xpath 的使用
如需转发,请注明出处:小婷儿的python https://www.cnblogs.com/xxtalhr/p/10520271.html
有问题请在博客下留言或加作者微信:tinghai87605025 或 QQ :87605025
python QQ交流群:py_data 483766429
OCP培训说明连接:https://mp.weixin.qq.com/s/2cymJ4xiBPtTaHu16HkiuA
OCM培训说明连接:https://mp.weixin.qq.com/s/7-R6Cz8RcJKduVv6YlAxJA
一、xpath 浅谈
1.1 xpath 是什么?
给某些规律信息找通用表达式,我们首先想到的是正则,然而,对于大部分的我们正则用的是不好的,如果用来处理HTML文档是很累,那么有没有其他的方法?答案是肯定的,有!那就是XPath,我们可以先将网络获取的String类型数据转换成 HTML/XML文档,然后用 XPath 查找 HTML/XML 节点或元素。
即XPath (XML Path Language) 是一门在 XML 文档(如下图)中查找信息的语言,可用来在 XML 文档中对元素和属性进行遍历
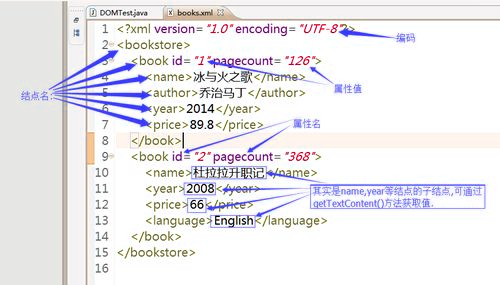
1.2 lxml 库
lxml 是 一个HTML/XML的解析器,主要的功能是如何解析和提取 HTML/XML 数据。
lxml和正则一样,也是用 C 实现的,是一款高性能的 Python HTML/XML 解析器,我们可以利用XPath语法,来快速的定位特定元素以及节点信息。
二、 xpath 路径表达式
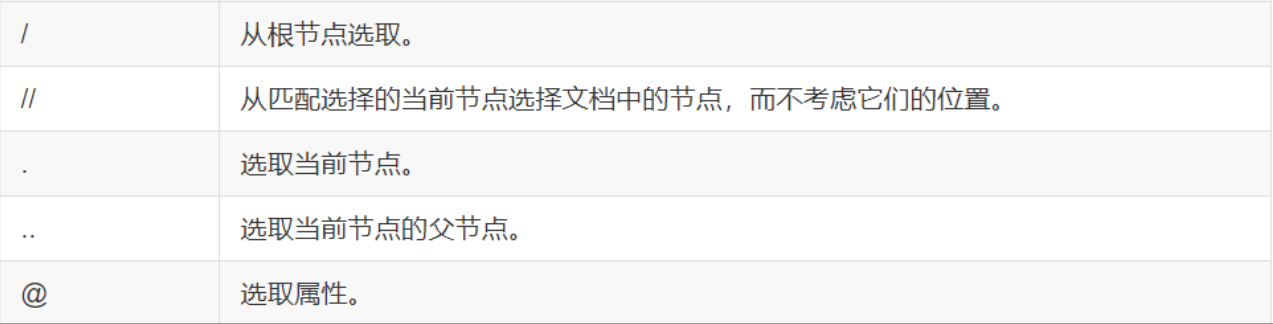
2.1 最常用的路径表达式
2.2 常用路径表达式以及表达式的结果

2.3 选取未知节点


2.4 选取若干路径,通过在路径表达式中使用“|”运算符,您可以选取若干个路径
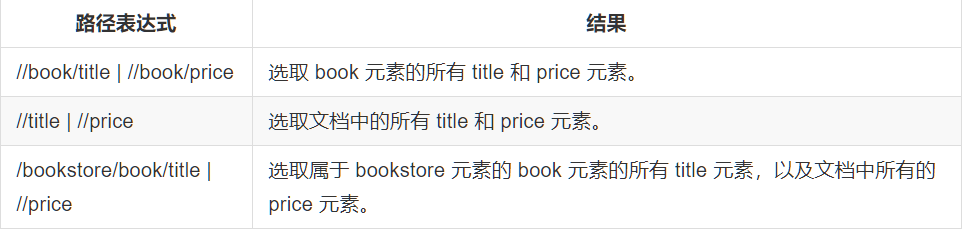
2.5 xpath的运算符

三、xpath 入门测试
3.1 lxml 读取数据
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8" />
<title>测试页面</title>
</head>
<body>
<ol>
<li class="haha">醉卧沙场君莫笑,古来征战几人回</li>
<li class="heihei">两岸猿声啼不住,轻舟已过万重山</li>
<li id="hehe" class="nene">一骑红尘妃子笑,无人知是荔枝来</li>
<li class="xixi">停车坐爱枫林晚,霜叶红于二月花</li>
<li class="lala">商女不知亡国恨,隔江犹唱后庭花</li>
</ol>
<div id="pp">
<div>
<a href="http://www.baidu.com">李白</a>
</div>
<ol>
<li class="huanghe">君不见黄河之水天上来,奔流到海不复回</li>
<li id="tata" class="hehe">李白乘舟将欲行,忽闻岸上踏歌声</li>
<li class="tanshui">桃花潭水深千尺,不及汪伦送我情</li>
</ol>
<div class="hh">
<a href="http://mi.com">雷军</a>
</div>
<div class="jj">
<b href="http://mi.com"><c>3</c></b>
<b href="http://mi.com"><c>5</c></b>
<b href="http://mi.com"><c>6</c></b>
<b href="http://mi.com"><c>8</c></b>
<b href="http://mi.com"><c>9</c></b>
<b href="http://mi.com"><c>3</c></b>
</div>
<ol>
<li class="dudu">are you ok</li>
<li class="meme">会飞的猪</li>
</ol>
</div>
</body>
</html>
3.2 xpath 入门实验
- lxml 、element 、etree
-
