

李宏毅机器学习笔记11(Unsurpervised Learning 03——Deep Generative model)
Unsurpervised Learning
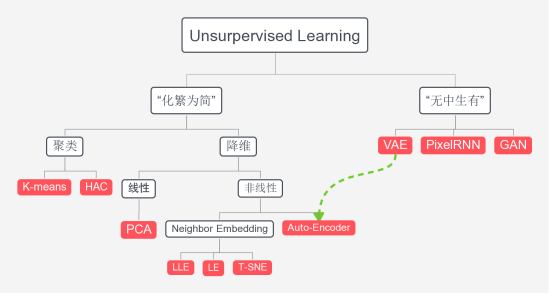
1、深度生成模型“无中生有”
2、VAE(Variational auto-encoder)
一、什么是VAE、为什么用VAE
二、如何实现VAE
三、关于VAE思考
3、GAN(Generative Adversarial Network)
Deep Generative model “无中生有”
1、深度生成模型“无中生有”
比如machine在影像处理上可以做到分类,可以辨识猫和狗的不同。但它并不真的了解猫什么,狗是什么。也许在未来有一天,machine它可以画出一只猫,它会猫这个概念或许就不一样了。

2、VAE(Variational auto-encoder)
一、什么是VAE、为什么用VAE(VAE是解决什么问题)
