

李宏毅机器学习笔记16(Reinforcement Learning)
Reinforcement Learning
1、什么是强化学习
2、如何实现强化学习(方法)
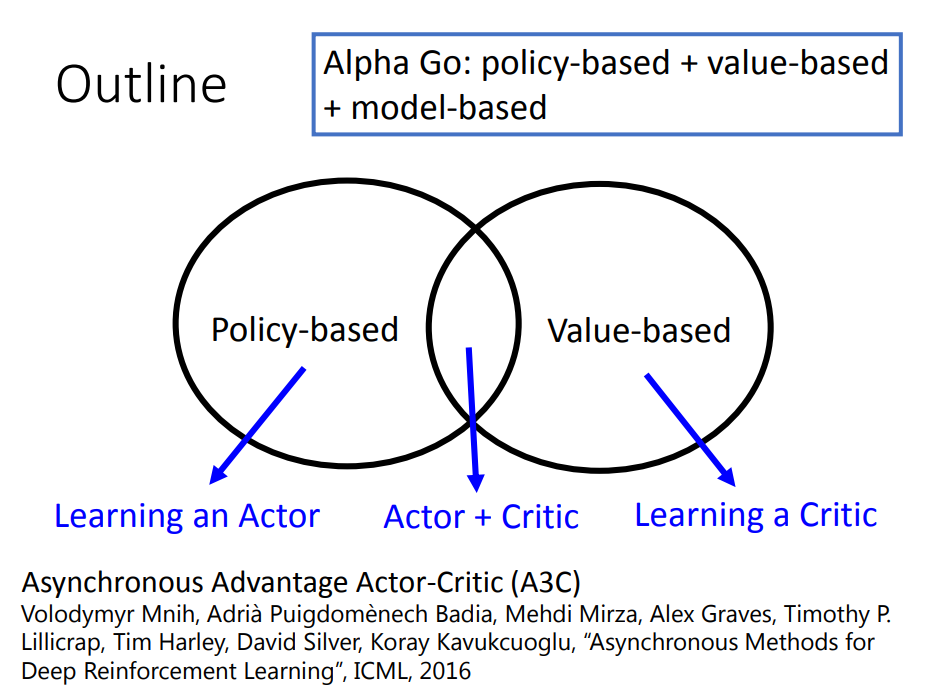
Policy-based:(learn a actor) 代表算法:Policy-Gradient
Value-based:(learn a critic) 代表算法:Deep-Q-Learning
Actor-Critic: 代表算法:A3C
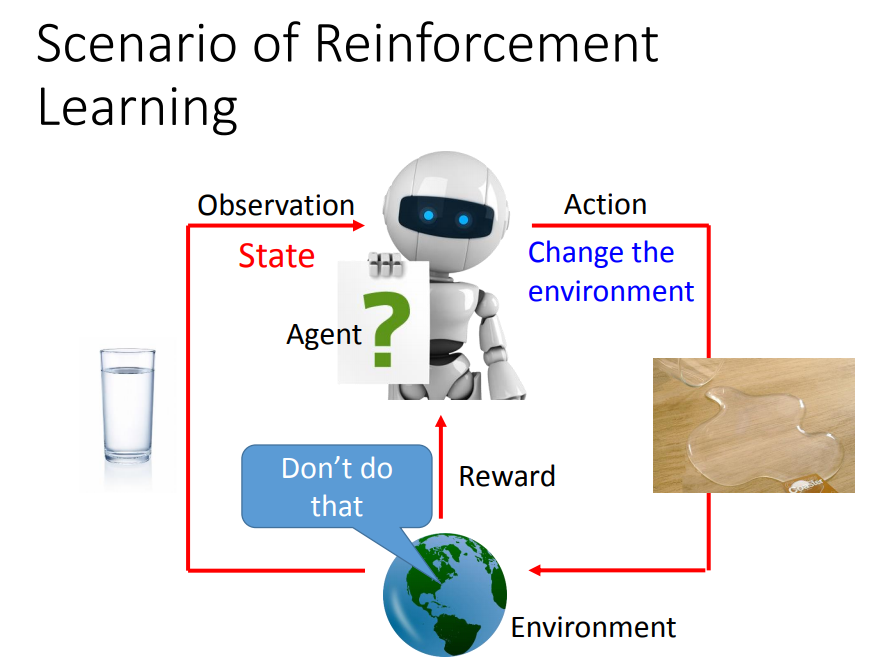
