

关于SVM数学细节逻辑的个人理解(三) :SMO算法理解
第三部分:SMO算法的个人理解
接下来的这部分我觉得是最难理解的?而且计算也是最难得,就是SMO算法。
SMO算法就是帮助我们求解:
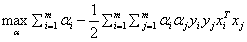
s.t. 
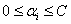
这个优化问题的。
虽然这个优化问题只剩下了α这一个变量,但是别忘了α是一个向量,有m个αi等着我们去优化,所以还是很麻烦,所以大神提出了SMO算法来解决这个优化问题。
关于SMO最好的资料还是论文《Sequential Minimal Optimization A Fast Algorithm for Training Support Vector Machines》还有《统计学习方法》上的相关内容。
整个SMO算法包括两部分,求解两个变量的二次规划问题和选择这两个变量的启发式方法
我觉得SMO算法难就难在对两个α变量的选择过程。
上面那个悬而未决的优化问题无非就是要找到一组最优的α,SMO算法则是把对整个α的优化转化为对每一对αi的优化,如果我们把其他α先固定,仅仅优化某一对α,那么我们可以通过解析式(即通过确定的公式来计算)来优化α。而且此时KKT条件很重要,之前说过最优解是一定会满足KKT条件的,所以如果我们优化α到所有的α都满足了KKT条件,那么这样最优解就会找到。我觉得这就是SMO算法的基本思想吧。
一.如何解决关于两个α的二次规划问题
首先给出SMO算法关于求解两个变量的二次规划问题的理解:
前面求出了关于α的约束条件:

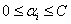
其中 这个条件很关键。下面为了叙述方便,统一选择
这个条件很关键。下面为了叙述方便,统一选择 和
和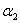 作为要更新的那两个参数,其他参数先固定。
作为要更新的那两个参数,其他参数先固定。
如果我确定了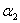 的新值,那么根据
的新值,那么根据 ,因为其他m-2个参数都固定,所以
,因为其他m-2个参数都固定,所以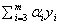 是个固定值,所以我可以根据这个计算出
是个固定值,所以我可以根据这个计算出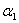 。所以每一次我选择两个变量进行更新。
。所以每一次我选择两个变量进行更新。
1.得到关于 和
和 的二次规划问题
的二次规划问题
那么原来的对整个α的优化问题,其实可以先写成关于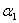 和
和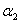 的优化问题:
的优化问题:
推导过程可以看最后的图片,这里推荐大家自己推导一遍。
(省略了常数后)
现在的优化目标为:
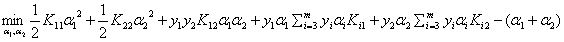
现在的约束条件改成:
s.t. 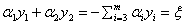 (我们用
(我们用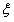 来表示这个数)
来表示这个数)
还有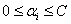
2.取极值时的α2的计算公式
到这里就可以发现,现在的优化目标其实就是一个关于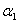 和
和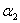 的二次函数...二次函数我们就很熟悉了,求极值的话求导看定义域就好。而且根据于
的二次函数...二次函数我们就很熟悉了,求极值的话求导看定义域就好。而且根据于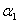 和
和 的约束关系,我们可以把
的约束关系,我们可以把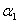 消去。不过我们的目的是为了关于
消去。不过我们的目的是为了关于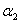 求导,导数为0的点就是我们要找的极值点,所以这里既可以把
求导,导数为0的点就是我们要找的极值点,所以这里既可以把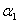 消去后对
消去后对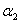 求导,也可以直接在现在这个式子上对
求导,也可以直接在现在这个式子上对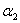 求导。
求导。
这里是直接对α2求导,我自己的推导过程见最后图片,同样最好自己推导一遍。
(注意,对于式子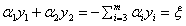 ,我们在用
,我们在用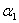 表示
表示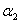 时,等式两边同时乘
时,等式两边同时乘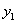 就可以,不要用除以
就可以,不要用除以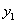 的方式,要时刻记住
的方式,要时刻记住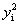 =1)
=1)
现在皆大欢喜,我们得到了新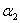 的计算公式:
的计算公式:
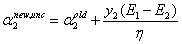
3.是不是需要考虑可行域?