变分自编码器 是一类重要的生成模型(generative model),它于2013年由Diederik P.Kingma和Max Welling提出1。2016年Carl Doersch写了一篇VAEs的tutorial2,对VAEs做了更详细的介绍,比文献1更易懂(墙裂推荐)。
VAE是什么:VAE也是一种前面所说的标准的自编码器,就是通过Encoder对输入(我们这里以图片为输入)进行高效编码,然后由Decoder使用编码还原出图片,在理想情况下,还原输出的图片应该与原图片极相近。
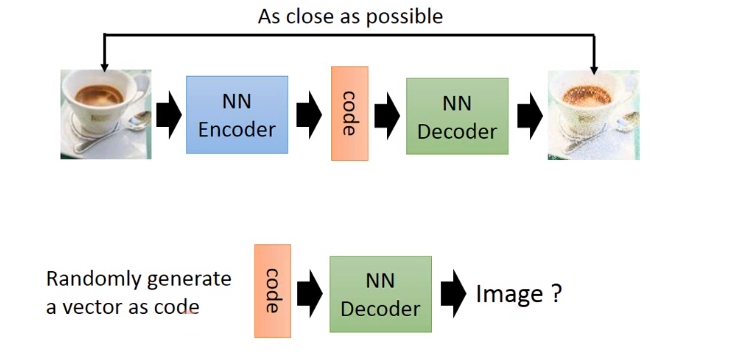
如果你的目标仅仅是重建你的输入,那么标准的自动编码器可以工作得很好,但是它不能作为一个生成模型工作,因为选择一个随机的输入。对于解码器来说,并不一定会导致解码器产生合理的图像。可能随机的输入离解码器以前看到的任何输入都很远,所以当给定输入时,解码器可能从未接受过产生合理数字图像的训练。
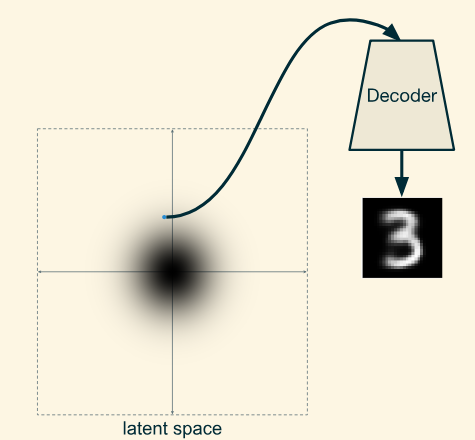
