李宏毅机器学习笔记05(Deep Learning->DNN)
Deep Learning-------->DNN(深度神经网络)
思路:
1、什么是深度学习
2、深度学习的步骤
3、如何优化(调参问题描述)
问题描述:参数更新的过程、training data 与参数更新的关系(训练过程)
4、Back Propagation方法update DNN参数
1、什么是深度学习
- 深度学习的model是一个深度神经网络结构(neural structure)
- 深度学习的“深度”是指神经网络的隐层(hidden layer)数量足够多
- 深度学习是自动提取特征(Feature extractor),不需要像逻辑回归那样特征转换(Feature engineering)
2、深度学习的步骤
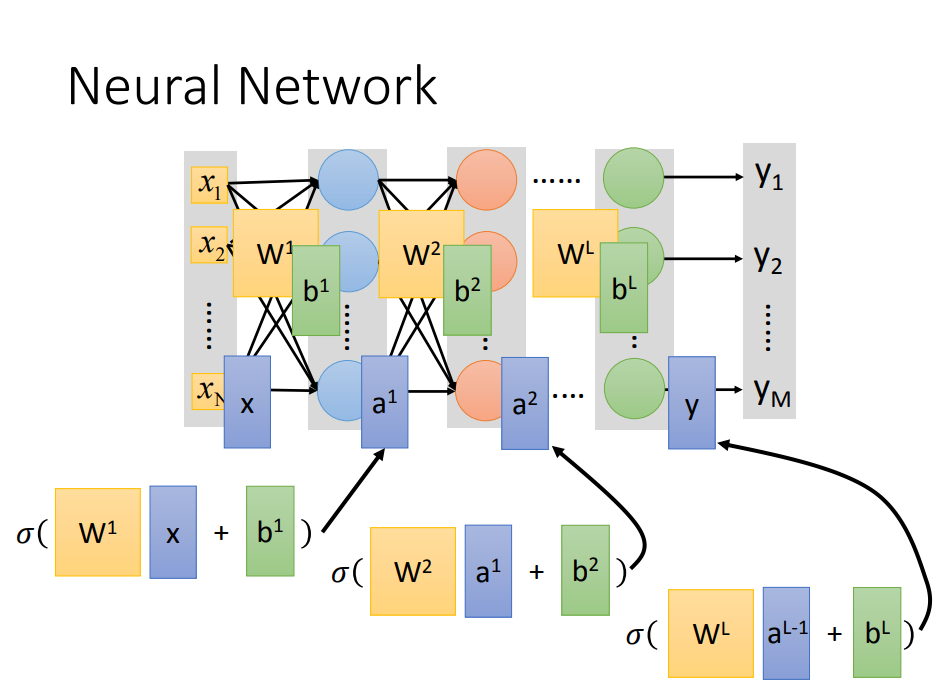