1 import requests 2 3 # lxml 4 # element 标签 5 # etree 标签树 6 from lxml import etree 7 8 url = 'https://www.qiushibaike.com/text/' 9 10 x = '''/html/body/div[@id='content']/div[@class='content-block clearfix']/div[@id='content-left']/div[@id='qiushi_tag_120441381']/div[@class='author clearfix']/a[1]/img/@src''' 11 12 13 x = '''/html/body/div[@id='content']/div[@class='content-block clearfix']/div[@id='content-left']/div[@id='qiushi_tag_112124634']/div[@class='author clearfix']/a[1]/img/@src''' 14 15 x = '//img/@src' 16 17 x = '''/html/body/div[@id='content']/div[@class='content-block clearfix']/div[@id='content-left'] 18 /div[@id='qiushi_tag_112124634']/a[@class='contentHerf']/div[@class='content']/span''' 19 20 x = '//div[@class="content"]/span/text()' 21 response = requests.get(url=url,verify = False) 22 response.encoding = 'utf-8' 23 24 # String 串 25 html = response.text 26 27 # 使用etree,转换成标签树 28 # json.loads() 类似 29 30 31 html_tree = etree.HTML(html) 32 33 # print(html_tree) 34 # print(etree.tostring(html_tree).decode('utf-8')) 35 36 37 # 对etree对象使用xpath方法,根据xpath语句进行数据的查找 38 src = html_tree.xpath(x) 39 40 print(src)
-
- 获取所有的 <li> 标签
-
1 from lxml import etree 2 3 html = etree.parse('hello.html') 4 li_list = html.xpath('//li') 5 6 print(li_list) # 打印<li>标签的元素集合 7 print(len(li_list))
-
- 继续获取<li> 标签的所有 class属性
-
1 from lxml import etree 2 3 html = etree.parse('hello.html') 4 result = html.xpath('//li/@class') 5 print(result)
-
- 继续获取<li>标签下hre 为 link1.html 的 <a> 标签
-
1 from lxml import etree 2 html = etree.parse('./hello.html') 3 result = html.xpath('//li/a[@href="link1.html"]') 4 print(result)
-
- 获取<li> 标签下的所有 <span> 标签
-
1 from lxml import etree 2 data = ''' 3 <div> 4 <ul> 5 <li class="item-0">你好,老段<a href="link1.html">first item</a></li> 6 <li class="item-1"><a href="link2.html">second item</a></li> 7 <li class="item-inactive"><a href="link3.html"><span class="bold">third item</span></a></li> 8 <li class="item-1"><a href="link4.html">fourth item</a></li> 9 <li class="item-0"><a href="link5.html">fifth item</a></li> 10 </ul> 11 </div>''' 12 html = etree.HTML(data) 13 result = html.xpath('//li//span') 14 print(result[0].text)
-
- 获取 <li> 标签下的<a>标签里的所有 class
-
1 # 获取 <li> 标签下的<a>标签里的所有 class 2 from lxml import etree 3 html = etree.parse('hello.html') 4 result = html.xpath('//li/a//@class') 5 6 print(result)
-
- 获取最后一个 <li> 的 <a> 的 href
-
1 from lxml import etree 2 3 xml = etree.parse('./hello.html') 4 5 result = xml.xpath('//li[last()]/a/@href') 6 7 print(result)
-
- 获取倒数第二个元素的内容
-
1 from lxml import etree 2 3 html = etree.parse('hello.html') 4 result = html.xpath('//li[last()-1]/a') 5 print(result[0].text) 6 print(result)
-
- 获取 class 值为 bold 的标签名
-
1 # 获取 class 值为 bold 的标签名 2 from lxml import etree 3 html = etree.parse('hello.html') 4 result = html.xpath('//*[@class="bold"]') 5 # tag方法可以获取标签名 6 print(result[0].tag) 7 print(result[0].text)
-
- 练习使用xpath获取books该xml文件中的内容
1 from lxml import etree 2 3 books = ''' 4 <?xml version="1.0" encoding="utf-8"?> 5 <bookstore> 6 <book category="cooking"> 7 <title lang="en">Everyday Italian</title> 8 <author>Giada De Laurentiis</author> 9 <year>2008</year> 10 <price>30.00</price> 11 </book> 12 <book category="children" lang="zh"> 13 <title lang="en">Harry Potter</title> 14 <author>J K. Rowling</author> 15 <year>2005</year> 16 <price>29.99</price> 17 </book> 18 <book category="web"> 19 <title lang="en">XQuery Kick Start</title> 20 <author>James McGovern</author> 21 <author>Per Bothner</author> 22 <author>Kurt Cagle</author> 23 <author>James Linn</author> 24 <author>Vaidyanathan Nagarajan</author> 25 <year>2003</year> 26 <price>49.99</price> 27 </book> 28 <book category="web" cover="paperback"> 29 <title lang="en">Learning XML</title> 30 <author>Erik T. Ray</author> 31 <year>2003</year> 32 <price>39.95</price> 33 </book> 34 </bookstore> 35 ''' 36 37 books_tree = etree.HTML(books) 38 39 books = books_tree.xpath('//book[price<=30][year + 3 = 2008]') 40 41 print(books) 42 43 # 将查询到的book中的所有属性选出来 44 ret = books[0].xpath('.//@*') 45 print(ret)
- 数据转换成标签树
1 from lxml import etree 2 3 html = '''<div> 4 <ul> 5 <li class="item-0"><a href="link1.html">first item</a></li> 6 <li class="item-1"><a href="link2.html">second item</a></li> 7 <li class="item-inactive"><a href="link3.html" class="linkjfdlsfjls">third item</a></li> 8 <li class="shfs-inactive"><a href="link4.html">third item</a></li> 9 <li class="isjfls-inactive"><a href="link5.html">third item</a></li> 10 <li class="qwert-inactive"><a href="link6.html">third item</a></li> 11 <li class="item-1"><a href="link4.html">fourth item</a></li> 12 <li class="item-0"><a href="link5.html">fifth item</a> 13 </ul> 14 </div>''' 15 16 # 数据转换成标签树 17 #方式一 18 html_tree = etree.HTML(html) 19 20 # 方式二,可以将文件中的直接进行转换 21 html_tree2 = etree.parse('./data.html') 22 23 # print(html_tree,html_tree2) 24 25 # print(etree.tostring(html_tree).decode('utf-8')) 26 # 获取文件中所有的标签li 27 # xpath返回的数据是列表,标签<Element 内存地址> 28 li = html_tree.xpath('//li') 29 # print(li) 30 31 32 li = html_tree.xpath('//li[@class="item-1"]') 33 # print(li[0].xpath('..//a/text()')) 34 35 36 # 查询class属性不等于“item-1” 标签 37 li = html_tree.xpath('//li[@class!="item-1"]') 38 # print(li) 39 40 41 # 查询li标签,class 包含inactive 字符串 42 li = html_tree.xpath('//li[contains(@class,"inactive")]') 43 # print(li) 44 # print(li[0].xpath('./a/@*')) 45 46 47 # 查询li标签,class 不包含inactive字符串 48 li = html_tree.xpath('//li[not(contains(@class,"inactive"))]') 49 # print(li) 50 # print(etree.tostring(li[0]).decode('utf-8')) 51 52 53 # 查询li标签,class 不包含inactive字符串 同时包含class =item-1 54 li = html_tree.xpath('//li[not(contains(@class,"inactive"))][@class="item-1"]') 55 # print(li) 56 # print(etree.tostring(li[-1]).decode('utf-8')) 57 58 59 # 查询li标签,最后一个 60 # print(etree.tostring(html_tree).decode('utf-8')) 61 li = html_tree.xpath('/html/body/div/ul/li') 62 li = html_tree.xpath('//li[last()-1]') 63 # print(li,etree.tostring(li[0])) 64 65 66 # 查询位置小于4的标签 67 li = html_tree.xpath('//li[position()<4]') 68 print(li)
欢迎关注小婷儿的博客:
csdn:https://blog.csdn.net/u010986753
博客园:http://www.cnblogs.com/xxtalhr/
有问题请在博客下留言或加作者微信:tinghai87605025 或 QQ :87605025
python QQ交流群:py_data 483766429
OCP培训说明连接:https://mp.weixin.qq.com/s/2cymJ4xiBPtTaHu16HkiuA
OCM培训说明连接:https://mp.weixin.qq.com/s/7-R6Cz8RcJKduVv6YlAxJA
小婷儿的python正在成长中,其中还有很多不足之处,随着学习和工作的深入,会对以往的博客内容逐步改进和完善哒。
重要的事多做几遍。。。。。。

文章内容来源于小婷儿的学习笔记,部分整理自网络,若有侵权或不当之处还请谅解 有趣的事,Python永远不会缺席!
如需转发,请注明出处:小婷儿的博客python https://www.cnblogs.com/xxtalhr/
博客园:https://www.cnblogs.com/xxtalhr/
CSDN:https://blog.csdn.net/u010986753
有问题请在博客下留言或加作者:
微信:tinghai87605025
QQ :87605025
python QQ交流群:py_data 483766429

培训说明:
OCP培训说明连接:https://mp.weixin.qq.com/s/2cymJ4xiBPtTaHu16HkiuA
OCM培训说明连接:https://mp.weixin.qq.com/s/7-R6Cz8RcJKduVv6YlAxJA
小婷儿的python正在成长中,其中还有很多不足之处,随着学习和工作的深入,会对以往的博客内容逐步改进和完善哒。重要的事多说几遍。。。。。。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号