PyTorch笔记-Small Batch VS Large Batch
下面是李宏毅老师总结的表格。小批次和大批从中的这个大和小的概念指的是一个批次中数据个数的多少。
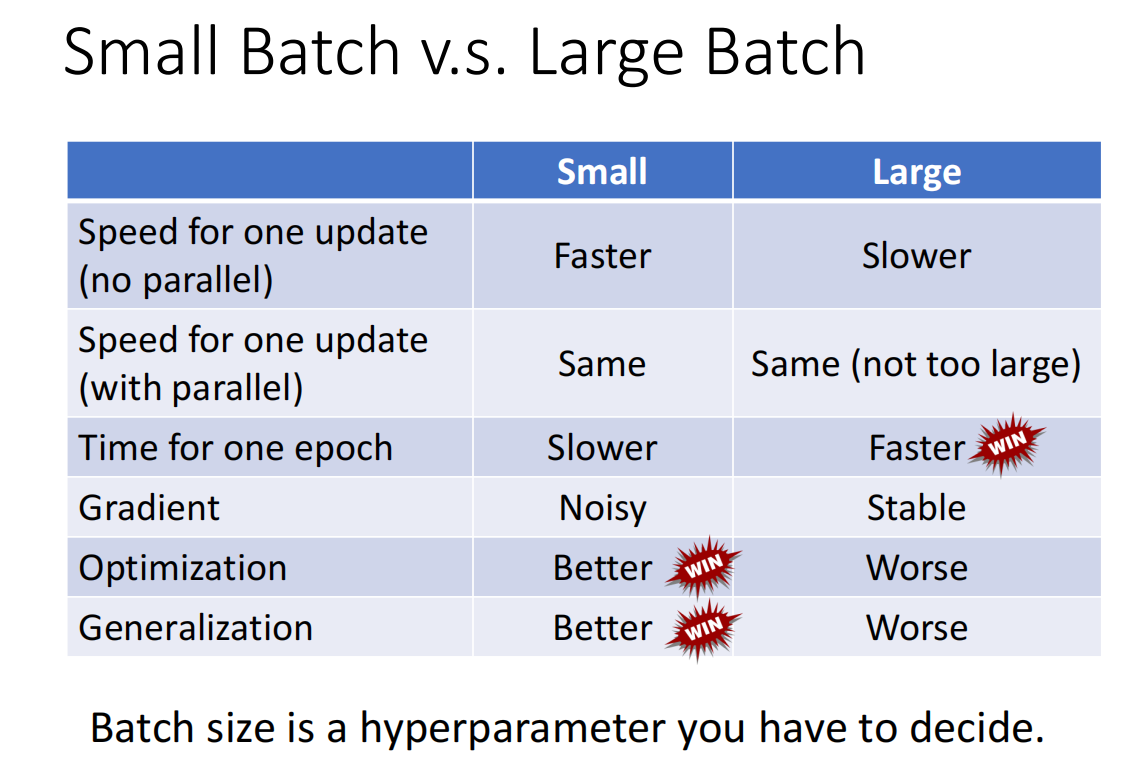
下面内容是对这个表格的解释。
①在无并行处理的情况下,小批次的数据处理的更快,大批次的数据处理地慢一些(处理完一次后就进行一次参数的更新)。
②GPU具有并行处理数据的能力,在并行处理的情况下,小批次数据和大批次数据的处理时间是差不多的(处理完一次后就进行一次参数的更新)。
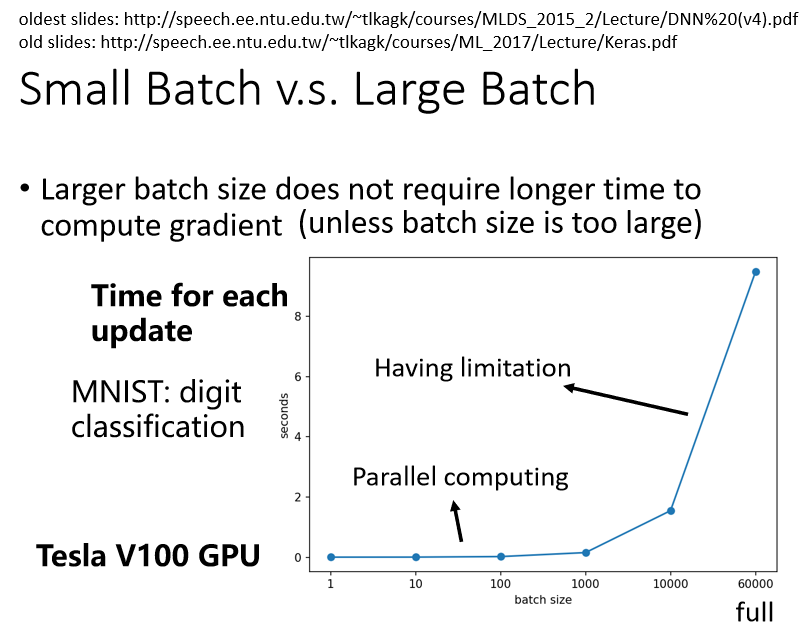
如下图所示,当batch_size<1000时,GPU在处理的时间上并没有太多的差别。但是超过1000后所需的处理时间会增加很多。所以上面说