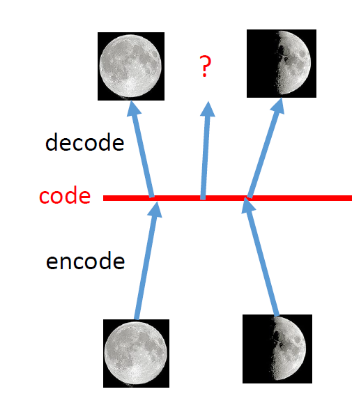
为什么需要VAE:也就是说VAE为什么能确保解码器准备解码任何输入,我们给它一个合理的数字图像。
角度一:本质上(直观)是在标准自编码基础上加噪声
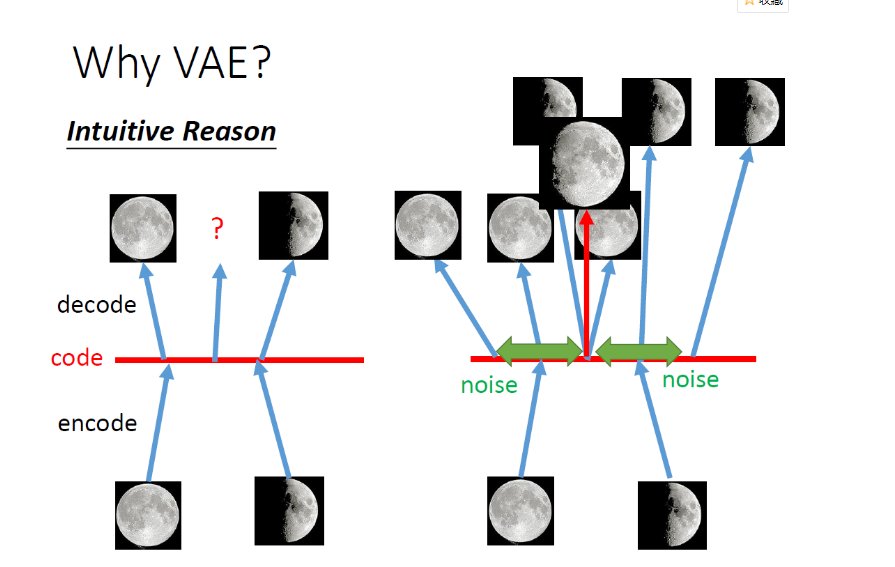
角度二:原理上是在潜在空间(Code)中产生概率分布
假设解码器已经知道其输入的概率分布,那么就能确保对于任何输入,解码器都能给它一个合理的数字图像
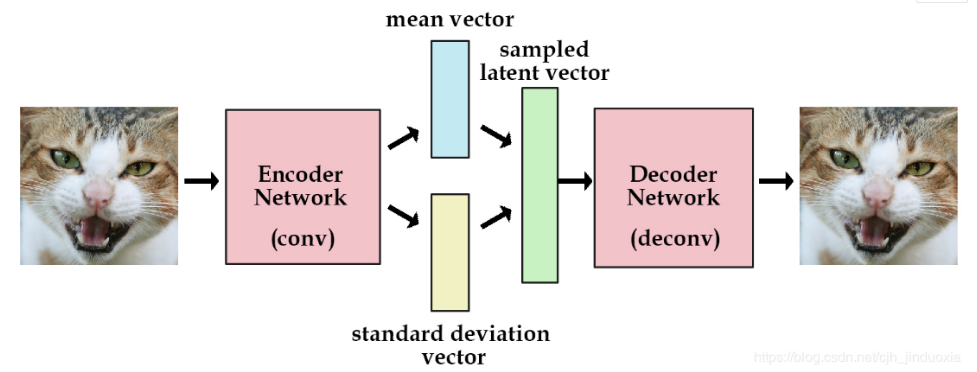
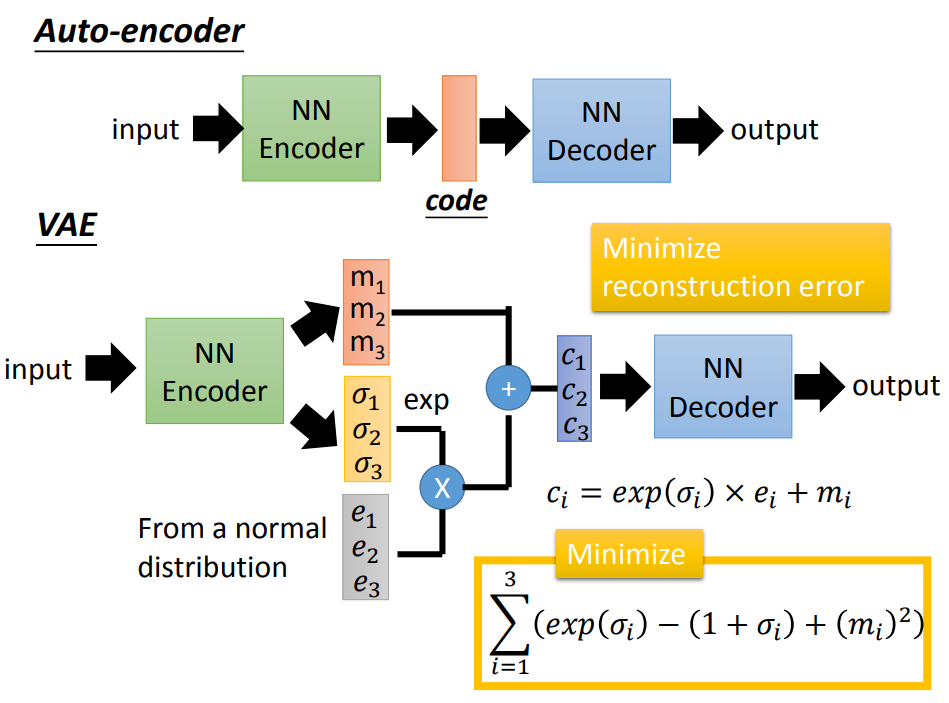
VAE网络结构组成:可以大致分成Encoder和Decoder两部分(如下图)。对于输入图片,Encoder将提取得到编码:一个mean vector和一个deviation vector,然后将这个编码(两个vector)作为Decoder的输入,最终输出一张和原图相近的图片。
