[Wireshark Lab v8.1] HTTP Lab
[Wireshark Lab v8.1] Lab 翻译与解题.
以下实验步骤均来自实验指导手册。
实验指导手册下载地址:Jim Kurose Homepage (umass.edu)
Lab HTTP
在熟悉了 Wireshark 报文嗅探器的使用之后, 我们可以使用该软件做一些实际协议的分析. 这个 lab 将会探索 HTTP 协议, 包括基本的 GET/响应交互, HTTP 消息格式, 获取大 HTML 文件及带内嵌对象的 HTML 文件和 HTTP 安全和权限控制. 在开始 lab 之前, 你可能需要重新回顾一下书籍中 2.2 章节的内容.
1. HTTP 基本的请求和响应交互.
首先通过一个简单的 HTML 文件来开始吧
- 打开浏览器
- 打开 Wireshark, 并使用 http filter.
- 等待超过一分钟的时间, 然后开始 Wireshark 抓包
- http://gaia.cs.umass.edu/wireshark-labs/HTTP-wireshark-file1.html ,将 url 输入到浏览器中, 应该看到一行简单的 html 文件
- 关闭抓包
你的软件结果应该类似于图1, 如果你无法进行抓包, 也可以到官网下载, 使用预先抓好的文件.
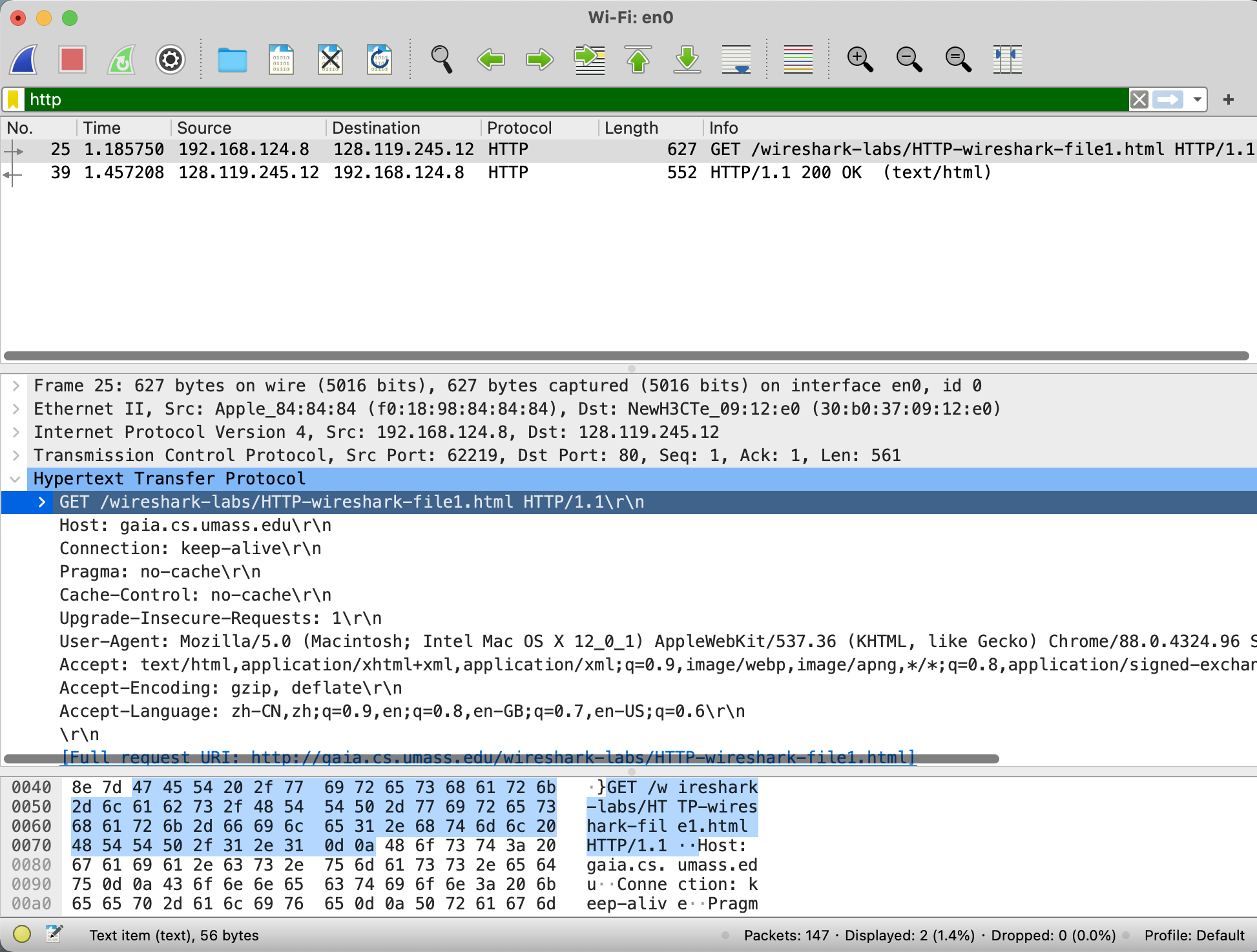
图1的例子显示了会有两个http报文被抓取到. GET 请求报文, 由浏览器向服务器发送, 响应报文, 由服务器发送给浏览器. 报文内容窗口展示了选中报文的细节(这个例子中是 HTTP OK 的响应报文). 回忆 HTTP 报文是被包裹在 TCP 报文段中, 又被 IP 数据报包裹, 最终封装成以太网帧, Wireshark 也全部展示了 数据帧, 以太网报头, IP 报头, TCP 报头的信息. 我们现在关注的重点是 HTTP 协议(后续协议通过其他lab查看), 因此将非 HTTP 协议的报文头都缩放, 只保留 HTTP 报文头.