的大批次的数值也是有限制的。
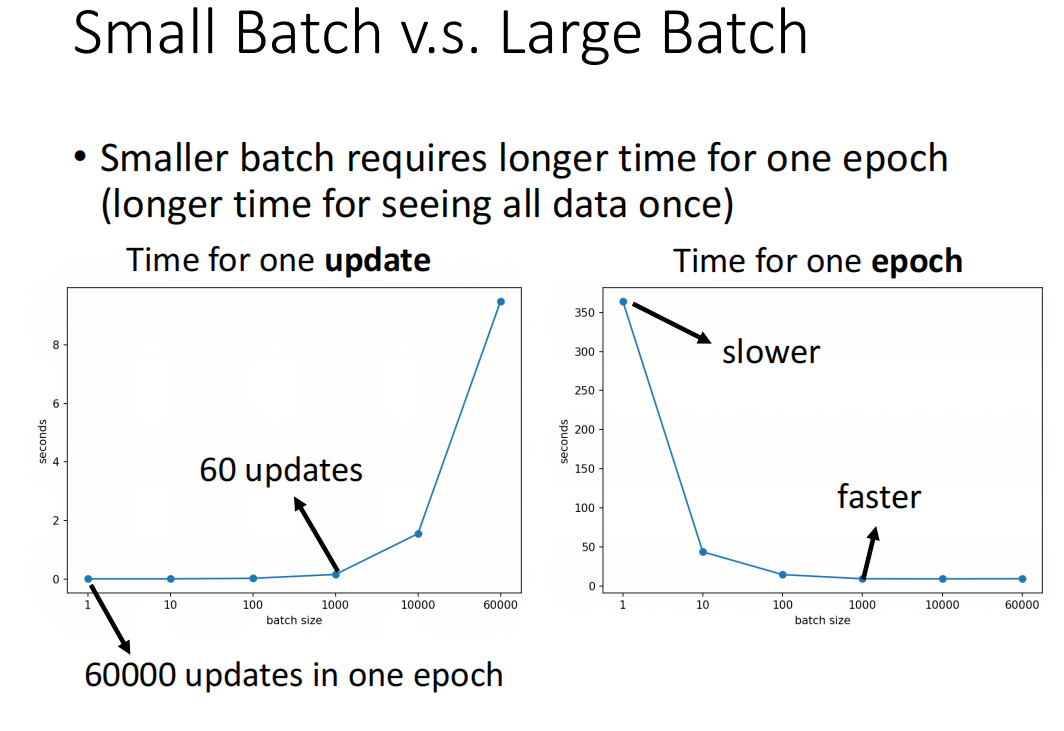
③如果使用大批次数据,处理完一个epoch它花费的时间比使用小批次数据要少。对同一个数据集而言,如果使用小批次数据,那么批次的数量就会多,
每处理完一个批次就进行一次参数的更新,所以它的参数更新次数会更多,所需的时间也会更多。假设有60000个数据,如果batch_size=1,就需要60000
次更新,如果batch_size=1000,一个epoch只需要60次的参数更新。所以batch_size过小会导致更新次数过多,从而处理时间会变长。
④使用大批次数据,梯度的变化是稳定的。使用小批次数据,梯度变化是相对不稳定的。采用小批次数据的话,在处理过程中会有更多次的