二、如何实现VAE
我们刚才说实现VAE需要知道解码器输入的概率分布,为此,我们需要:
一、预先定义解码器应该看到的输入的分布,我们将使用标准正态分布来定义解码器将接收到的输入的分布。
二、用一个编码器,在潜在空间中产生概率分布(训练参数)。
三、在潜在空间中随机抽样z,用作生成模型
四、还原输出的图片集中出现训练集中的原图的概率 P(x)越大,那么我们也可以认为输出与原图片越相似了
五、训练
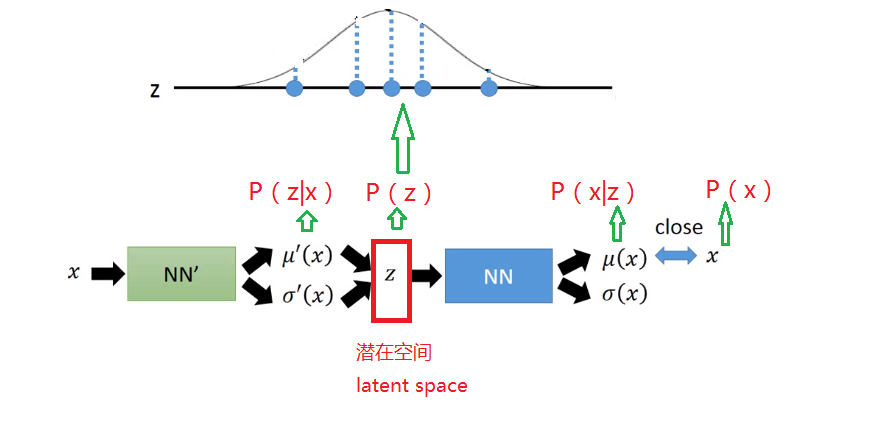
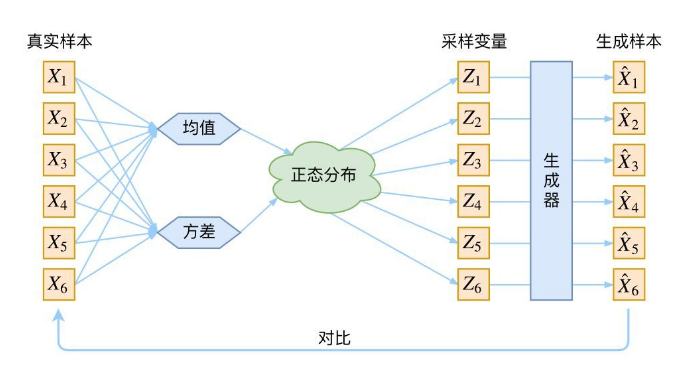

一、定义分布:结合上图,定义z是一个标准正态分布,x|z和z|x是一个特定均值方差的正态分布,那么输出x是一个高斯混合模型
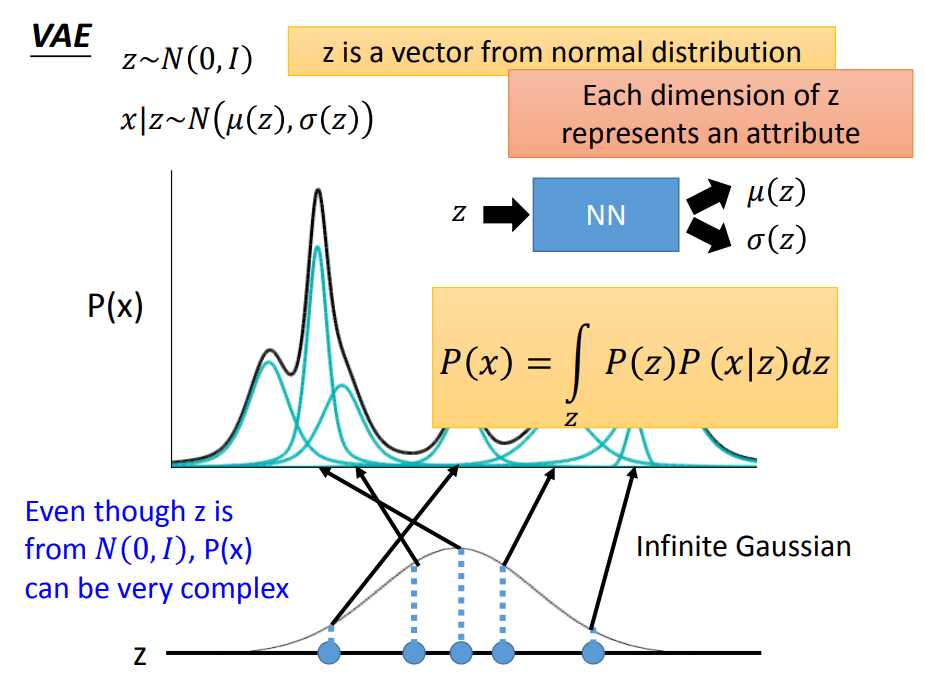
二三、搭建神经网络模型,先忽略
四、求P(x)的最大似然估计,也就是定义模型的损失函数。