直接用这个公式的值更新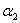 吧!
吧!
可惜是不可以的。
关于这个问题,我觉得在高中就遇到过了。就好比求最值问题,你求导,导函数为0,就能找到最值点了?不是这样的,要时刻考虑定义域!最值点通常要么在极值点处,要么是边界值。如果这个极值点都不在定义域里,我们怎么能直接把它作为最后的结果呢?
所以我们需要看这个问题的定义域,或者说约束问题里的可行域,是什么:
s.t. 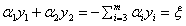
还有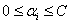
这两个共同决定了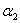 的可行域。那怎么求
的可行域。那怎么求 的可行域呢?可以通过画图来看:
的可行域呢?可以通过画图来看:
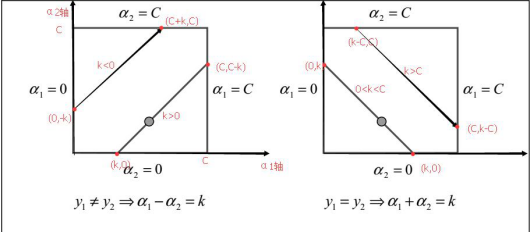
(图片来自SMO的论文。上面这个图一开始可能看不明白,反正我一开始是看的很懵,它竟然连坐标轴都不标...上面把一些边界点给标了出来,可以自己算一算一些坐标的值,真的理解的不一样!图中方形区域就是指 和
和 共同围起来的区域,几条直线就是对应的几种不同
共同围起来的区域,几条直线就是对应的几种不同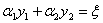 的情况)
的情况)
 这个式子,因为
这个式子,因为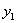 和
和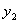 的只能取值+1或者-1,所以其实按照
的只能取值+1或者-1,所以其实按照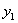 和
和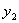 的取值,这个式子有四种情况:
的取值,这个式子有四种情况:
(1)当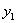 =1且
=1且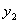 =1时此时的表达式是
=1时此时的表达式是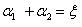 ,那么对应上图中的右边的情况。
,那么对应上图中的右边的情况。
根据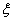 的不同取值,我们可以分为下面几种情况来求
的不同取值,我们可以分为下面几种情况来求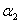 的可行域:
的可行域:
① <0时,因为
<0时,因为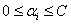 ,所以此时
,所以此时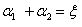 与方形区域一定没有任何交集,所以此时
与方形区域一定没有任何交集,所以此时 的可行域为空集。而且也不会出现
的可行域为空集。而且也不会出现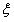 <0的情况,因为
<0的情况,因为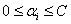 的限制,不可能
的限制,不可能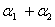 结果小于0
结果小于0
②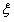 =0时,此时
=0时,此时 ,此时与方形区域的交点就是(0,0),那么可行域就是
,此时与方形区域的交点就是(0,0),那么可行域就是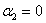
③0< <C时,此时对应上图中右边的靠下的那种直线的情况,所以根据直线和方形区域的相交情况此时可以求出
<C时,此时对应上图中右边的靠下的那种直线的情况,所以根据直线和方形区域的相交情况此时可以求出 的可行区间为[0,
的可行区间为[0,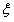 ],即[0,
],即[0,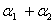 ]
]
④当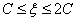 时,可以求出此时对应上图右边情况靠上的那种直线,所以此时可以求出的可行区间为[
时,可以求出此时对应上图右边情况靠上的那种直线,所以此时可以求出的可行区间为[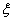 -C,C],即[
-C,C],即[ -C,C]
-C,C]
(上面求可行区间就是看直线和方形区域的交点边界情况,确定的范围,因为既要在直线上,也要在方形区域内)
⑤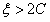 时,可行域为空集,且这种情况也不会发生。
时,可行域为空集,且这种情况也不会发生。
综上所述,当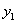 =1且
=1且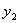 =1时,此时的
=1时,此时的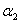 可行域在存在的情况下(即不考虑
可行域在存在的情况下(即不考虑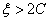 和
和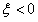 )其实可以这样表示它的区间:
)其实可以这样表示它的区间:
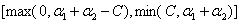
可以来验证一下,当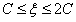 ,
,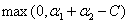 结果是
结果是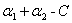 ,
,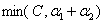 结果是C,和情况④得出来的区间一样。
结果是C,和情况④得出来的区间一样。
(2)当 = -1 且
= -1 且 = -1 时此时的表达式是
= -1 时此时的表达式是 ,那么首先此时的
,那么首先此时的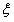 一定是小于等于0的,此时的
一定是小于等于0的,此时的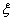 各种分类其实和上面的(1)类似,所以从这个意义上来说,论文图片中的k并不是代表着。
各种分类其实和上面的(1)类似,所以从这个意义上来说,论文图片中的k并不是代表着。
(3)当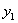 = 1且
= 1且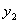 = -1时,此时的表达式是
= -1时,此时的表达式是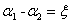 ,那么和之前一样此时我们可以根据
,那么和之前一样此时我们可以根据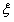 的不同取值来看
的不同取值来看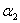 的可行域。
的可行域。
①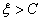 或者
或者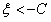 时,很明显此时直线与方形区域没有交点,所以此时
时,很明显此时直线与方形区域没有交点,所以此时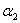 可行域为空集
可行域为空集
②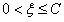 时,此时对应上面的左图中的靠下的那种直线的情况,此时可以计算出
时,此时对应上面的左图中的靠下的那种直线的情况,此时可以计算出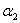 可行域为[0,
可行域为[0,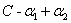 ]
]
③当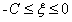 时,此时对应左图中靠上的那种直线的情况,此时可计算出
时,此时对应左图中靠上的那种直线的情况,此时可计算出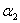 可行域为[
可行域为[ ,C]
,C]
综上所述,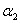 的可行域为
的可行域为
(4)当 = -1且
= -1且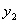 = 1时,情况和(3)类似。
= 1时,情况和(3)类似。
So,我们就可以通过分析这四种情况得到的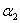 可行域在不同情况下的表示方法:
可行域在不同情况下的表示方法:
当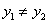 时,
时,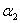 的可行域为
的可行域为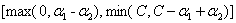 ,区间端点分别为:
,区间端点分别为:
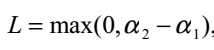
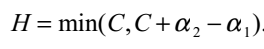
当 时,
时,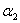 的可行域为
的可行域为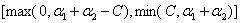 ,区间端点分别为:
,区间端点分别为:
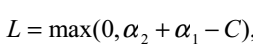
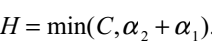
所以在更新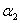 时,要先求出
时,要先求出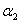 的可行域,然后用之前的那个公式求出极值点
的可行域,然后用之前的那个公式求出极值点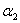 ,然后看极值点
,然后看极值点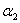 处的在不在可行域范围内,在的话就使用极值点处的
处的在不在可行域范围内,在的话就使用极值点处的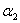 ,不在的话就使用边界值H或者L更新,具体更新规则为:
,不在的话就使用边界值H或者L更新,具体更新规则为:
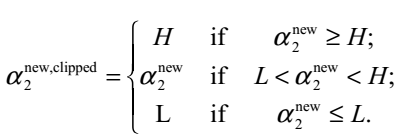
(图来自SMO论文)
这个更新规则怎么理解呢?