Step1、定义一个神经网络结构(neural structure)
神经网络的创建包括3部分:一是神经网络有多少隐层(layer)、二是每一层有多少神经元(neuron)、三是每个神经元之间如何连接
往往需要 尝试发现错误+直觉
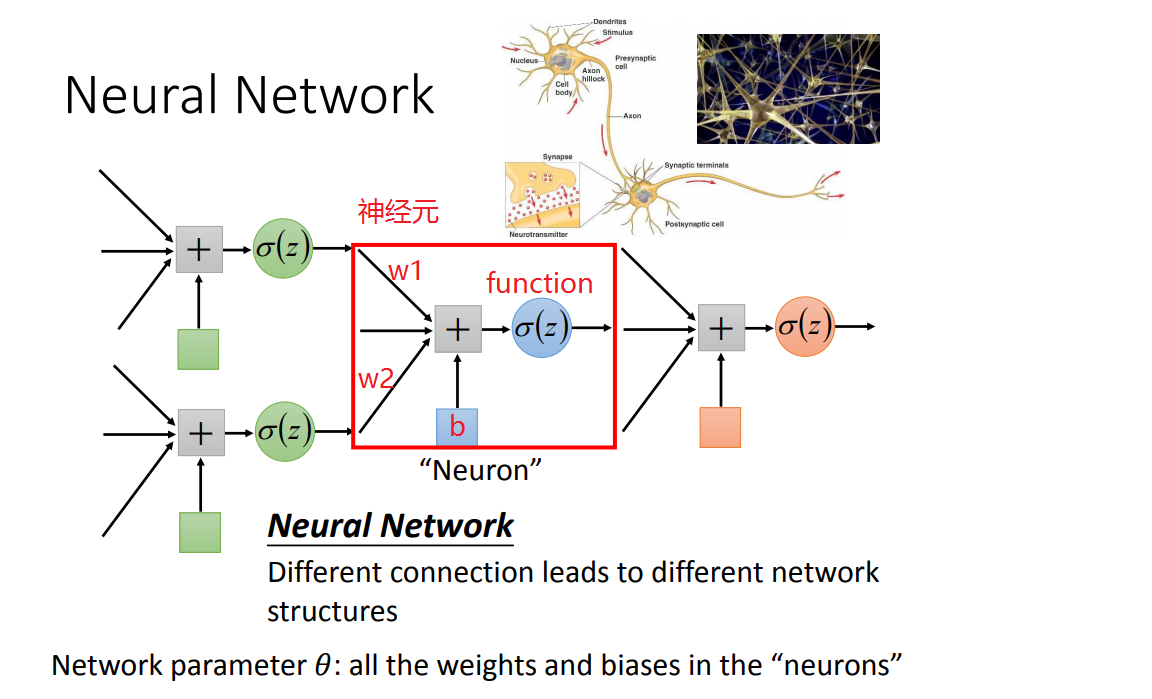
1)神经元:每个神经元都有一个 bias 和一个 function ,每条输入的边都有一个 weight
2)举个栗子:下面是一个 3个隐层、两个神经元、全连接的神经网络
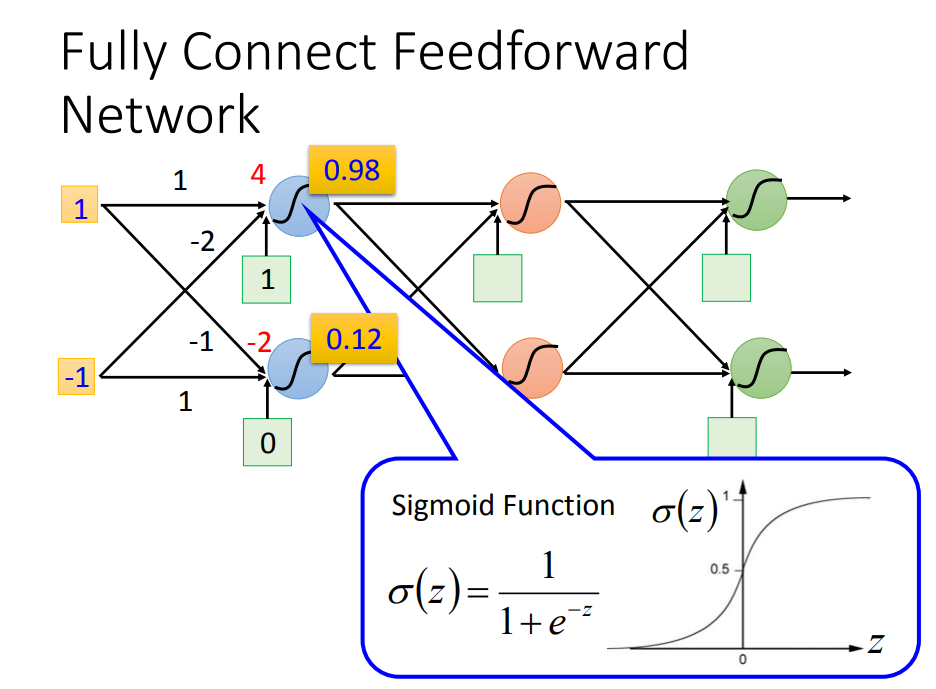
3)神经网络如何工作的呢
假设已经定义好了神经网络之后(也就是function找到了),输入和输出都是一个 向量(vector)
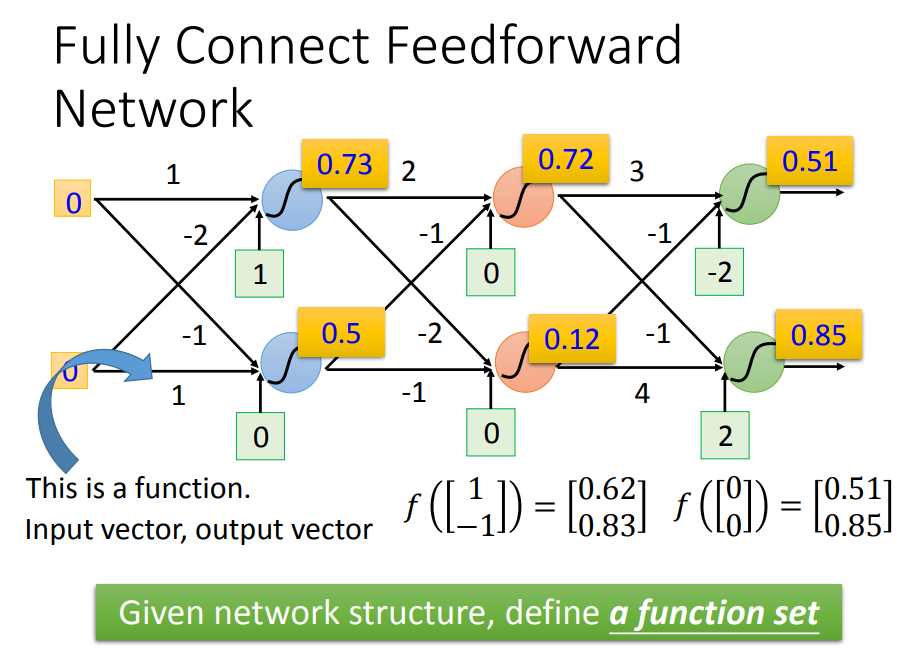
现在给定一个输入(vector),神经网络内部如何计算,然后得到输出呢?