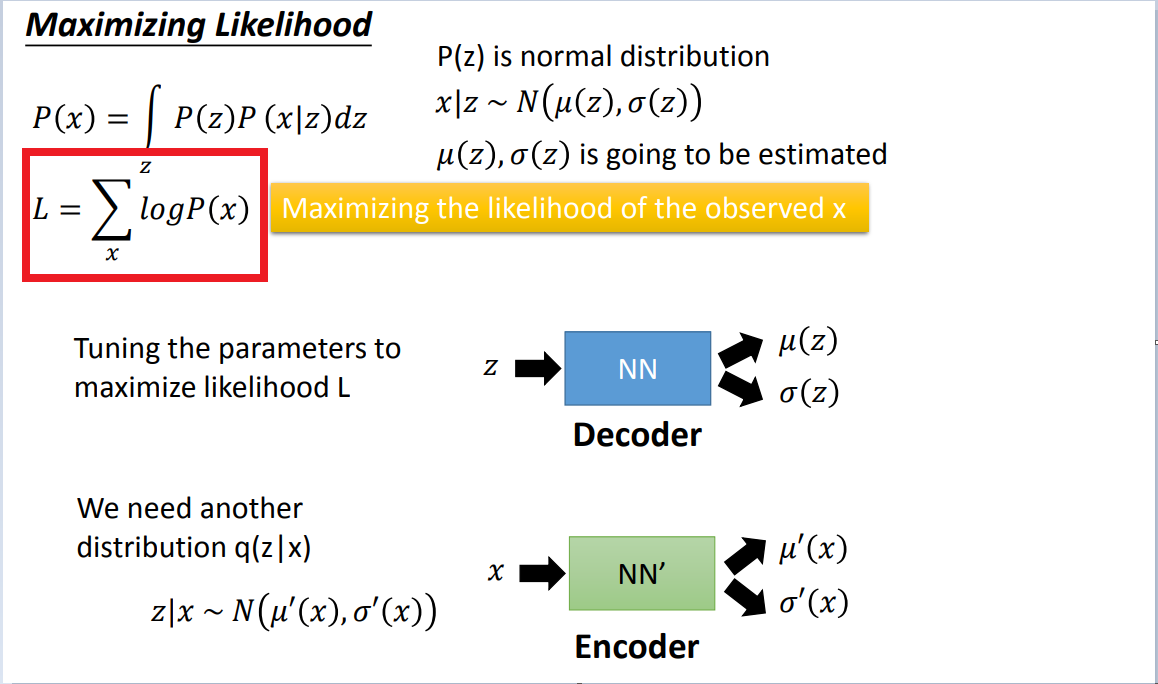

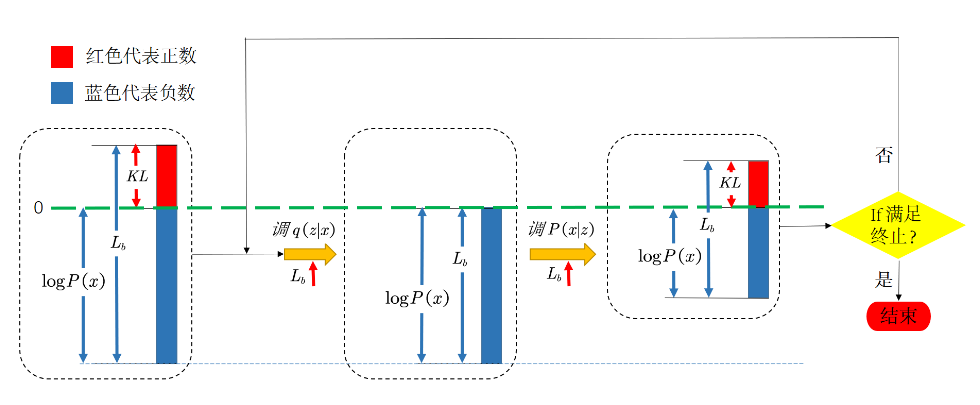
结论1:只控制Lb就好了,上面的KL1是一个中间值,因为Lb越大,最大似然(最终目标)不一定越大(因为KL1会对其有影响),所以要先控制KL1这个中间值接近0

只调整q,不调p,是为了保持logP(x)不变。把上面的KL1逼近0以后,下面只需要考虑Lb就好了

结论2:最终我们是想通过调大Lb,来使最大似然概率最大,那么Lb有两项组成,我们希望最小化与z分布的KL值,同时最大化后面与P(x|z)有关的项
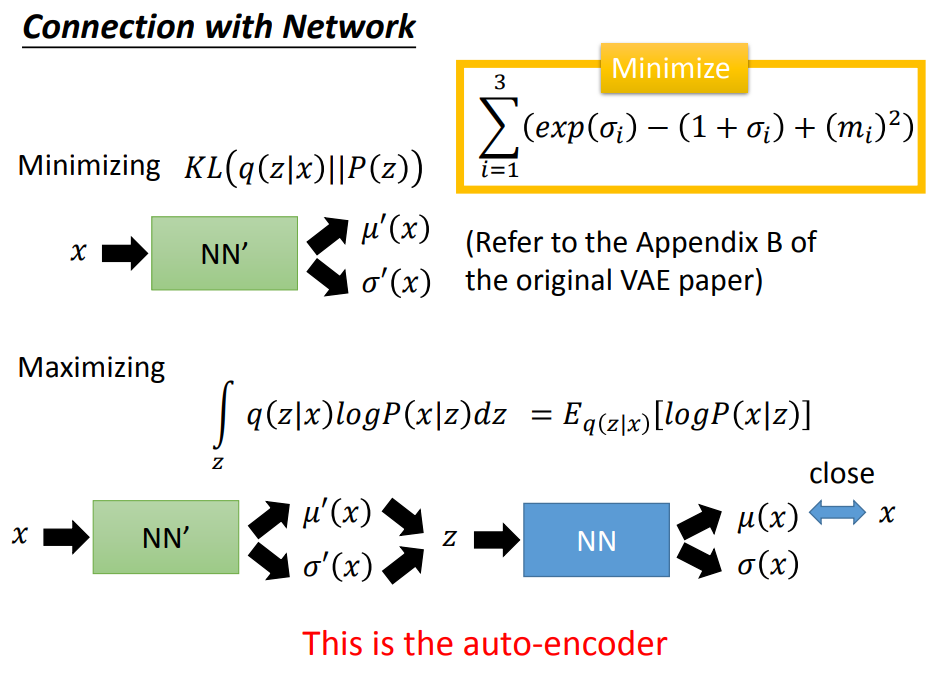
五、训练
训练过程:先调q(z|x)--encoder,后调p(x|z)--decoder
https://blog.csdn.net/cjh_jinduoxia/article/details/84995156
三、关于VAE的思考
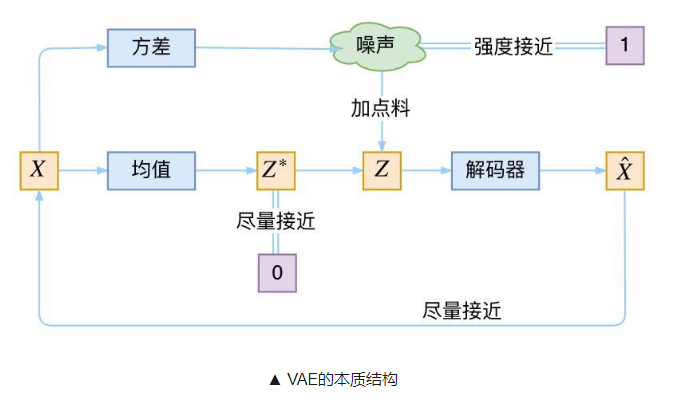
