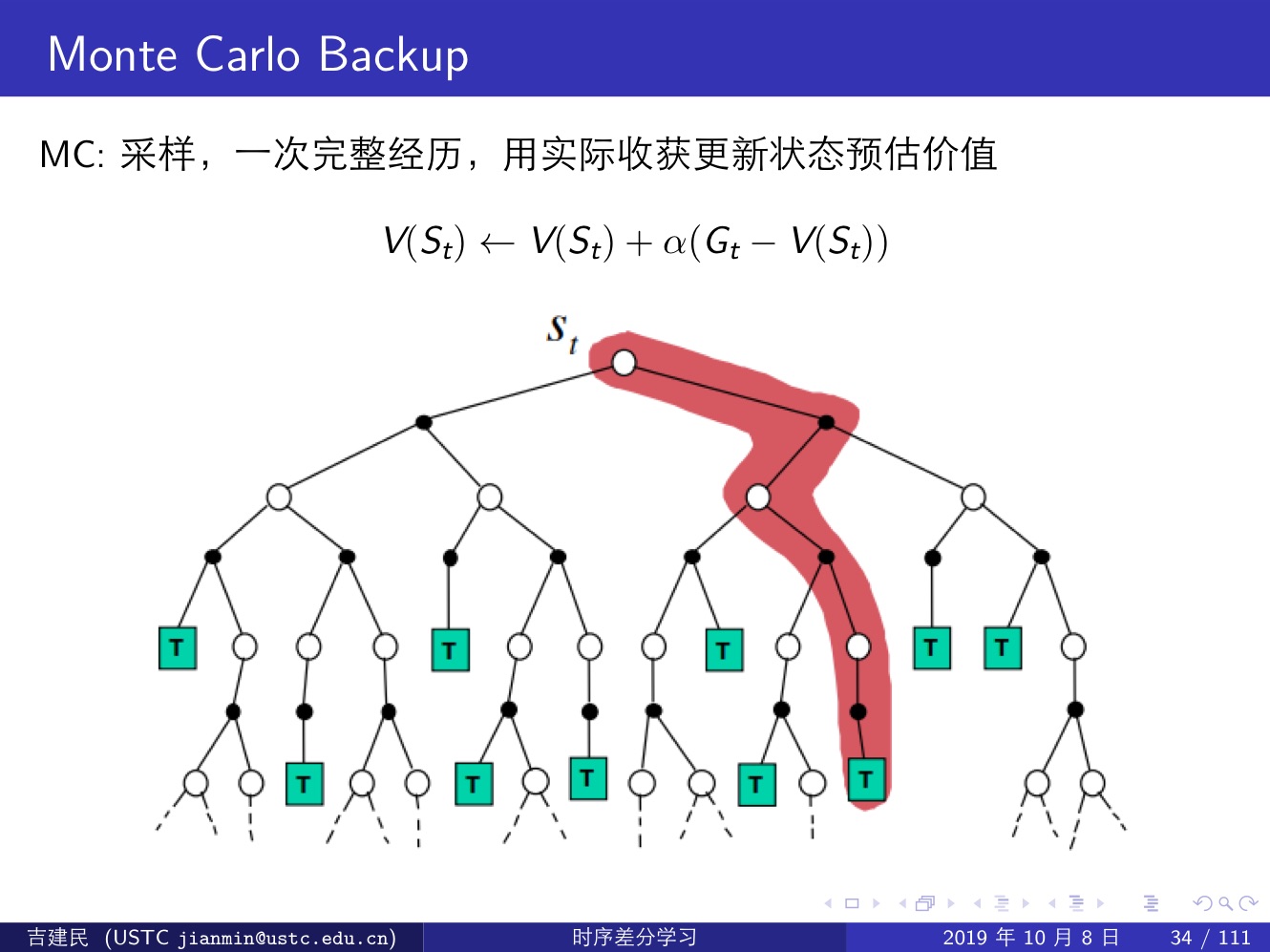
蒙特卡洛方法(MC):效率不高,但是能够展现 model-free 类算法的特性;
-
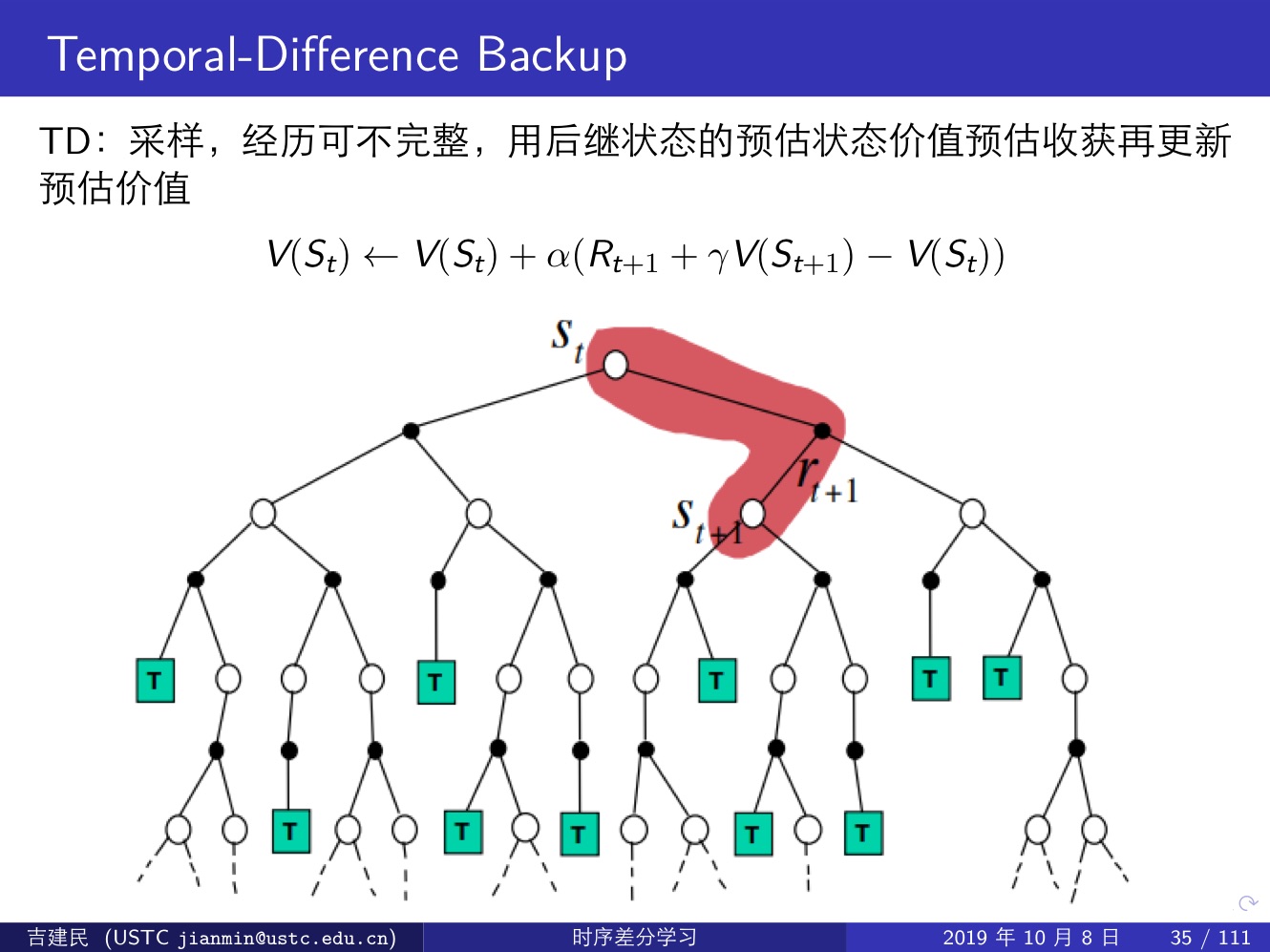
时序差分方法(TD,Important):直接从 episode 学习,不需要了解模型本身,即 model-free;可以学习不完整的 episode,通过自身的引导(bootstrapping),猜测 episode 的结果,同时持续更新这个猜测;
TD vs. MC
-
-
更好的收敛性质
-
对初始值不太敏感
-
使用简单
-
-
TD 较低的方差,但是有一定程度的偏差
-
通常比 MC 更加高效
-
TD(0) 收敛到 Vπ(s)
-
对初始值更加敏感
-
MC 算法试图收敛至一个能够最小化状态价值与实际收获的均方差的解决方案;
TD 算法收敛到一个根据已有经验构建的最大可能的马尔可夫模型的状态价值,也就是说 TD 算法首先根据已有经验估计状态空间的转移概率,同时估计某一个状态的即时奖励,最后计算该 MDP 的状态函数。
换句话说:
MC 方法并不利用马尔可夫性质,故在非马尔可夫环境中更有效率;
TD(0) 利用马尔可夫性质,在马尔可夫环境中更有效率。
总结以上内容:
MC vs. TD
| Monte-Carlo | Temporal Difference |
| 要等到 episode 结束才能获得 return | 每一步执行完都能获得一个return |
| 只能使用完整的 episode | 可以使用不完整的 episode |
| 高方差,零偏差 | 低方差,有偏差 |
| 没有体现出马尔可夫性质 | 体现出了马尔可夫性质 |
三种强化学习方法:Monte-Carlo,Temporal-Difference 和 Dynamic Programming,前两种属于 Model-Free 类方法(这其中 MC 需要一个完整的 episode,TD 则不需要完整的 episode),最后一种属于 Model-Based 类方法,它通过计算一个状态 s 所有可能的转移状态 s′ 及其转移概率以及对应的即时奖励来计算这个状态 s 的价值
- 关于是否 Bootstrap:MC 没有引导数据,只使用实际收获;DP 和 TD 都有引导数据;
- 关于是否用样本来计算:MC 和 TD 都是应用样本来估计实际的价值函数;而 DP 则是利用模型直接计算得到实际价值函数,没有样本或者采样之说。
- MC 方法使用值函数最原始的定义,该方法利用所有回报的累积和估计值函数;DP 方法和 TD 方法则利用一步预测方法计算当前状态值函数。其共同点是利用了 bootstrapping 方法,不同的是,DP 方法利用模型计算后继状态,而 TD 方法利用试验得到后继状态。
下面几张提很好的说明了这三类算法的区别:
强化学习大一统:
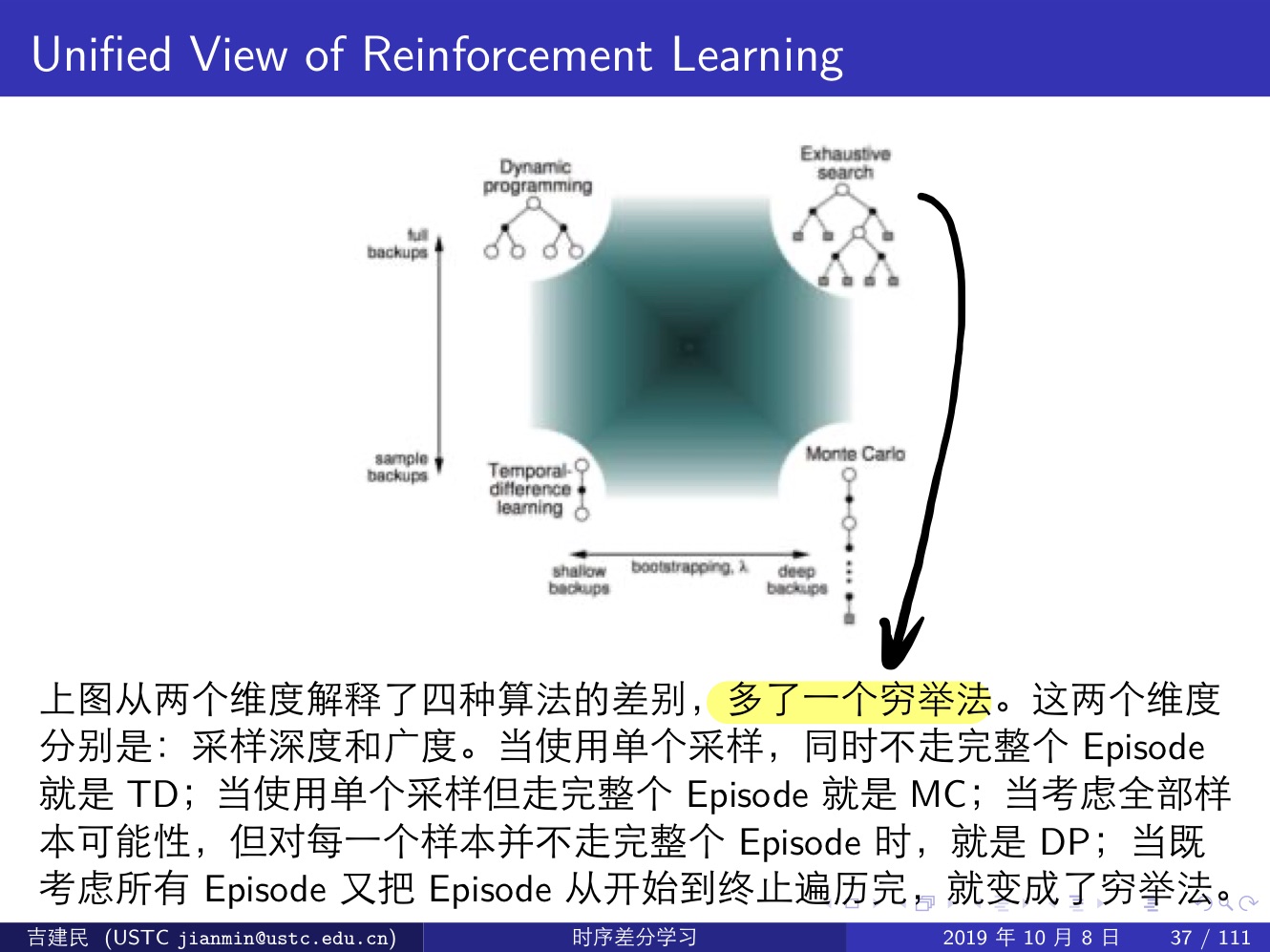
我们可以发现,MC 和 TD 方法都过于极端:
- MC 方法需要 episode 走到终止状态才能更新,相当于 ∞-step TD target;
- TD 方法只走一步就更新,相当于 1-step TD target
通常好的方法都是在两个极端之间进行选择,也就是 n-step TD target,这要等到下次才写了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号