PyTorch笔记--shuffle=True
在机器学习中,我们会将数据集分成很多个批次来训练。每次抛出一个批次的数据来计算损失函数,再根据损失函数计算参数的梯度。
再根据梯度来更新参数。然后数据加载器会接着抛出下一个批次的数据来计算损失函数,。。。
如下图所示,起初随机选择一个参数的初值theta0。损失函数L1是参数theta0的表达式,根据第一个批次的数据计算L1,并对theta0求导求出梯度g,
根据梯度更新theta0,更新后的参数是theta1。损失函数L2现在是theta1的表达式,根据第二个批次的数据计算L2,并对theta1求导计算出梯度g后
再更新参数。不断这样的执行下去。直至所有的批次都被计算完。
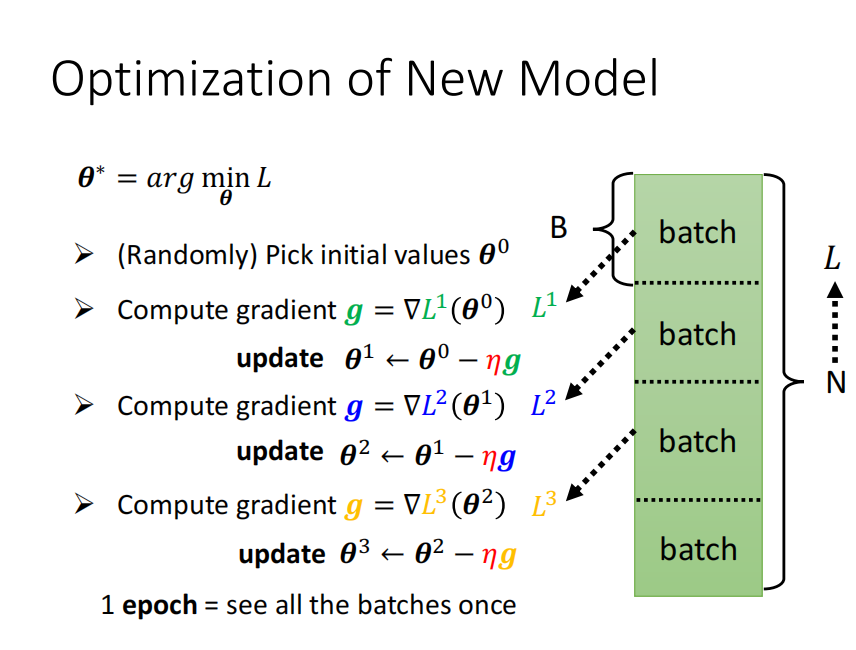
所有的批次的数据都遍历一遍叫做一个epoch。shuffle是洗牌的意思,它就是说在一个epoch之后,对所有的数据随机打乱,再按照设定好的每个批次
的大小划分批次。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号