1、关于VAE的本质
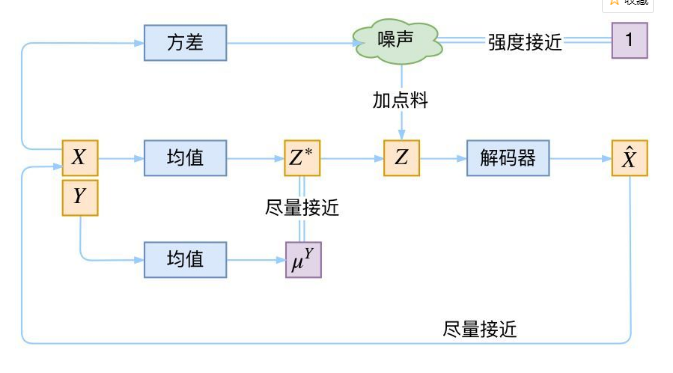
2、CVAE(Conditional VAE)
https://www.sohu.com/a/226209674_500659
3、GAN(Generative Adversarial Network)
一、什么是GAN
- GAN的核心思想在于博弈,GAN有两部分模型构成,一个是生成模型(G),一个是判别模型(D)。
- 生成模型用于生成一个逼真的样本,判别模型用于判断模型的输入是真是假。
- 通俗来讲,就是生成模型要不断提升自己的造假本领,最终达到骗过判别模型的目的。而判别模型则不断提升自己的判别能力,达到辨别真假的目的,这也就形成了博弈,也就是对抗。
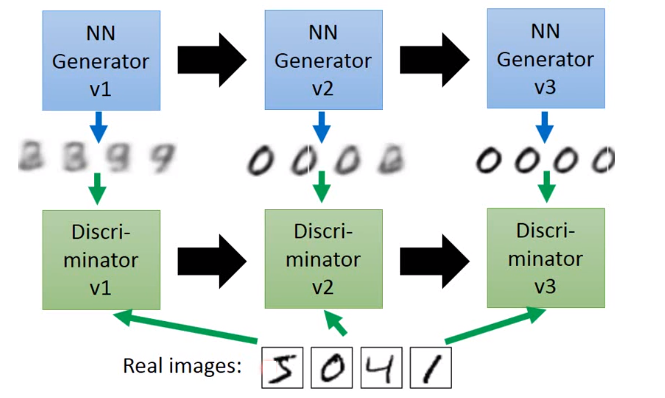
二、GAN是如何实现的
单独交替迭代训练
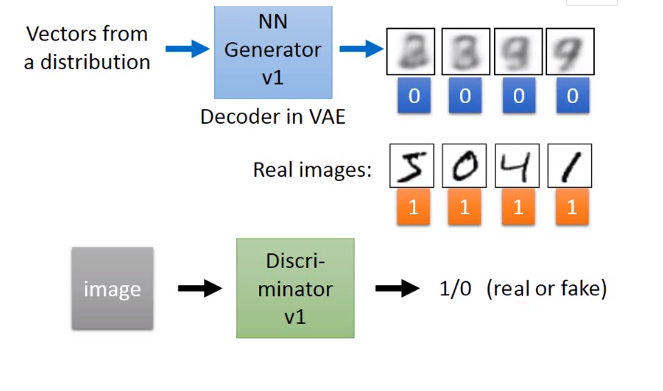
1.首先,我们有一个简单的生成网络模型(当然未训练时效果很差),那么我们给这个模型一个随机的输入,便会输出得到一个假的样本集,而真的样本集我们本身就有,所以我们得到了真假数据集。
2.在得到真假数据集之后,我们开始对判别模型进行训练,训练过程就是一个有监督的二分类问题,即给定一个样本,能判断出其是真实存在的(真样本),还是利用生成网络生成的(假样本)。
3.在完成判定模型的训练之后,我们要提升生成模型的造假能力,我们将生成网络与训练好的判定网络串接,我们的目标是生成可以迷惑判定模型的图像,所以我们给生成网络一个随机输入,损失函数是判定网络的输出是否为真(是否达到迷惑的效果),根据损失函数,对生成网络的参数进行更新,(注意:这里判定网络的参数是不改变的,因为判定网络是用来评价生成网络的造假能力,计算损失的)

4.完成生成网络的训练之后,再次给定随机输入,得到新的假的数据集,将最新得到真假样本输入给判定网络进行训练,从而完成对判定网络的再一次训练。
5.不断重复上述过程,直到满足设计者设定的训练次数。