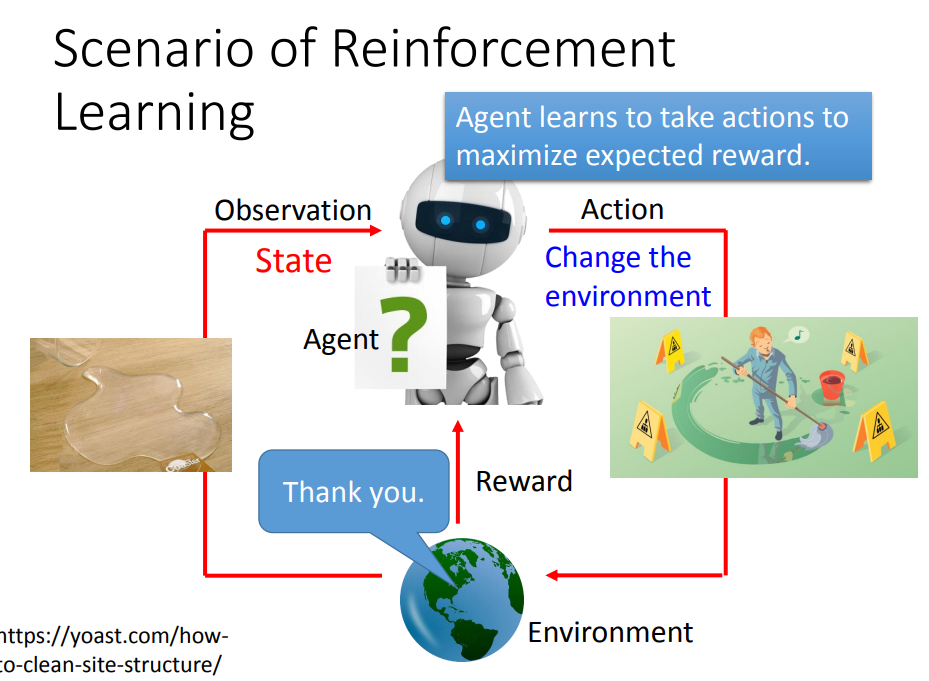
1、什么是强化学习
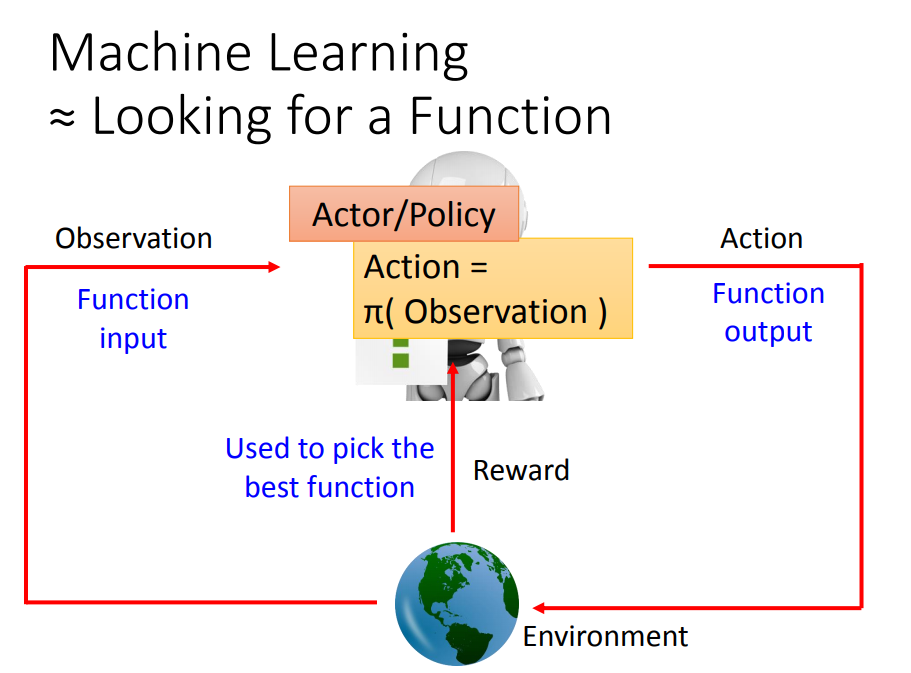
寻找一个function:
输入:观察到的环境状态
输出:action
目标:最大化累计回报(reward)
1、强化学习的应用:
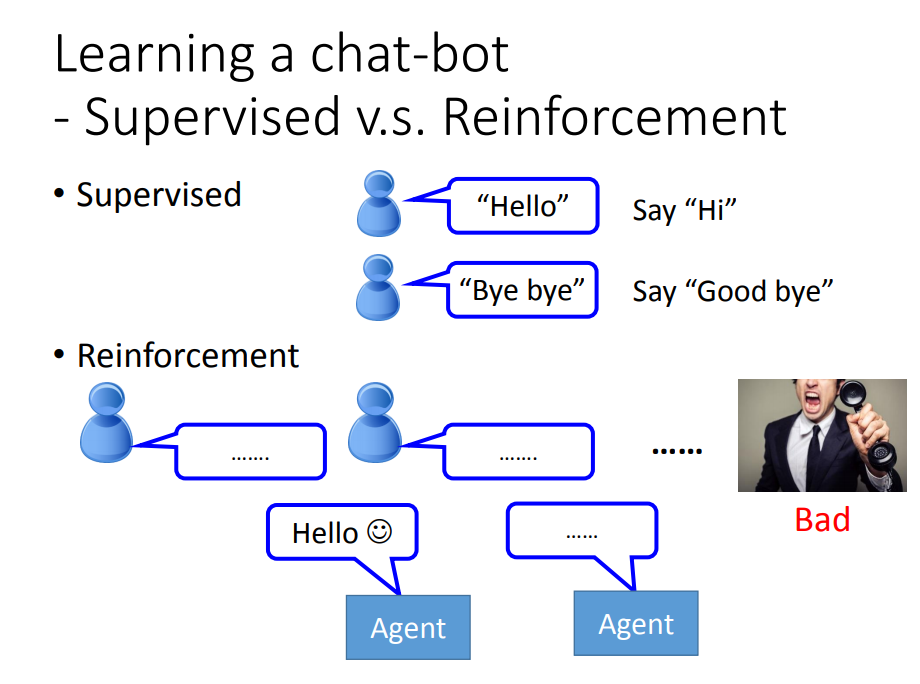
2、强化学习与监督学习的对比:
在监督学习时,机器在向“老师”学习。我们就是机器的老师:我们告诉机器,我给你一个输入,你就该给我对应的这个输出,我说hello,你就应该回复我Hi!