通过观察 HTTP GET 和响应消息, 回答下列问题:
- 你的浏览器运行的 HTTP 版本是多少(1.0, 1.1, 2)? 服务器的版本呢?
- 你的浏览器指示的接收语言是什么(如果有)?
- 你的计算机的IP地址是多少? gaia.cs.umass.edu 服务器的地址呢?
- 服务器返回响应的状态码是多少?
- 服务器响应 html 文件的最后一次修改时间是多少?
- 返回给你的浏览器的响应消息的长度是多少?
- 通过查看packet content中的原始数据, 你能否看到数据中有些头信息没有在 packet listing中显示? 如果有, 举例说明.
当回答问题5时(假设是运行软件而不是使用trace文件), 你可能会发现最后一次修改时间在下载文件的一分钟以内, 这是因为对这个特定文件, 服务器每分钟一次将其设置为当前时间. 因此如果你等待超过一分钟再去访问, 文件就会被修改, 然后浏览器就会下载“新”的文件拷贝.
译者PS: 这里要注意下时区问题, 我获得的时间头是 Date:Wed, 18 May 2022 05:07:10 GMT, 是格式化的文本时间, 而不是时间戳, 可能的原因就是服务器所在时区不同, 时间戳也应该有偏差, 所以使用GMT标准时间对齐, 我们所处时区通常是 GMT+8, 因此当地时间减去8小时就是标准时间.
2. HTTP 条件 GET请求和交互
回忆书本中第 2.2.5 段, 大多数的 web 服务器使用对象缓存技术, 因此通常会在获取 HTTP 对象时进行条件 GET 请求. 在进行下列步骤前, 确保你的浏览器缓存被清空.(PS: chrome 下打开 devtool, 网络选项卡, 点击 禁用缓存 再发请求即可)
- 打开浏览器, 确保浏览器缓存被清空.
- 打开 wireshark 软件, 开始抓包
- http://gaia.cs.umass.edu/wireshark-labs/HTTP-wireshark-file2.html 输入url, 浏览器应该显示5行的html内容
- 重新输入这个url(或者刷新, 这里也可以使用硬刷新, 同样不走缓存)
- 抓包完成, 使用 http 过滤
同样的, 如果你无法抓包, 可以使用提供的 trace 文件, 回答下列问题,
- 检查浏览器发出的 GET 请求, 是否有 IF-MODIFIED-SINCE 标头?
- 检查服务器响应的内容, 服务器是否显式的返回了文件的内容, 你是怎样确定的?
- 现在检查第二次 GET 请求, 是否有 IF-MODIFIED-SINCE 标头? 如果有, 它的内容是什么
- 服务器对第二次 GET 请求的响应是什么》 服务器是否显式的返回了文件的内容? 作出解释
3. 获取长文档
到当前位置的例子中, 获取的文档都是简单且短的 HTML 文件. 接下来我们来演示下载一个长的 HTML 文件会发生什么
- 打开浏览器, 确保浏览器缓存被清空.
- 打开 wireshark 软件, 开始抓包
- http://gaia.cs.umass.edu/wireshark-labs/HTTP-wireshark-file2.html 输入url, 浏览器应该显示一段相对较长的 Bill of Rights 文本.