矩阵运算(可以用GPU加速),先算第一层:
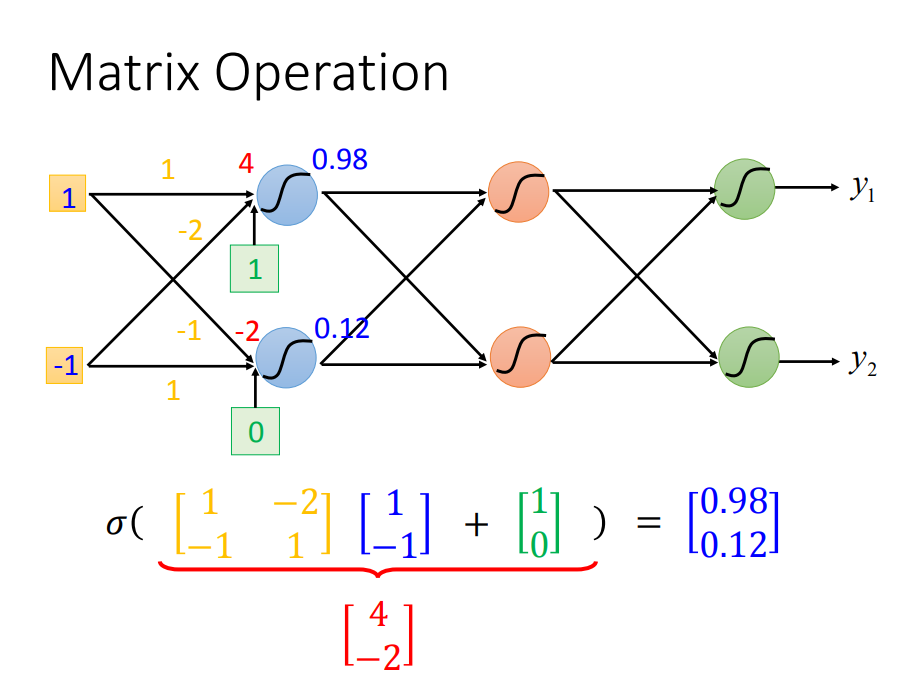
其他层也一样:
三层都计算完之后:

举个栗子:手写数字识别
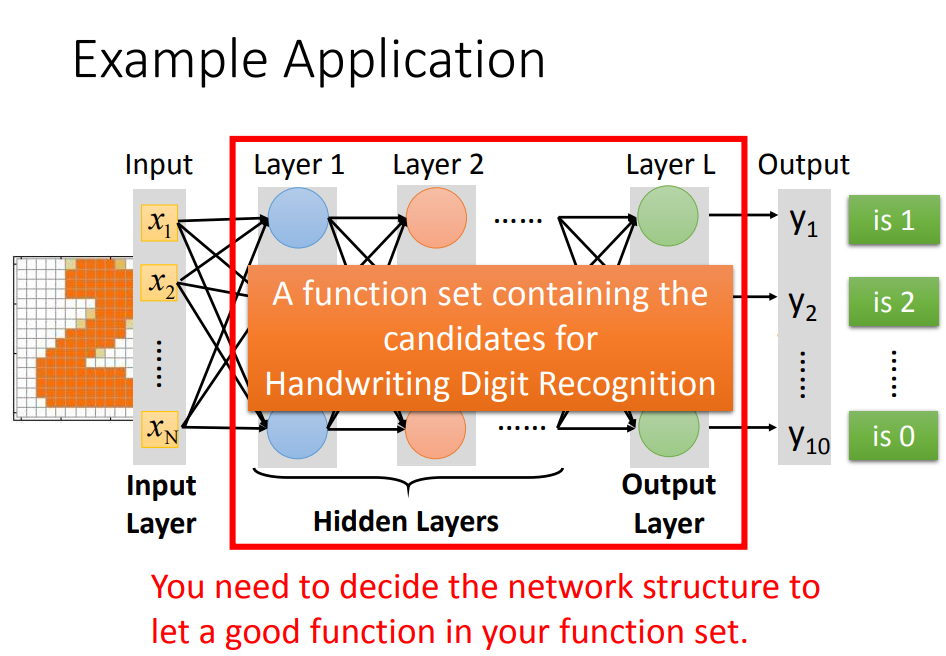
Step2、确定损失函数
跟逻辑回归一样,用交叉熵
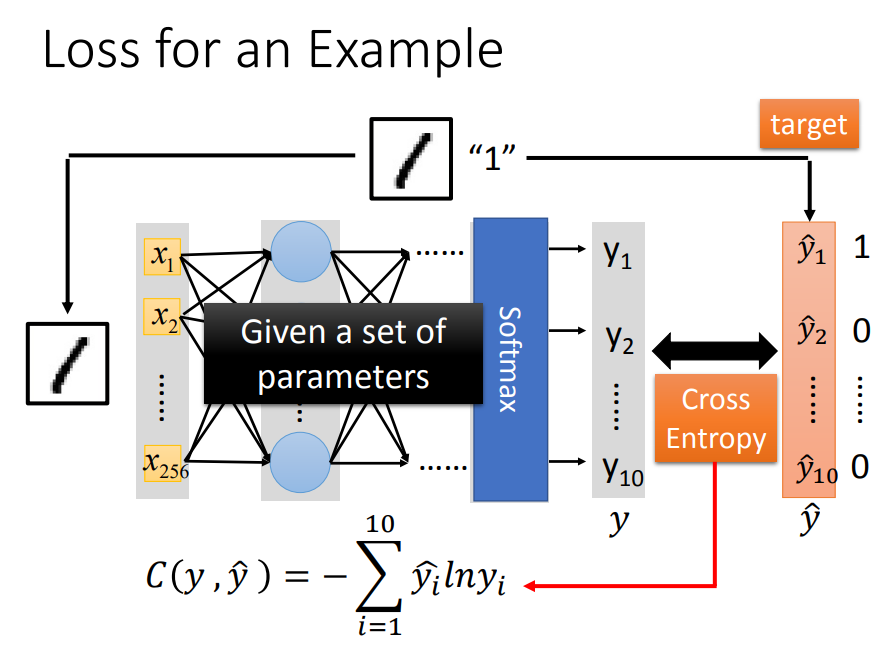
算总Loss:
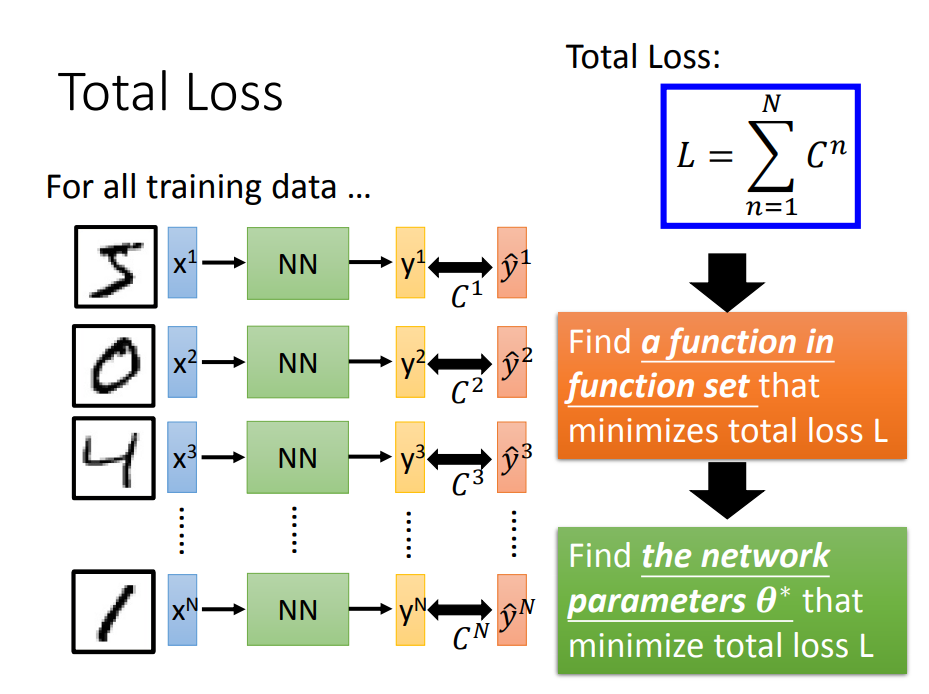
Step3、找到一个最好的函数(最佳参数)


3、如何优化(调参问题描述)