在强化学习中,机器在向“评价”学习。机器自己学习,我们没告诉他应该具体什么,只给它输出的结果打分,它在一次次的结果中,被批评的过程中自己总结经验。
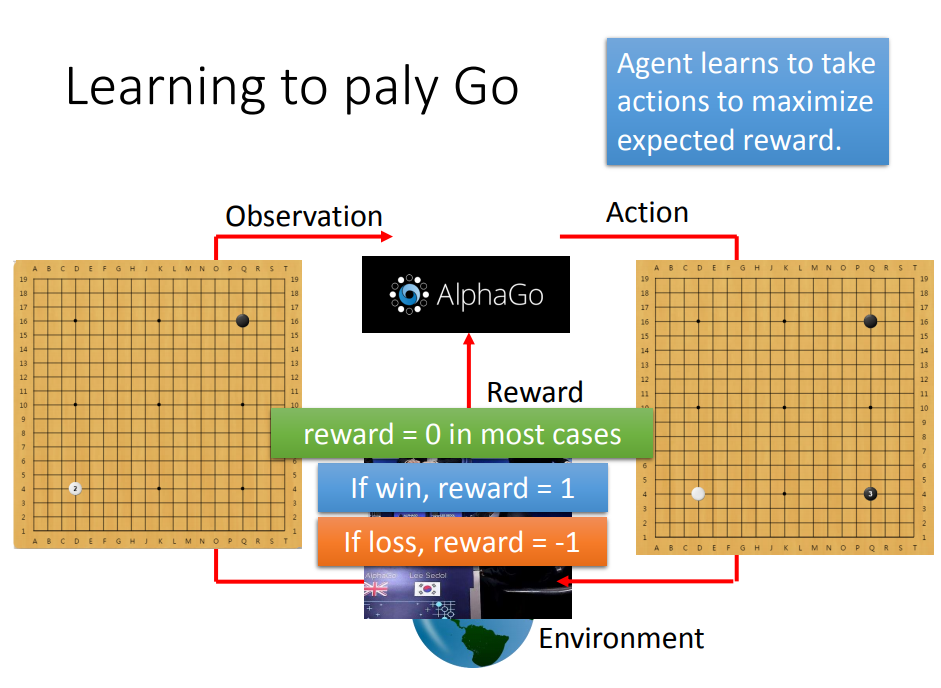
举个很著名的例子:AlphaGo——它就是在和监督学习强化学习中被训练的。首先,它向棋谱学习,也就是说告诉它应该做什么,应该怎么下,这是固定的套路(监督学习);其次,到了后期,它的水平很高之后,它开始向对手学习,这个“对手”可以是另一台机器,也可以是人类棋手,它在一次次比赛结果中总结经验(强化学习)。

3、强化学习的难点
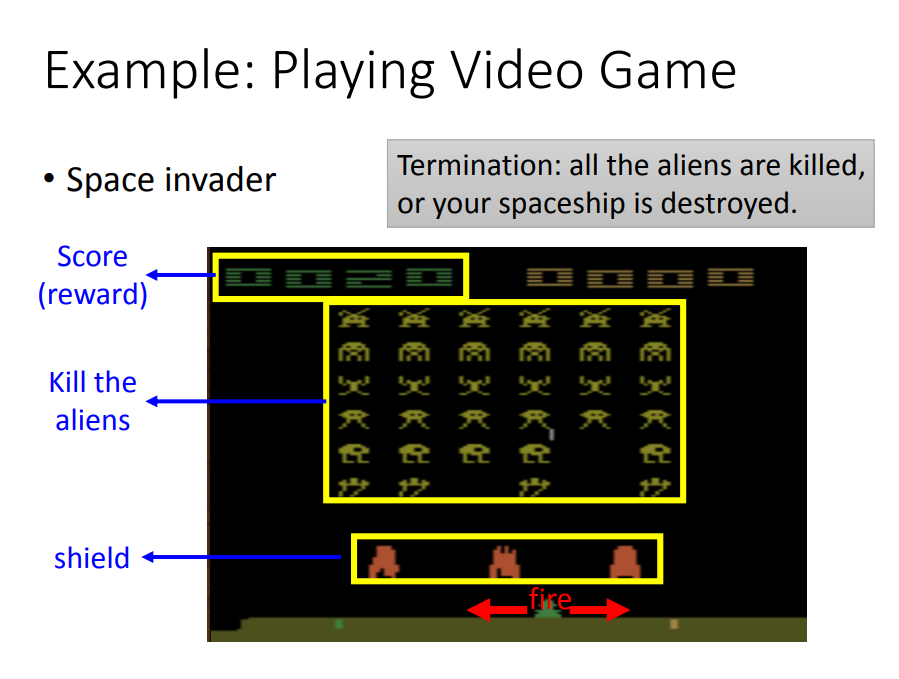
