Python笔记--文本处理
使用os模块导航文件系统
下面是一些会用到的函数相关描述
| 函数名 | 说明 |
| os.getcwd() | 返回当前目录 |
| os.listdir(directory) | 返回directory下的文件名和子目录列表 |
| os.stat(path) |
返回一个数值元组,该元组给出任何您可能需要的关于文件(或目录)的信息。 st_mode:文件的访问权限 st_ino:节点数(UNIX) st_dev:设备号 st_nlink:链接号(UNIX) st_uid:所有者的用户id st_gid:所有者的组id st_size:文件的大小 st_atime:最后访问时间 st_mtime:最后修改时间 st_ctime:创建时间 |
| os.path.split(path) | 将路径分割为符合当前操作系统的组成名称。返回一个元组,不是一个列表。 |
| os.path.join(components) | 将名称连接成一个符合当前操作系统的路径。 |
| os.path.normcase(path) | 规范化路径的大小写。(Windows下会将路径中的字母全部转换成小写,斜杠转换成反斜杠) |
|
os.walk(top, topdown=True, onerror=None, followlinks=False) |
自上而下或自低而上迭代目录树。对于每一个目录,它创建一个由dirpath,dirnames, 和filenames组成的三元组。dirpath是一个保存目录路径的字符串,dirnames是dirpath 中子目录的列表,不包含'.'和'..',filenames是dirpath中非目录文件的列表。 |
示例:列出文件并处理路径,'.'是当前路径的简单表示。
>>> import os, os.path >>> os.getcwd() 'D:\\我的文件\\学习\\python\\learn' >>> os.path.split(os.getcwd()) ('D:\\我的文件\\学习\\python', 'learn') >>> os.stat('.') os.stat_result(st_mode=16895, st_ino=47287796087518476, st_dev=3363062031, st_nlink=1, st_uid=0, st_gid=0, st_size=4096, st_atime=1630222468, st_mtime=1630167294, st_ctime=1629630327) >>> os.listdir('.') ['.idea', 'food.py', 'function.py', 'myPackage', 'test.py', 'test.txt', 'test1.py', 'text.py', '__pycache__']
示例:搜索特殊类型的文件
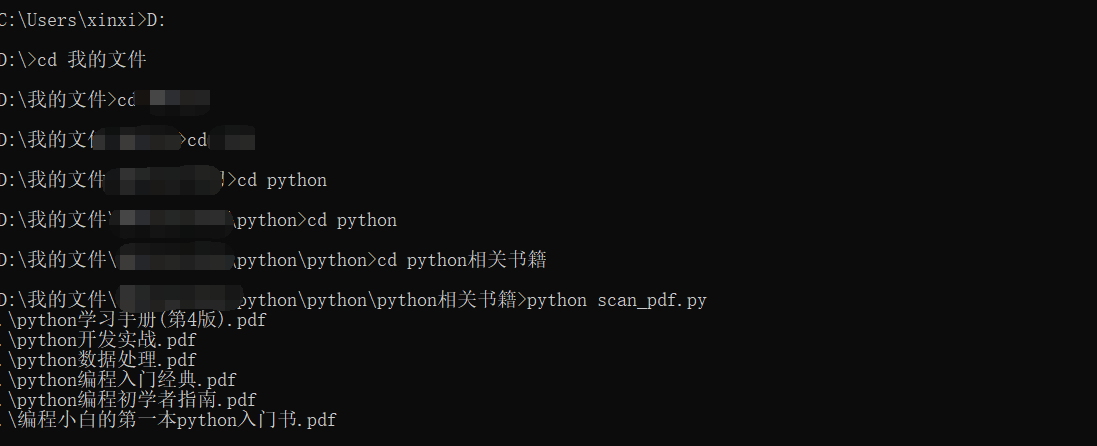
import os import os.path import re def print_pdf(root, dirs, files): for file in files: path = os.path.join(root, file) path = os.path.normcase(path) if re.search(r'.*\.pdf', path): print(path) for root, dirs, files in os.walk('.'): # 这里是当前路径,也可以改为别的路径中搜索 print_pdf(root, dirs, files)
如果想要在别的目录下执行该脚本文件,可以直接在程序中修改for循环下的路径,或者从桌面打开cmd一步步用cd进入到文件夹下。执行文件夹下的scan_pdf.py文件。
如果此处直接在想要的文件下打开cmd执行,会提示错误。
使用正则表达式和re模块
*和?都是通配符,正则表达式和通配符之间存在两个主要的不同。
- 正则表达式可以在长字符串的任何位置匹配多次。
- 正则表达式比通配符复杂得多,也丰富得多。
同时,要注意字符串是与它自身匹配的。
可以加入特殊字符使模式匹配更由意义。最常用的一个特殊字符是一般的通配符"." ,句点匹配字符串中的任何一个字符,“x.x”可以匹配