问题描述:参数更新的过程、training data 与参数更新的关系(训练过程)
如果想要做好优化问题,也就是调到好的参数,那么前提是要很清楚参数更新的过程。
参数更新主要出现在step 3部分,也就是说参数在梯度下降的过程中更新的。
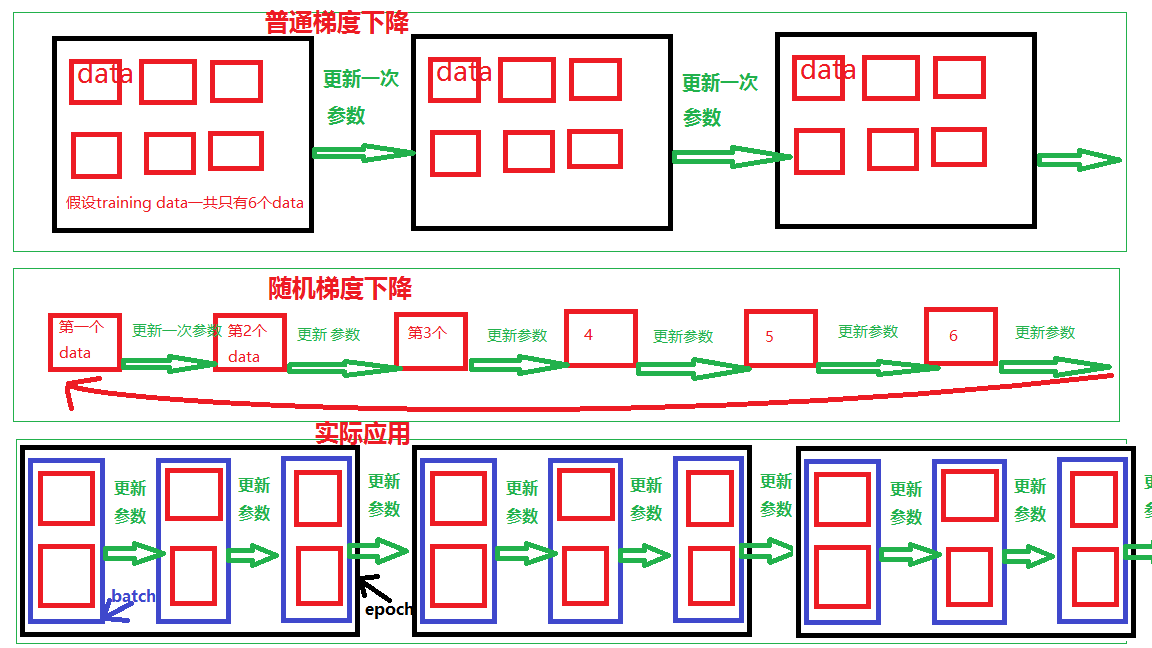
1)普通梯度下降(批量)
一、随机选取一组参数
二、输入所有的training data【(x1,y1^),(x2,y2^),……(xn,yn^)】
三、然后data不变,参数不断变,用梯度下降法更新参数
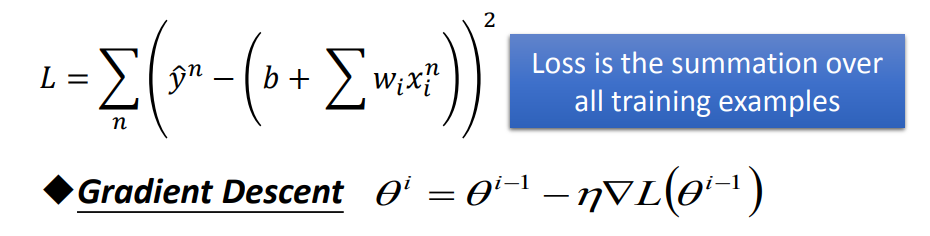