梯度变化,而且由于依据的数据量相对较少,所以它会有不稳定的特征。
⑤在优化方面,使用小批次数据更利于优化。
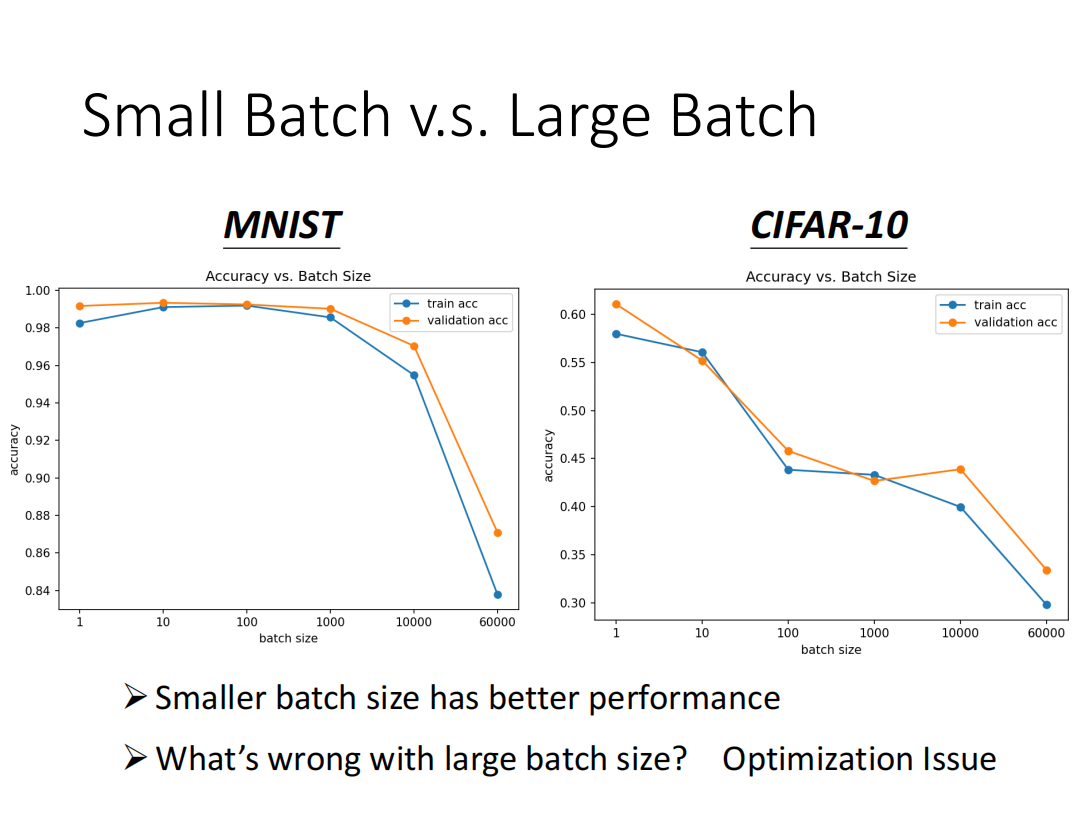
- 横轴代表的是 Batch Size,从左到右越来越大
- 纵轴代表的是正确率,越上面正确率越高
从图上可以看出,在训练的时候,当batch_size增大到一定程度时,数据集上的准确率会逐渐下降。
可以理解成使用小批次的数据,得到的梯度具有不稳定的特点,它不容易在梯度为零的地方卡住。
⑥使用小批次数据具有更好的泛化能力,即它在测试集上也有更好的表现。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号