- “规划未来”的能力(只开火,不左右)
- “探索世界”的能力(只左右,不开火)

2、如何实现强化学习(方法)
强化学习本质上是找到最优的策略,使累计回报函数最大
Policy-based: 直接基于策略进行建模,输入当前状态,直接输出执行动作
Value-based: 输入当前状态,通过值函数来输出每个动作的价值(reward),再根据reward进一步执行动作
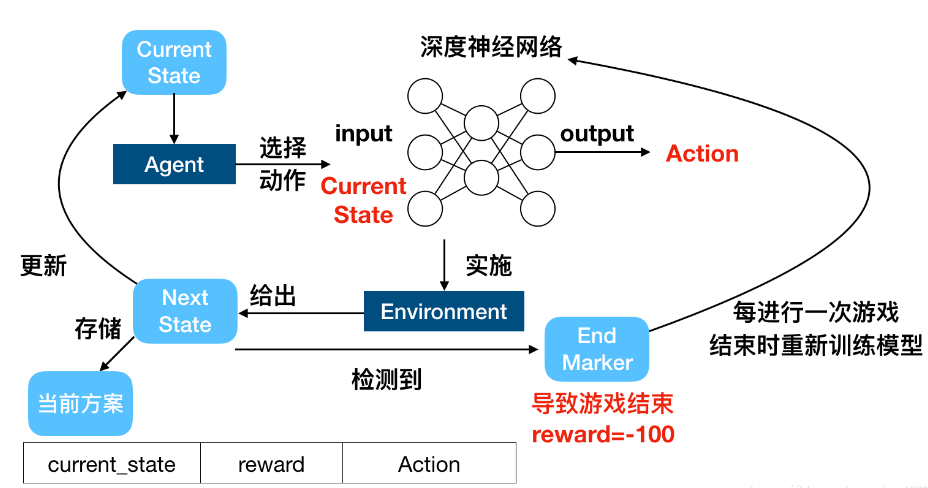
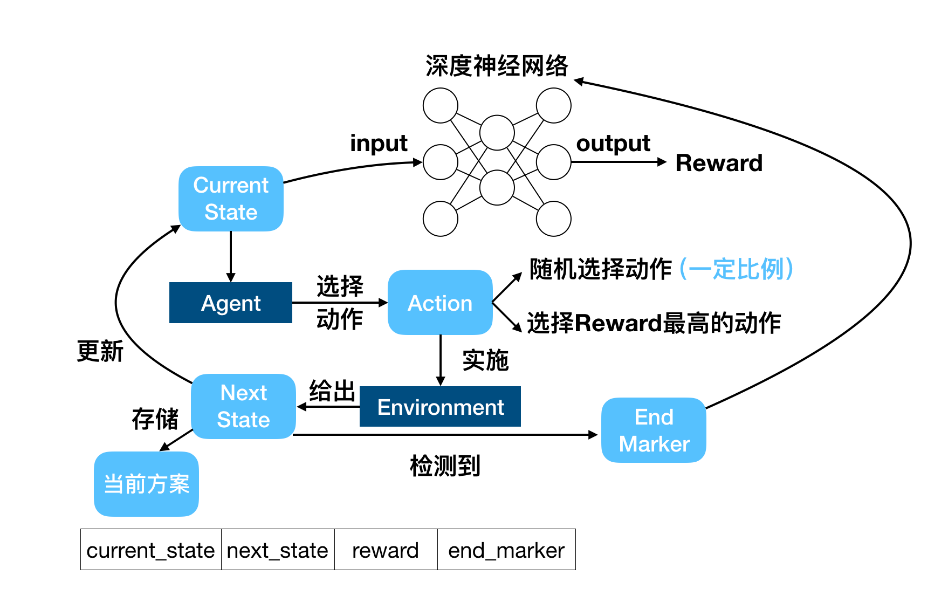
