PyTorch笔记--自动调整学习率
我们在训练的过程中,经常会出现loss不再下降的问题,但是此时gradient可能并没有很小,并非处于驻点。
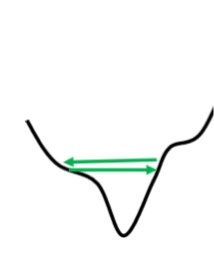
可能是出现了梯度在山谷的山谷壁之间来回震荡的情况。gradient依然很大,但是loss不再减小了。
整个训练过程中,每个参数都一直使用同一个学习率,对于优化而言是不够的。学习率调整的原则是,如果在某一个方向上,gradient值很小,代表函数在
这里十分的平坦,我们会希望将learning rate调大一点,如果在某一个方向上非常地陡峭,梯度比较大,我们希望这里的learning rate调小一点。
Adagrad

当前参数的梯度:
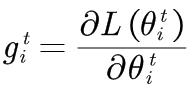
segema是Gradient的平方和如平均再开根号,i是代表第i个参数,t是当前的更新次数。
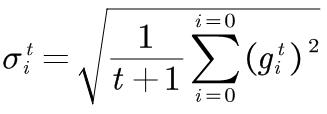
学习率:
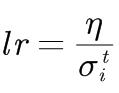
参数更新:
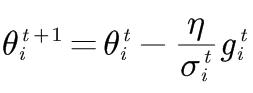
RMSProp
在RMS Prop裡面,它决定你可以自己调整,现在的这个gradient,你觉得它有多重要。alpha一般取在0.9左右。
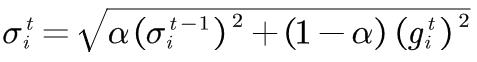
参数更新:
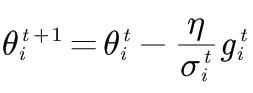
Adam
Adam算法整合了动量和速度。beta1默认取值0.9,beta2默认取值0.999。
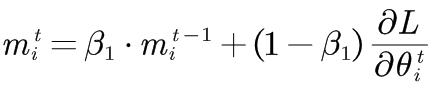

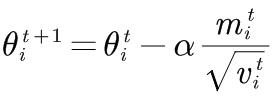

 浙公网安备 33010602011771号
浙公网安备 33010602011771号