注意到我们之前有个假设(写在纸上,在很多推导里也有) 这一项是满足大于0的,而这个系数是原来二次函数的二次项的系数,所以我们可以得到原来的二次项系数大于0,所以这个二次函数是一个开口向上的函数,所以要求这个二次函数的最小值,如果说极值点不在计算出的可行域的范围内,就要根据这个极值点和可行域边界值的关系来得到取最小值的地方。
这一项是满足大于0的,而这个系数是原来二次函数的二次项的系数,所以我们可以得到原来的二次项系数大于0,所以这个二次函数是一个开口向上的函数,所以要求这个二次函数的最小值,如果说极值点不在计算出的可行域的范围内,就要根据这个极值点和可行域边界值的关系来得到取最小值的地方。
①如果这个极值点在可行域左边,那么我们可以得到这个可行域内二次函数一定在单增,所以此时L应该是那个取最小值的地方。就如大括号的第三种情况
②如果这个极值点在可行域右边,那么此时可行域内一定单减,所以此时H就是那个取最小值的地方,就是大括号里的第一种情况。
4.可行域考虑了,二次项的系数也得考虑
但是注意这一切都是在我们假设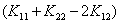 大于0的时候。所以到这里这个最值问题虽然我们已经考虑了可行域问题,但是我们还没考虑原来的二次函数的二次项的系数问题。
大于0的时候。所以到这里这个最值问题虽然我们已经考虑了可行域问题,但是我们还没考虑原来的二次函数的二次项的系数问题。
或者现在我们先回想一下最最简单的函数求最值问题!
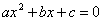
给你这个函数,让你求在区间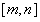 上的最值,怎么求?
上的最值,怎么求?
大概我们一上来就,求导,导数为0,或者不求导了,这种函数有很多公式直接用的,什么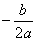 还有
还有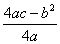 ,只需要注意极值点和区间的关系就好。
,只需要注意极值点和区间的关系就好。
在你求解这个问题之前,不妨想一想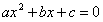 一定是个二次函数吗?如果我让a=0,那是不是就变成了一个一次函数呢?
一定是个二次函数吗?如果我让a=0,那是不是就变成了一个一次函数呢?
所以我们还需要对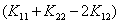 进行讨论!
进行讨论!
之前的关于 那个二次函数的求导后的表达式是这样的:
那个二次函数的求导后的表达式是这样的:
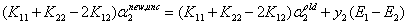
而且我在纸上也写了,这里需要注意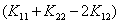 这一项,当时为了推导公式我们直接默认它是大于0了,现在我们需要重新审视这一项。
这一项,当时为了推导公式我们直接默认它是大于0了,现在我们需要重新审视这一项。
而且我们也说过,这一项是原来关于的二次项的系数。我们可以分下面三种情况讨论:
①当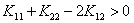 时,就是我们之前说的那样,此时二次函数开口向上,按照
时,就是我们之前说的那样,此时二次函数开口向上,按照
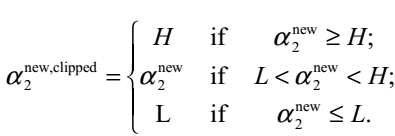
这个规则就可以得到那个可以取到最小值的点
②当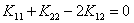 时,此时这个二次函数就变成了一个一次函数,那么不管这个一次函数的单调性怎样,最小值一定是在边界处取到。所以到时候计算可行域的两个边界的值,看哪个小就用哪个
时,此时这个二次函数就变成了一个一次函数,那么不管这个一次函数的单调性怎样,最小值一定是在边界处取到。所以到时候计算可行域的两个边界的值,看哪个小就用哪个
③当 时,此时这个二次函数开口向下了,那么此时怎么得到取最小值的点呢?很容易就能想到:最小值也是在可行域的边界处取到。很容易理解,此时开口向下,当极值点在区间内时,最小值只能在端点处取,因为极值点处是最大的。而当极值点在区间外时,区间内一定是单调的,此时最小值也只能在端点处取。
时,此时这个二次函数开口向下了,那么此时怎么得到取最小值的点呢?很容易就能想到:最小值也是在可行域的边界处取到。很容易理解,此时开口向下,当极值点在区间内时,最小值只能在端点处取,因为极值点处是最大的。而当极值点在区间外时,区间内一定是单调的,此时最小值也只能在端点处取。
所以当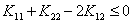 时,就需要通过计算比较边界处的目标函数值,哪个小取哪个。
时,就需要通过计算比较边界处的目标函数值,哪个小取哪个。
关于这部分内容主要是看到http://blog.csdn.net/luoshixian099/article/details/51227754才知道的,所以很感谢这位博主。在SMO算法论文中也提到了。
那怎么计算可行域边界上的目标函数值呢?以计算边界H上的值为例,就是把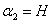 代入到目标函数的式子中,或者说先利用计算
代入到目标函数的式子中,或者说先利用计算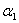 新值的公式:
新值的公式:
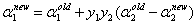
求出新的 ,然后代入到关于
,然后代入到关于 和