此时的LOSS函数是计算所有training data的损失值相加的和,然后更新一次参数

2)随机梯度下降 (快,但是不稳定)
一、先随机选取一组参数
二、再输入第一个training data(x1,y1^)
三、然后data变一次,参数变一次,用梯度下降法更新参数
四、再输入第二个training data(x2,y2^).....循环

此时的LOSS函数是计算一个training data的损失值,就更新一次参数,假如有100个data,当data全部加入时参数就更新了100次
3)小批量梯度下降(MBGD)(用batch、epoch又快又稳定)
一、先随机选取一组参数
一、设置batch、epoch,然后data变batch次,参数变一次
二、根据设置的batch size,每输入一个batch的数据,用梯度下降法更新参数,直到算完所有的batch就完成了一个epoch。
三、根据设置的epoch,重复步骤二,一直到epoch次
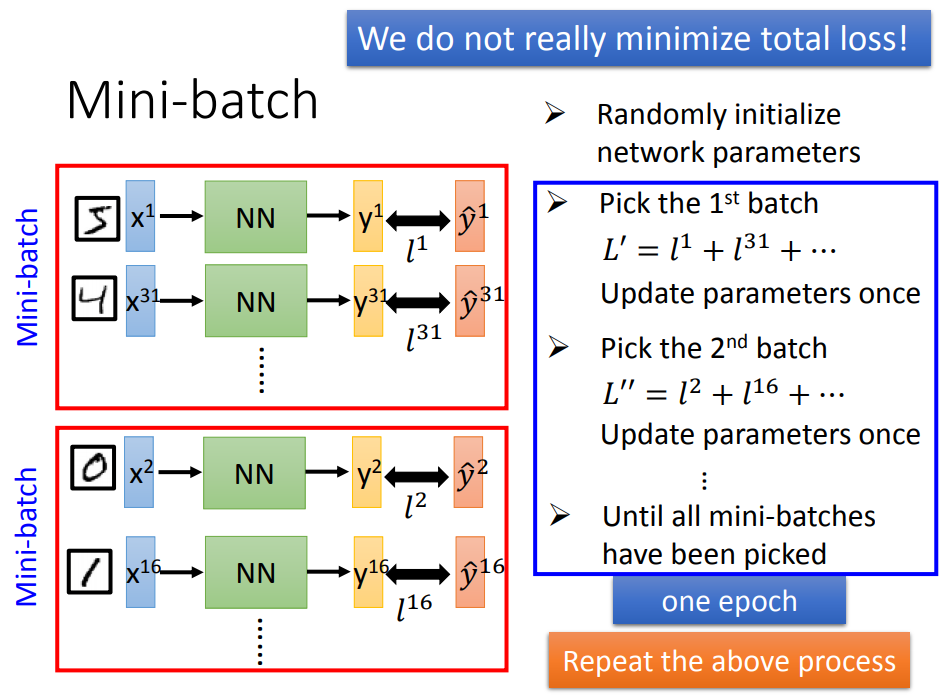

又快又稳的原因:
在一个batch=2里面,由于数据每输入两次,参数更新一次,所以一个batch里面的下一个数据输入不会用到前一组参数(同一组参数),因此可以用GPU并行计算
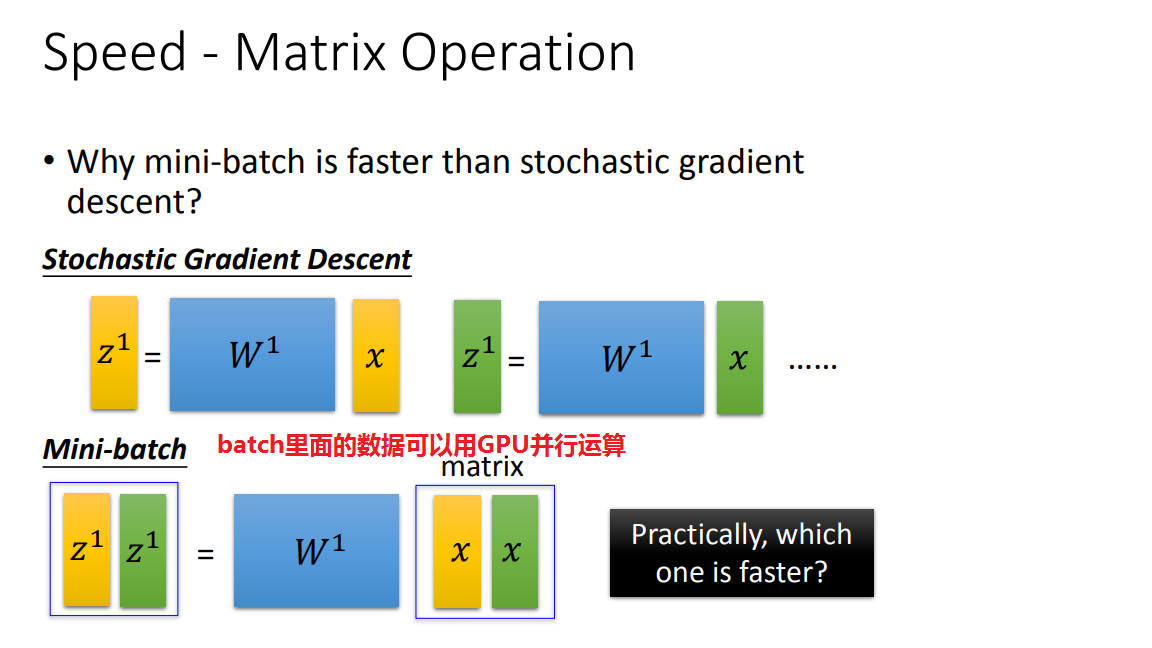

对比:
4、Back Propagation方法update DNN参数
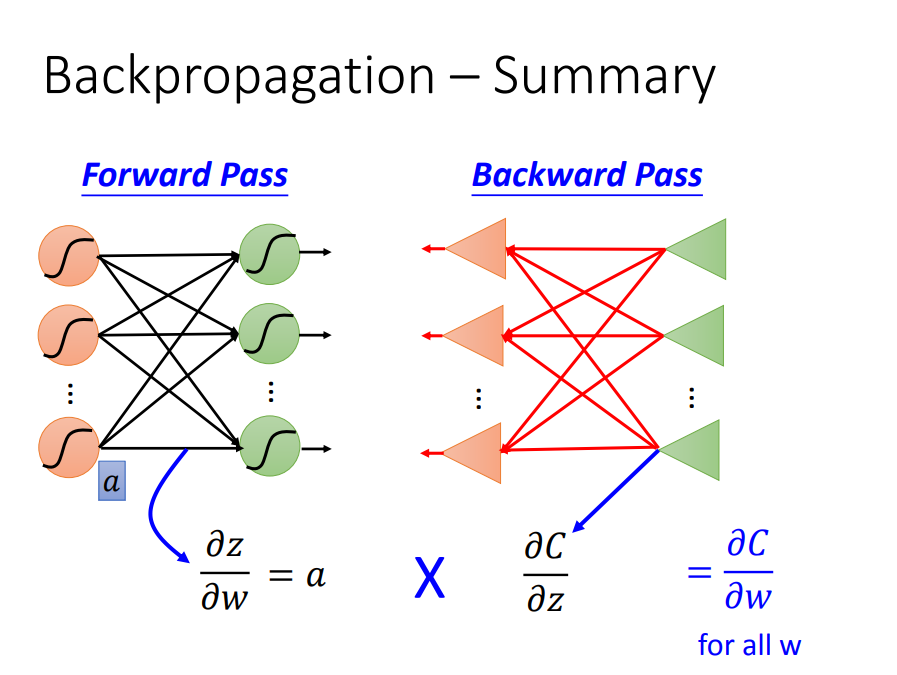
1、BP(后向传播)是用来快速计算DNN梯度的

2、前向传播+后向传播是如何计算DNN梯度的
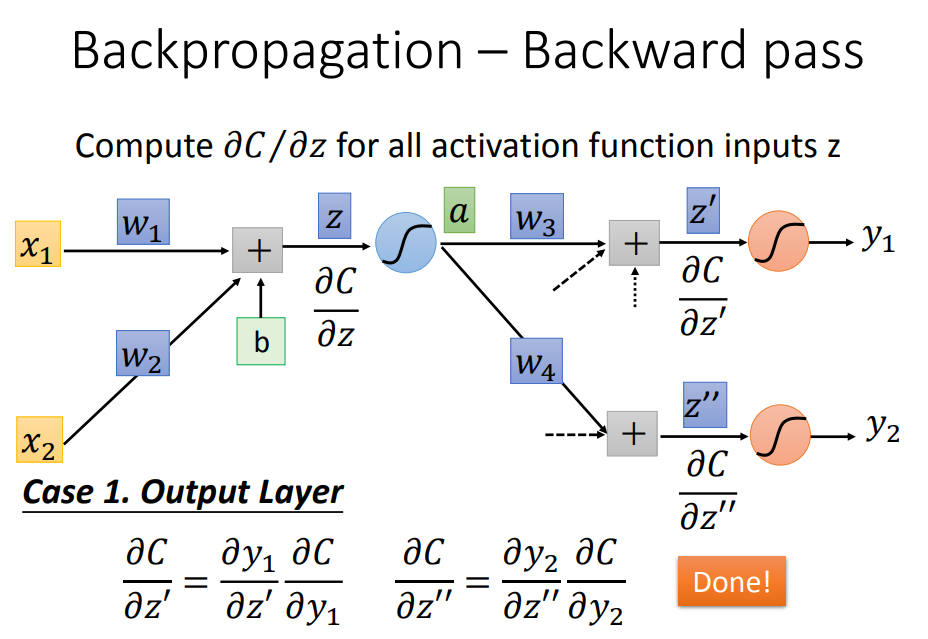
先看清楚损失函数C所处的位置:输入经过一个DNN网络输出,再与理论值的比较才得到损失函数,所以C对W的偏导是经过长长的神经网络每一层的链式传导
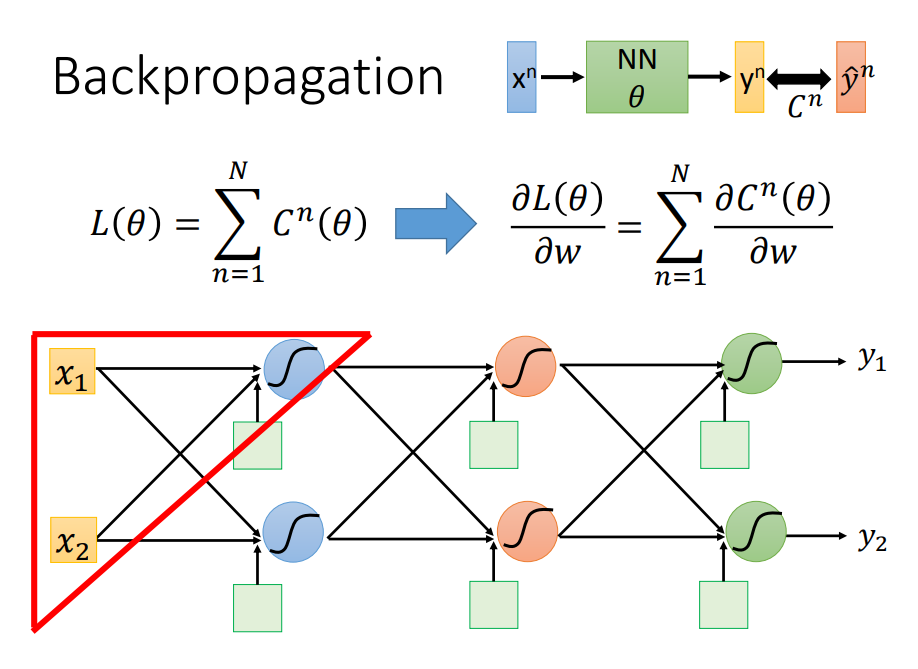
开始求导,分为前向传递部分与后向传递部分
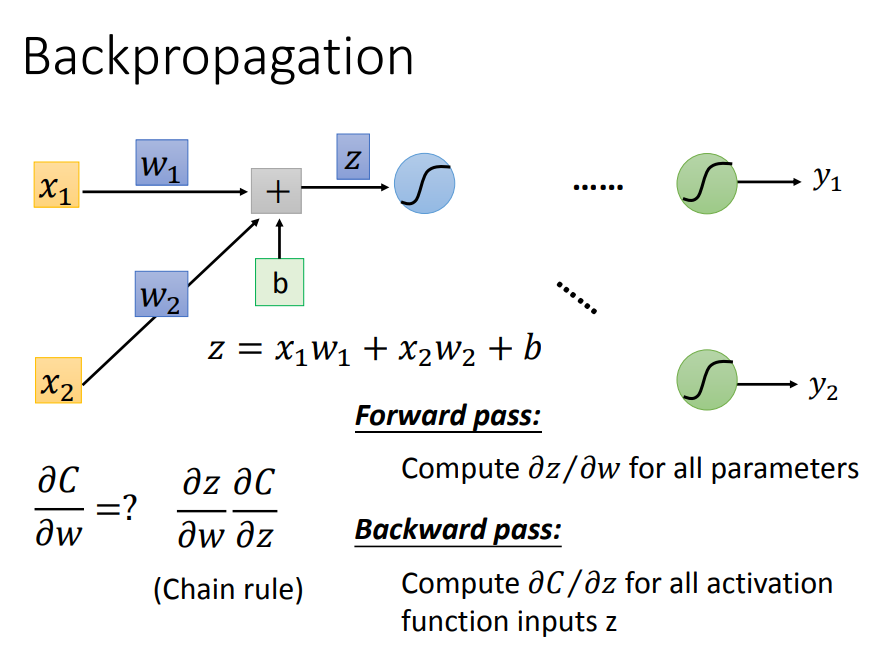
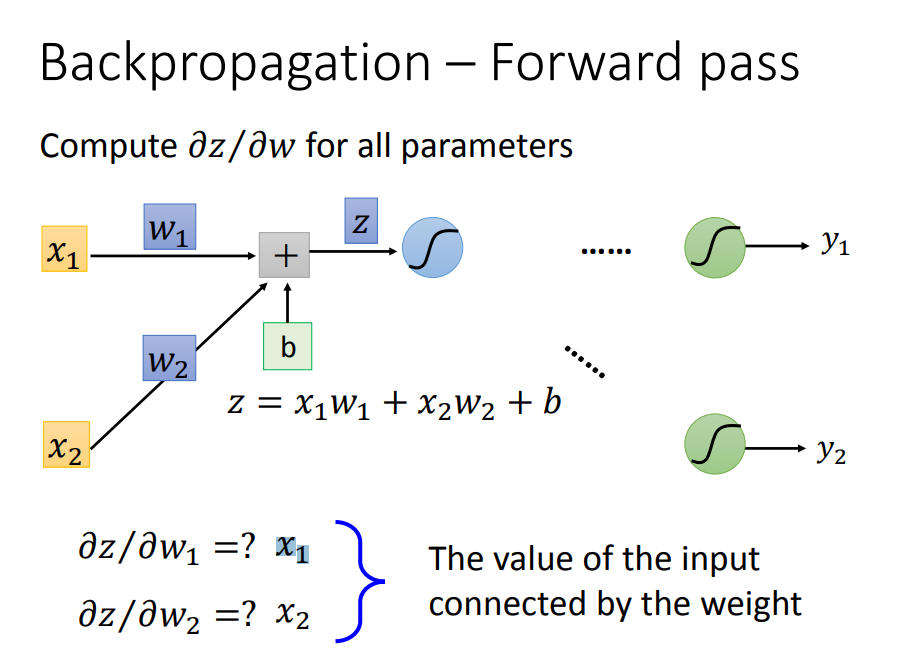
前向传递很好求,就是权值所对应的输入量
后向传递开始表演:要从输出端往回传
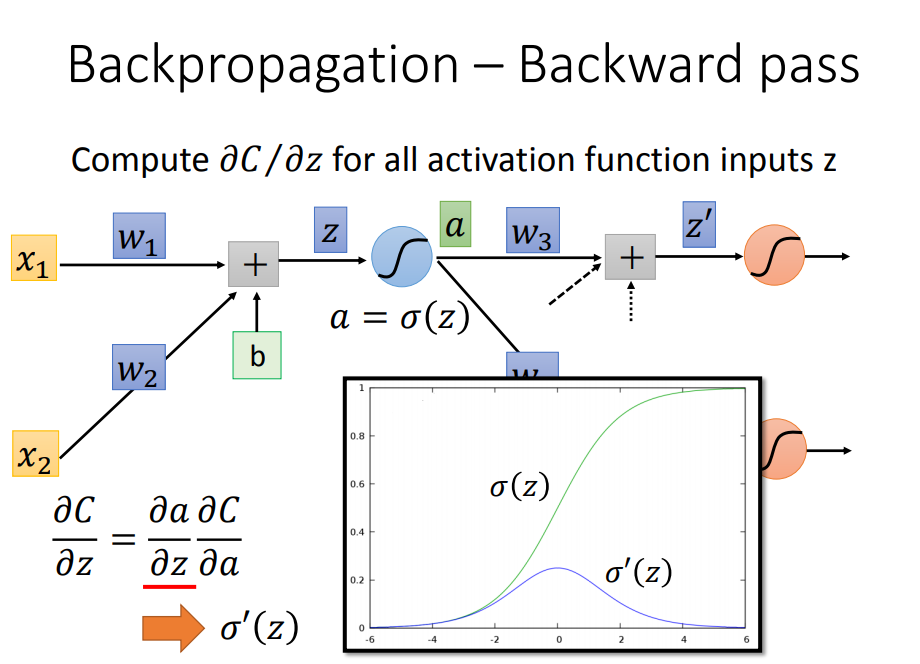
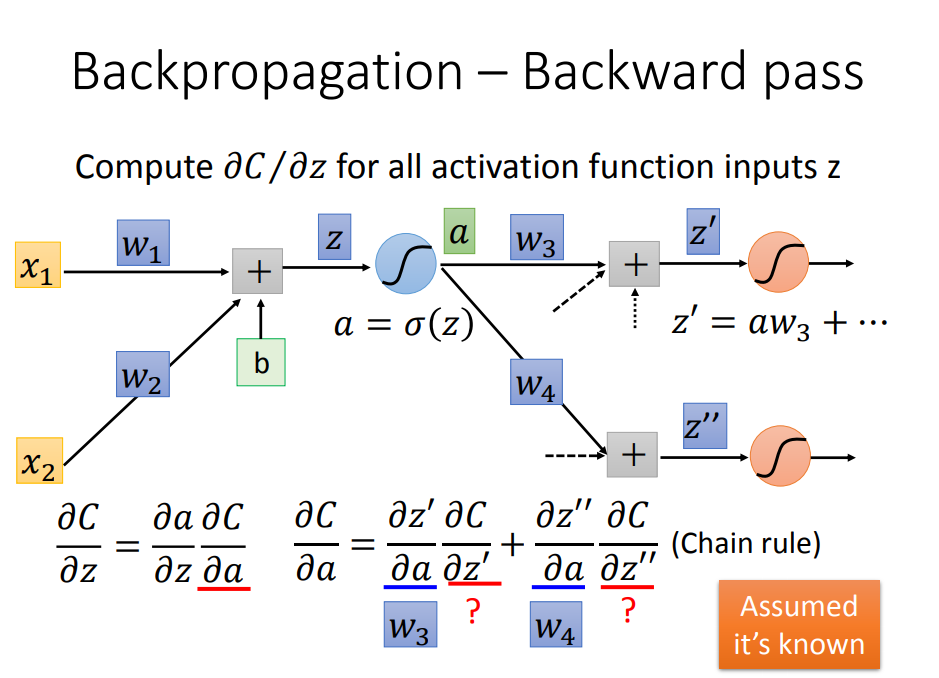
要怎么从后往前计算呢
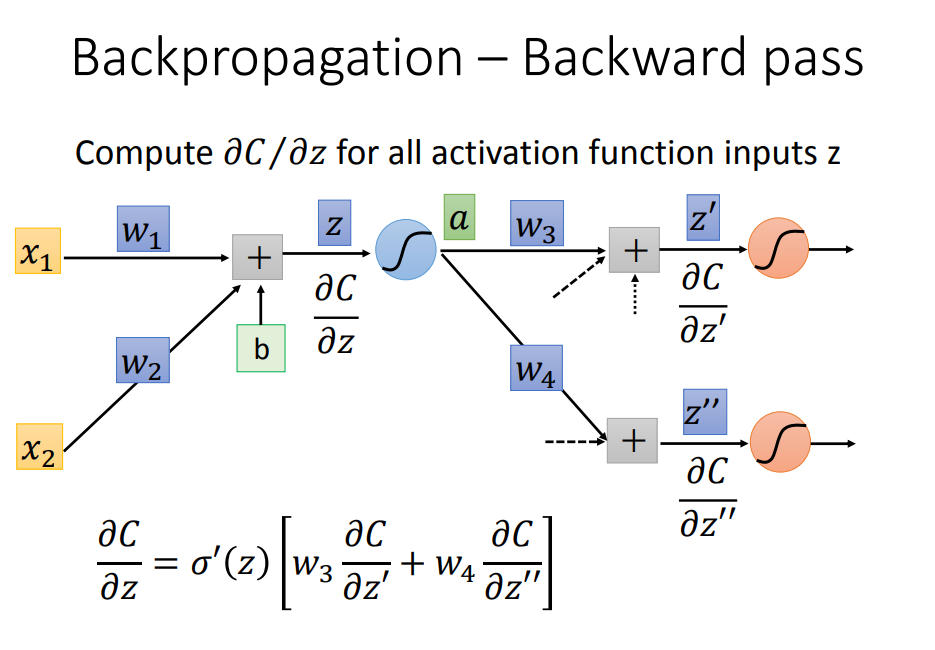
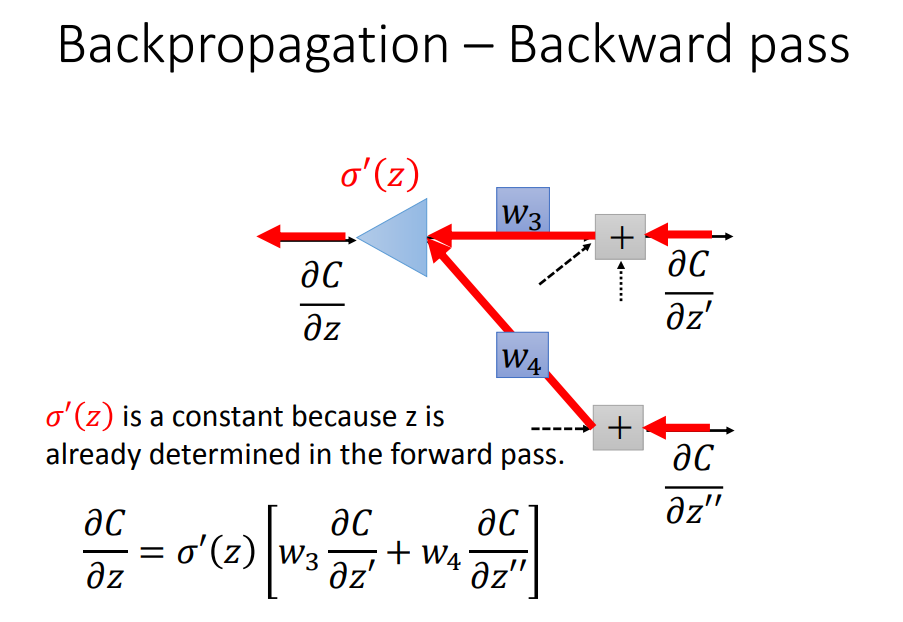
3、总结

 浙公网安备 33010602011771号
浙公网安备 33010602011771号