“xyx”,“xxx”,“x.x”等等。
如果只是想要句点作为普通的符号存在,而不作为统配符存在,可以通过在其前面加反斜杠取消它的特殊意义。比如"x\.x"。
在字符串前加个r,去掉反斜杠的转义机制,比如\n、\t。
>>> import re >>> s = {'xxx', 'abcxxxabc', 'xyx', 'abc', 'x.x', 'axa', 'axxxxxxa', 'axxya', 'axaxxxba'} >>> a = filter((lambda s: re.match(r"xxx", s)), s) >>> print(*a) xxx >>> b = filter((lambda s: re.search(r"xxx", s)), s) >>> print(*b) axxxxxxa xxx abcxxxabc axaxxxba
re.match只从开头开始匹配,re.search是对整个字符串都进行匹配。
r“x.x”
>>> s = {'xxx', 'abcxxxabc', 'xyx', 'abc', 'x.x', 'axa', 'axxxxxxa', 'axxya', 'axaxxxba'}
>>> c = filter((lambda s: re.search("xxx", s)), s)
>>> print(*c)
axxxxxxa xxx abcxxxabc axaxxxba
r"x\.x"
>>> d = filter((lambda s: re.search(r"x\.x", s)), s) >>> print(*d) x.x
r"x.*x",两个x之间有0个或者更多个字符。
>>> s = {'xxx', 'abcxxxabc', 'xyx', 'abc', 'x.x', 'axa', 'axxxxxxa', 'axxya', 'axaxxxba'}
>>> e = filter((lambda s: re.search(r"x.*x", s)), s)
>>> print(*e)
axxxxxxa xxx axxya xyx x.x abcxxxabc axaxxxba
r"x.+x",两个x之间有字符
>>> s = {'xxx', 'abcxxxabc', 'xyx', 'abc', 'x.x', 'axa', 'axxxxxxa', 'axxya', 'axaxxxba'}
>>> f = filter((lambda s: re.search(r"x.+x", s)), s)
>>> print(*f)
axxxxxxa xxx xyx x.x abcxxxabc axaxxxba
r"c+" ,匹配其中有一个c的任何字符串
>>> import re >>> s = {'xxx', 'abcxxxabc', 'xyx', 'abc', 'x.x', 'axa', 'axxxxxxa', 'axxya', 'axaxxxba'} >>> g = filter((lambda s: re.search(r"c+", s)), s) >>> print(*g) abc abcxxxabc
r"[^c]*",正则表达式使用方括号表示要匹配的特殊字符集,如果在列表的开头有"^"代表不出现在集合中的所有字符。
>>> s = {'xxx', 'abcxxxabc', 'xyx', 'abc', 'x.x', 'axa', 'axxxxxxa', 'axxya', 'axaxxxba'}
>>> h = filter((lambda s: re.search(r"[^c]*", s)), s)
>>> print(*h)
abc xyx axxxxxxa xxx axaxxxba axa x.x abcxxxabc axxya
这个正则表达式只要在字符串中找到一个不为c的字母就认为这个字符串符合要求。
r"^[^c]*$",匹配从头到尾不包含c的字符串。
>>> i = filter((lambda s: re.search(r"^[^c]*$", s)), s) >>> print(*i) xyx axxxxxxa xxx axaxxxba axa x.x axxya

 浙公网安备 33010602011771号
浙公网安备 33010602011771号