和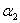 的目标函数式子中。
的目标函数式子中。
(这个公式可以通过利用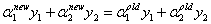
这个式子推出来,注意什么时候是新值,什么时候是旧值)
然后在SMO论文中给出了具体的求值公式,这里粘贴出来:
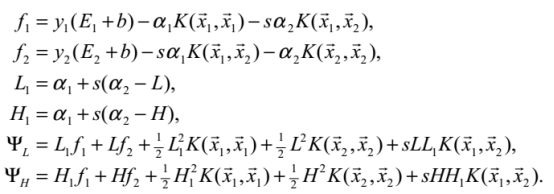
自己也可以推一下,其实就是把原来的式子用它给出来的定义的式子表示出来。而且需要注意的是上面公式中的 和
和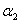 都表示旧值!所以在这里计算需要注意什么时候是新值什么时候表示旧值,这个在看了算法的具体实现后可能理解的更深。
都表示旧值!所以在这里计算需要注意什么时候是新值什么时候表示旧值,这个在看了算法的具体实现后可能理解的更深。
5.总结一下如何解决两个变量的二次规划问题
到这里,我们其实就知道了如何更新一对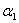 和
和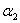 :
:
①求出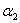 的可行域
的可行域
②根据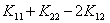 这一项和0的关系:
这一项和0的关系:
如果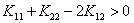 ,那么就直接利用之前求好的公式求出新的极值点处的
,那么就直接利用之前求好的公式求出新的极值点处的 ,然后看这个
,然后看这个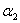 和可行域的关系,得到
和可行域的关系,得到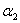 的新值
的新值
如果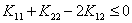 ,那么就直接求出H和L对应的边界值,哪个小,就让
,那么就直接求出H和L对应的边界值,哪个小,就让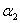 取哪个值
取哪个值
③根据新的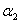 求出新的
求出新的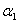
④更新ω很简单,现在还需要说一下b的更新:
但是我目前对b的更新还是有很多疑问,论文中也没解释太清楚。
在每一次更新完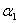 和
和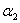 后,还需要更新阙值b,如果某个α更新完后是满足是一个支持向量的参数,即α满足在0和C之间,不包括0和C,这时称根据这个α求出来的b是比较准确的。b可以通过支持向量满足的性质:
后,还需要更新阙值b,如果某个α更新完后是满足是一个支持向量的参数,即α满足在0和C之间,不包括0和C,这时称根据这个α求出来的b是比较准确的。b可以通过支持向量满足的性质: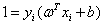 来计算,所以可以通过公式:
来计算,所以可以通过公式:
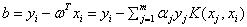
但是在实际计算时,论文中是使用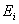 ,
,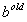 ,
,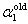 ,
,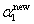 ,
,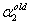 和
和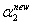 表示的
表示的 ,这里还是先以
,这里还是先以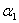 和
和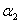 为例,给出计算
为例,给出计算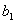 的公式
的公式
具体推导时,使用了
①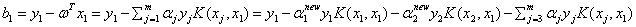
②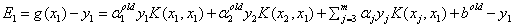
尤其注意b值的在使用支持向量的性质更新时,参数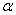 使用的是更新后的,而在实际计算时,Ei都是使用之前存好的,所以它使用的肯定是旧的参数,
使用的是更新后的,而在实际计算时,Ei都是使用之前存好的,所以它使用的肯定是旧的参数,
①和②中的关于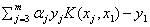 的部分可以约去,约去后,得到了
的部分可以约去,约去后,得到了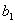 的最终计算公式:
的最终计算公式:

这个计算出的公式和SMO论文中的却有很大的出入...具体和论文中出入的地方在于计算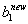 的后三项系数相反。目前还不知道原因所在...