Policy-based:(learn a actor) 代表算法:Policy-Gradient
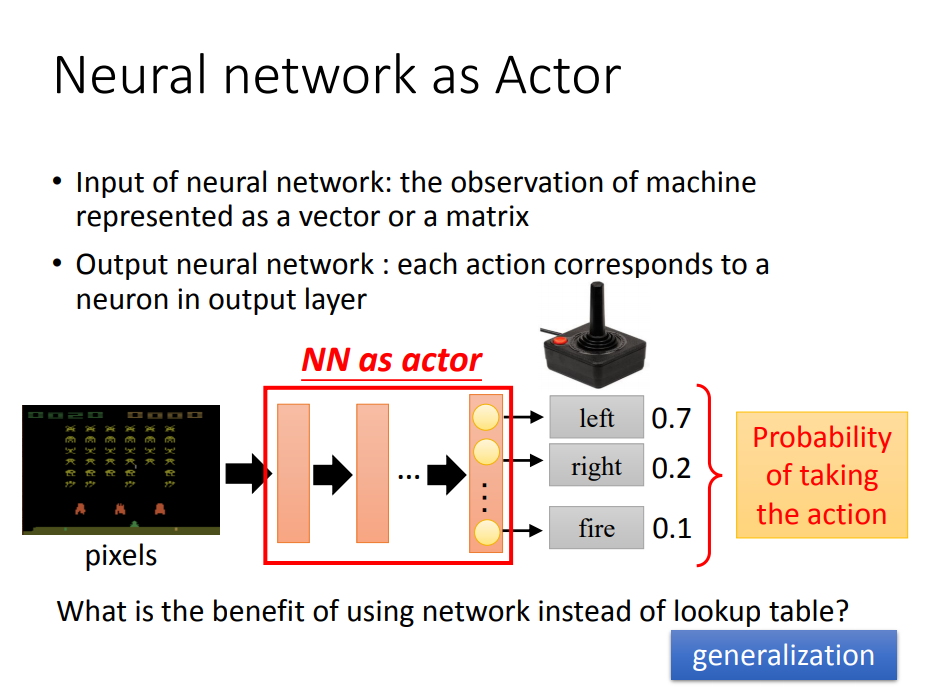
第一步:建立模型(actor是一个neural network)
- 假设策略是随机性的: 输出的action是一个概率
- 用神经网络的好处: 不需要生成包含所有画面的table
第二步: 评价模型
- 让一个actor去玩很多次游戏,计算每一次得到的R,找到最大的R
- 由于游戏具有随机性,拿同一个actor去多玩几次R都会不一样,所以我们应该求得是R的期望值


第三步:选一个最好的function