- 停止抓包
在数据包列表窗口中,您应该会看到您的 HTTP GET 消息,然后是对您的 HTTP GET 请求的多数据包 TCP 响应。确保您的 Wireshark 显示过滤器已清除,以便多数据包 TCP 响应将显示在数据包列表中。
这种多包响应值得解释一下。回想一下 2.2 节(参见正文中的图 2.9),HTTP 响应消息由一个状态行、后跟标题行、后跟空行和实体正文组成。对于我们的 HTTP GET,响应中的实体主体是整个请求的 HTML 文件。在我们这里的例子中,HTML 文件相当长,并且 4500 字节太大而无法放入一个 TCP 数据包中。因此,单个 HTTP 响应消息被 TCP 分成几个部分,每个部分包含在一个单独的 TCP 段中(参见文本中的图 1.24)。在最近版本的 Wireshark 中,Wireshark 将每个 TCP 段表示为一个单独的数据包,并且单个 HTTP 响应被分成多个 TCP 数据包的事实由 Wireshark 显示的 Info 列中的“重新组装 PDU 的 TCP 段”指示.
回答如下问题:
- 多少次 HTTP GET 请求被发送了? 包含 Bill of Rights 的请求在trace中的报文编号是多少?
- trace 中对应响应的包含状态码和相关短语(就是状态码对应的描述字符串, 如200对应OK)的那个报文编号是多少?
- 响应的状态码和短语是什么?
- 完全传输 Bill of Right 单次 HTTP 响应需要多少个 TCP 报文段
(PS: 这里涉及到TCP拆包和合并的问题, 如果去掉http filter应该是有3个tcp, 1个http响应, 最后http响应的实际内容只有末尾部分, 但逻辑上与前三个tcp响应组成一次完整的http响应, 也可以在软件中看到完整的响应内容)
4. HTML 文档和内嵌对象
这次来实验一次响应携带了其他内嵌对象(如一个带有其他服务器上存储的图片的HTML)
对 http://gaia.cs.umass.edu/wireshark-labs/HTTP-wireshark-file4.html 进行抓包, 你应该能看到包含两个图片的html文件, 一个图片存放在当前服务器上, 另一个书本封面图片存放在 https://kurose.cslash.net/8E_cover_small.jpg 另外服务器上面.
回答如下问题:
- 多少次 HTTP GET 请求被发出? 发送到那个IP地址上?
- 你能解释你的浏览器是串行下载两个图片的, 还是并行从两个服务器上下载的? 请解释.
这里解释下我的行为:
总共有4次请求被发出, 获取html和第一张图片是发送给 gala.cs.umass.edu 的, 后面两次是在 kurose.cslash.net 请求图片, 由于http被重定向到了https, 因此有两次请求. 其中两张图片的请求是并行发出的, 但由于第二张图片被重定向走了, 所以看起来像是顺序发出的请求, (可以到devtool里看请求流水线)
5. HTTP Authentication
最终, 让我们来实验一个被密码保护了的网站来演示HTTP报文是如何交换的. 通过抓 http://gaia.cs.umass.edu/wireshark-labs/protected_pages/HTTP-wireshark-file5.html , 用户名和密码分别是 “wireshark-students” 和 “network” 不带引号.
在解析 Wireshark 的输出前, 你可能需要阅读一下 HTTP 权限的一篇材料文章.
回答如下问题:
- 首次http get请求的服务器响应(状态码和短语)是多少?
- 当浏览器第二次发送请求, 什么新字段被添加到请求头?
您输入的用户名(wireshark-students)和密码(网络)在客户端 HTTP GET 消息中的“Authorization: Basic”标头后面的字符串 (d2lyZXNoYXJrLXN0dWRlbnRzOm5ldHdvcms=) 中编码。虽然您的用户名和密码看起来可能已加密,但它们只是以一种称为 Base64 格式的格式进行编码。用户名和密码未加密!要查看此内容,请访问 http://www.motobit.com/util/base64-decoder-encoder.asp 并输入 base64 编码的字符串 d2lyZXNoYXJrLXN0dWRlbnRz 并进行解码。瞧!您已从 Base64 编码转换为 ASCII 编码,因此应该会看到您的用户名!要查看密码,请输入字符串 Om5ldHdvcms= 的其余部分,然后按解码。由于任何人都可以下载像 Wireshark 这样的工具并嗅探通过其网络适配器的数据包(不仅仅是他们自己的),并且任何人都可以将 Base64 转换为 ASCII(您刚刚做到了!),您应该清楚 WWW 上的简单密码除非采取额外措施,否则网站并不安全。
不要害怕! 正如我们将在第 8 章中看到的,有一些方法可以使 WWW 访问更加安全。 然而,我们显然需要一些超越基本 HTTP 身份验证框架的东西!


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 【译】Visual Studio 中新的强大生产力特性
· 【设计模式】告别冗长if-else语句:使用策略模式优化代码结构
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义