的后三项系数相反。目前还不知道原因所在...
在网上查资料也发现有的推导出来是我推导出的形式,但也有的是论文中的式子。
不过还发现《机器学习实战》中的SMO代码中b的计算是我推出来的这个式子不是原文中的式子。所以目前就以我写的这个式子为准。
但是注意到上面这个计算公式是建立在α更新完后对应一个支持向量,才可以用支持向量的性质来推这个公式。其他的更新完后不是支持向量了该怎么计算??论文中似乎统一都用这个公式计算了?所以这里我不太理解论文中的意思,有谁知道论文中b的具体计算请帮我解答一下!
二.选择两个α的方法
OK,SMO一部分说完了,另一部分就是如何找到这样的一对和。
在SMO原文中有很多段话来描述它的启发式的寻找算法,我觉得在看的过程中需要结合它的给出的算法伪码看可能会更加清楚。现在我就把一些细节的地方分享一下。
关于寻找的过程,首先就是文中提到了《An Improved Training Algorithm for Support Vector Machine》这篇论文中说到优化违反KKT条件的参数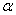 可以减少目标函数的值,但是具体的证明没看太懂,有时间再看。
可以减少目标函数的值,但是具体的证明没看太懂,有时间再看。
所以说我们在寻找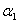 和
和 时,就是要找那些违反KKT条件的。具体的过程分为寻找第一个要修改的参数,即外层循环和寻找第二个要修改的参数,即内层循环。
时,就是要找那些违反KKT条件的。具体的过程分为寻找第一个要修改的参数,即外层循环和寻找第二个要修改的参数,即内层循环。
找第一个参数的具体过程是这样的:
①遍历一遍整个数据集,对每个不满足KKT条件的参数,选作第一个待修改参数
②在上面对整个数据集遍历一遍后,选择那些参数满足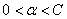 的子集,开始遍历,如果发现一个不满足KKT条件的,作为第一个待修改参数,然后找到第二个待修改的参数并修改,修改完后,重新开始遍历这个子集
的子集,开始遍历,如果发现一个不满足KKT条件的,作为第一个待修改参数,然后找到第二个待修改的参数并修改,修改完后,重新开始遍历这个子集
③遍历完子集后,重新开始①②,直到在执行①和②时没有任何修改就结束
(为什么要这样遍历,我现在还是不太明白)
找第二个参数的过程是这样的:
①启发式找,找能让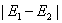 最大的
最大的
②寻找一个随机位置的满足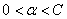 的可以优化的参数进行修改
的可以优化的参数进行修改
③在整个数据集上寻找一个随机位置的可以优化的参数进行修改
④都不行那就找下一个第一个参数
大致它给出的伪码也是这样的。
关于它伪码中的对不满足KKT条件的判断:


我是这么理解的:
如果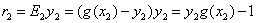
它满足<-tol 意味着: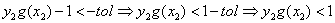
那么它对应的参数要满足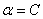 ,而如果不满足,即后面的判断条件
,而如果不满足,即后面的判断条件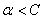 ,那么就表示不满足KKT条件,需要更新了
,那么就表示不满足KKT条件,需要更新了
而它满足 >tol 意味着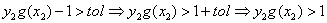
那么它对应的参数必须要满足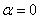 ,不满足的话也需要更新了
,不满足的话也需要更新了
但是这里没考虑当r2==0时,需要让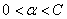 ??不懂
??不懂
附录:
①推导关于α1和α2的目标函数的式子:

②关于α2的求导推导:



