

数据分析(一)
数据分析是使用适当的方法对收集来的大量数据进行分析,帮助人们做出判断,一遍采取适当行动
数据分析的流程 提出问题->准备数据->分析数据->获得结论->成果可视化
数据分析是使用适当的方法对收集来的大量数据进行分析,帮助人们做出判断,一遍采取适当行动
数据分析的流程 提出问题->准备数据->分析数据->获得结论->成果可视化
变量--名字 print("/'中文"/')print(变量)输出
python3支持中文变量名 幸运数=9
单引号双引号都是成双成对的print('Let's go!')这里的‘也认为是一半的单引号,出现了引号不匹配的现象print("Let's go!")这样不会产生误会
print(' "好好学习,天天向上" ')这样输出的是“好好学习,天天向上” \转义字符
如何让其知道这个字符串没有结束print(" \n\
@ \n\ 加一个\才能继续换行打下一行,
/ \\ \n")最后一行加一个\")输出有误
当你使用长字符串的时候,就不需要加上一个\才可以换行使用,长字符串Triple quoted(三引号字符串)但是要前后呼应,成双成对,使用""" """换行的时候直接回车就可以了,不需要反斜杠
字符串可以使用加法进行拼接‘520’+‘1314’ 输出5201314
字符串可以使用惩罚进行复制print("我每天爱你三千遍"*3000)输出三千遍的我每天爱你三千遍
temp=input("你是谁")
在idel交互界面显示 你是谁:我是谜 (我是谜是自己回复的内容)用户输入什么temp变量的值就是什么 print(temp)输出的就是我是谜
guess=int(temp) 这里是强制类型转换
is判断两个对象的id是否相等
is not判断两个对象的id是否不相等
条件成立时执行的两条语句在同一个阵营,要缩进一致
随机数据的使用
import random
random.randint(a,b) a和b两个数是表示希望获取的随机整数的范围
random模块生成的是伪随机数,因为random1的是伪随机数,要想重现随机数,要拿到它的种子,它是将系统时间来作为随机数种子random.getstate(),使用这个可以将随机数重现一遍
print将时间表输出文件中
fp=open('D:/text.txt','a+') fp是指针变量 如果没有这个文件就新建
print('helloworld'.file=fp) 将helloworld写入文件中 一定要加上file=文件名,否则无法写入
+是连接符,不能将字符串和int型进行连接,进行类型转换int转为str
int() 文字和小数类字符串,无法转化为整数 浮点数转化为整数,抹零取整
float()文字类无法转换成整数,整数转为浮点数,末尾为0
单行注释#开头直到换行结束
多行注释 是将一堆三引号之间的代码成为多行注释
中文编码声明注释 在文件的开头机上中文声明注释,用以制定源码文件的编码格式#coding:gdk gdk是一种编码格式
python输入函数input()它的返回值类型为str 将值存储到变量里面 present=input(‘大圣想要什么样的礼物’)这个是一个提问,我们需要根据这个提示输入一个值存储到present,注意这里是str返回值
present=input('你想输入的数字是几')
present=int(present)
print(present,type(present)) 这样才是int型
默认utf-8
算术运算(**幂运算 */ //整除 % + -) 然后是位运算(<< >> & |) 然后是比较运算(> < >= <= == !=)最后是逻辑运算(and or =)
内置函数range()
range(stop)创建一个(0,stop)之间的整数序列,步长为1
range(start,stop)创建一个(start,stop)之间的整数序列,步长为1
range(start,stop,step)创建一个(start,stop)之间的整数序列,步长为step
range:不管表示的整数序列有多长,所有range对象占用的内存空间都是相同的,返回值是一个迭代器对象,所以要用一个list列表可以用来查看range对象中的整数序列
in与not in判断整数序列中是否存在(不存在)制定的整数 print('p'in'python') 返回值是True
for -in循环
in表示从(字符串。序列等)中依次取值,又称为遍历
循环体中不需要访问自定义变量,将自定义变量替代为下划线
for item in 'python': #依次将字母取出赋给item
print(item)
for i in range(10):
print(i)
判断水仙花数
for item in range(100,1000)
ge=item%10
shi=item//10%10
bai=item//100
if ge**3+shi**3+bai**3==item #都是不加括号的,**是幂,还要注意if有缩进因为是在for循环里面的
print(item)
print(‘二进制’,0b110110) 八进制0o166 十六进制0x76 这样在前面加上一些符号就表示进制改变了
不在变量前面加上数据类型 a=10,默认十进制 a=3.1212 默认是浮点数
浮点数存储不精确,使用浮点数存储时可能出现小数位数不确定的情况
布尔类型:用来表示真或假的值 布尔值可以转化为整数True->1 False->0
a=true 这样表示
双分支结构
if 条件表达式:
条件执行体1
else:
条件执行体2
嵌套if
if 条件表达式1:
if 内层条件表达式:
内层条件执行体1
else:
内层条件执行体2
else:
条件执行体
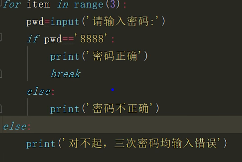
for-else 以及while-else组合 没有碰到break时执行else
列表的创建
1.使用方括号lst=['大圣','八戒']
2.调用内置函数list() lst2=list(['hello','world',98 ])
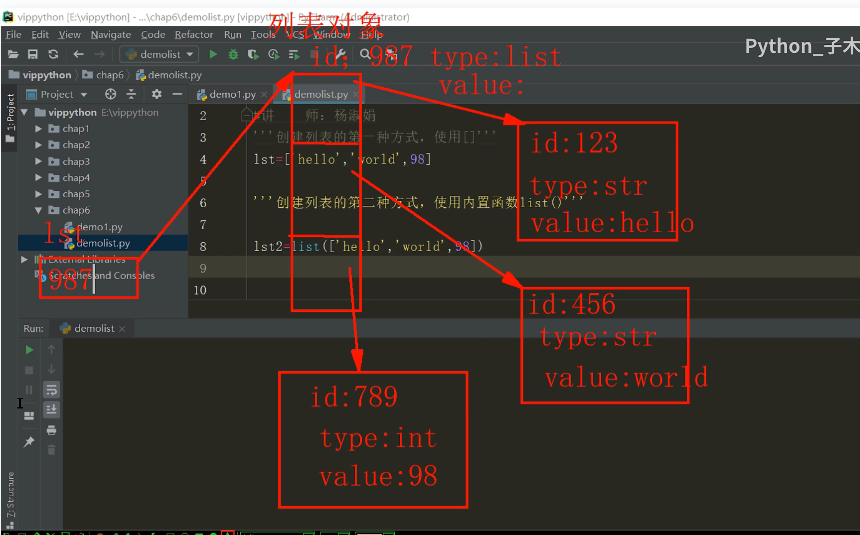
列表元素按顺序有序排序
索引映射唯一一个数据
列表可以存储重复数据
任意数据类型混存
根据需要动态分配和回收内存

分为顺序的索引和逆序的索引lst2【0】和lst2【-3】都会打印输出hello
获取列表中指定元素的索引
index()列表中有多个相同的元素,只返回相同元素中的第一个元素的索引
查询的元素不在列表中,会抛出ValueError
可以在指定的start和stop之间查找
获取列表中的单个元素
正向索引从0到1
逆向索引-N到-1
指定索引不存在,抛出indexError
lst=['hello','world','world',98]
print(lst.index('world'))
print(lst.index('hello',0,3))
获取列表中多个元素
列表名[start:stop:step] 当step不写时,默认为1
是进行切片操作,进行原列表片段的拷贝
区间【start,stop) 不包括stop
[:stop:step] step为正数,切片的第一个元素默认是列表的第一个元素,从start开始往后计算切片
[start::step] step为正数,切片的最后一个元素默认是列表的最后一个元素,从start开始往后计算切片
[:stop:step] step为负数,切片的第一个元素默认是列表的最后一个元素,从start开始往前计算切片
[:stop:step] step为负数,切片的最后一个元素默认是列表的第一个元素,从start开始往前计算切片
列表元素的增加操作,没有添加新的列表对象,而是在原列表的基础之上
append()在列表的末尾添加一个元素
extend()在列表的末尾至少添加一个元素
insert()在列表的任意位置添加一个元素
切片 在列表的任意位置添加至少一个元素 lst[1:] =lst3 在1的位置上开始切片,没有写结束到列表的最后一个数,这样是指把lst的第一个数据的复制到新 的拷贝的lst中,把第二个以及之后的数据为lst3中的数据,原lst 的第二个数据及之后的不在新的拷贝的数据中
lst=[10,20,30]
lst.append(40)
lst1=['hello','world']
lst.extend(lst1)
print(lst)
[10, 20, 30, 40, 'hello', 'world'] 将lst1作为一个元素添加到列表的尾部
lst.extend(90)这个是报错的
lst.insert(1,90) 在序列为1的位置添加90
列表元素的删除操作
remove()一次删除一个元素 重复元素只删除第一个 元素不存在抛出ValueError lst.remove(列表中的元素值)
pop()删除一个指定索引位置上的元素 指定索引位置的元素不存在抛出IndexError 不指定索引,删除列表最后一个元素
切片 一次至少删除一个元素 new_lst=lst[1:3] 保留从序列1到2的元素 其余的删除
如果不想要产生新的列表对象,而是删除愿列表中的内容 lst【1:3】=【】在这里将1到2上的元素用空元素取代
clear()清空列表 lst.clear()
del 删除列表 del lst
列表元素的修改操作
为指定索引元素赋予一个新值 lst[2]=100
未指定的切片赋予一个新值 lst[2:4]=[100,200.300,400,500] 超过这个范围也完全没有问题
列表的排序操作
常见的两种方法
调用sort()方法,列表中的所有元素默认按照从小到大的顺序进行排序,可以指定reverse=True 进行降序排序,在原列表上发生变化
调用内置函数sorted(),函数和方法的调用过程是不一样,可以指定reverse=True 进行降序排序,原列表不发生改变
lst=[20,40,10,44,56,2,66]
print('排序前的列表',lst,id(lst))
#开始排序调用列表对象的sort方法
lst.sort()
print('排序后升序的列表',lst,id(lst))
lst.sort(reverse=True)
print('排序后降序的列表',lst,id(lst))
lst1=[20,44,23,78,12]
print('排序后的列表',lst1,id(lst))
new_list=sorted(lst1)
print('排序后的列表',new_list,id(lst))
new_list1=sorted(lst1,reverse=True)
print('排序后的列表',new_list1,id(lst))
列表生成式(生成列表的公式)
语法格式:[i*i for i in range(1,10)]
表示列表元素的表达式中通常包含自定义变量 列表中最终存储的是i*1的数
lst=[i for i in range(1,10)]
print(lst)
[1, 2, 3, 4, 5, 6, 7, 8, 9] 1到9 9个元素
lst=[i*i for i in range(1,10)]
print(lst)
[1, 4, 9, 16, 25, 36, 49, 64, 81] 元素的幂


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本