
LightDB数据库分布式部署实践
当今做大型数据库应用的时候,随着业务越做越大,数据量也会越来越大,计算也会越来越复杂。对性能,可靠性,可扩展性的需求越来越强烈,集中式数据库显然已经满足不了需求。
LightDB数据库通过自身集成的Canopy扩展已支持了分布式模式部署,使转换为具有分片、分布式SQL引擎、引用表和分布式表等功能的分布式数据库。
LightDB Canopy采用协调者(CN)+工作者(DN)节点架构(也可以认为是master和worker,且协调者和工作者一样都是LightDB实例),当在协调者节点中执行一条命令时,SQL语句经过语法解析后,在协调者节点的analyze阶段被LightDB中的Canopy扩展替换,并进行SQL语句的fork and join过程,最终分发到不同的工作者节点中。在分布式事务的实现上,LightDB Canopy采用2PC协议。
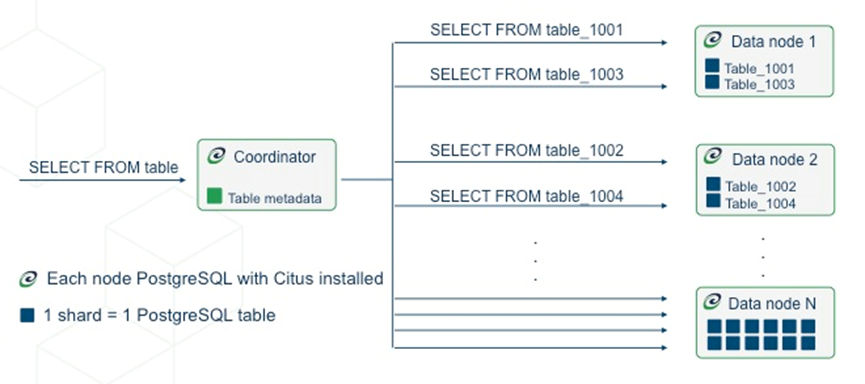
分布式部署
LightDB分布式安装
LightDB分布式支持常规模式、多机单实例和单机多实例三种部署方式安装。
- 常规模式:1台服务器作为协调者节点,N(N > 1)台服务器作为工作节点,每个节点都是高可用方式部署 ,例如1个协调节点2个工作节点,每个节点都按1主1备方式部署,则需要6台服务器。如果每个节点按照1主1备1witness部署,则需要9台服务器;
- 多机单实例:1台服务器作为协调者节点,N(N > 1)台服务器作为工作节点,每个节点上均有一个数据库实例,且所有实例均按单机模式部署;
- 单机多实例:使用1台服务器同时安装协调者节点和工作节点的实例,且所有实例均按单机模式部署。
(注意:如果需要在生产环境使用LightDB分布式,则建议只使用常规模式,其余两种模式仅为测试、学习等非生产环境提供。)
LightDB分布式版可通过GUI或命令行进行安装部署,对应安装包和参考手册如下,具体安装步骤此处不再赘述:
安装包:http://www.light-pg.com/downloadList.html?key=lightDB_X
手册:http://www.light-pg.com/docs/LightDB_Install_Manual/current/install.html#id26
分布式部署方案改造
针对上述的常规分布式部署,如果是1CN 2DN按照每个节点至少一主一备的模式,至少需要6台服务器。然而现场环境基本不会这么理想化,很多时候需要依靠少量服务器来搭建分布式环境。此时可通过DN节点上不同服务器互为主备的方式来节约服务器的数量(由于DN节点主要做存储,故单台服务器上仅部署一个DN节点会存在较大的性能浪费),这种DN互为主备的方式可以节约一半数量的服务器,同样可以实现整体环境的稳定性和高效性。
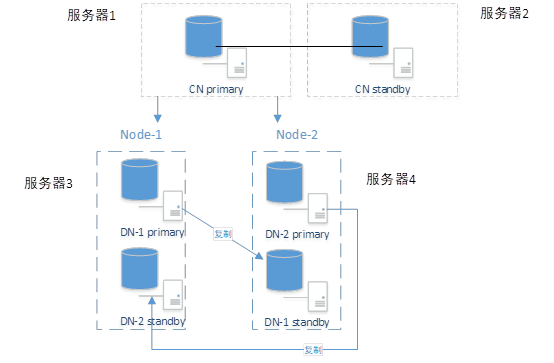
由于当前LightDB版本(22.4及以前版本)尚不支持这种DN互为主备的部署方案,可通过手动安装方式进行部署,具体操作步骤如下:
(注:以下部署流程中所设计的IP、端口、HOME/DATA等路径需根据实际环境进行替换为绝对路径,此处仅为举例说明,并非实际信息)
1. 使用LightDB安装包安装分布式多机单实例模式,安装完成后形成1CN 2DN环境,每个服务器上运行一个实例(具体部署步骤可根据LightDB安装手册进行操作
http://www.light-pg.com/docs/LightDB_Install_Manual/current/install.html#id3
http://www.light-pg.com/docs/LightDB_Install_Manual/current/install.html#id30)
2. 分别修改三个实例配置文件$LTDATA/lightdb.conf中的shared_preload_libraries,添加ltcluster(注:需添加在canopy之后)
shared_preload_libraries='canopy,ltcluster,lt_stat_statements,lt_stat_activity,lt_prewarm,lt_cron,lt_hint_plan,lt_show_plans'
修改后重启数据库
lt_ctl restart
3. 在CN节点库中执行以下三条SQL:
create extension ltcluster;
create role ltcluster superuser password 'ltcluster' login;
create database ltcluster owner ltcluster;
分别在两个DN节点库中执行以下一条SQL:
create database ltcluster owner ltcluster;
4. 在DN1节点的$LTHOME/etc/ltcluster下创建ltcluster.conf配置文件,内容如下(以下IP、端口、路径均针对DN1节点数据库,此处仅作举例):
node_id=1295432
node_name='1231231231295432'
conninfo='host=123.123.123.129 port=5432 user=ltcluster dbname=ltcluster connect_timeout=2'
data_directory='$LTDATA'
pg_bindir='$LTHOME/bin'
failover='automatic'
promote_command='$LTHOME/bin/ltcluster standby promote -f $LTHOME/etc/ltcluster/ltcluster.conf'
follow_command='$LTHOME/bin/ltcluster standby follow -f $LTHOME/etc/ltcluster/ltcluster.conf --upstream-node-id=%n'
restore_command='cp $LTHOME/archive/%f %p'
monitoring_history=true #(Enable monitoring parameters)
monitor_interval_secs=2 #(Define monitoring data interval write time parameter)
connection_check_type='ping'
reconnect_attempts=3 #(before failover,Number of attempts to reconnect to primary before failover(default 6))
reconnect_interval=5
standby_disconnect_on_failover =true
failover_validation_command='$LTHOME/etc/ltcluster/ltcluster_failover.sh "$LTHOME" "$LTDATA"'
log_level=INFO
log_facility=STDERR
log_file='$LTHOME/etc/ltcluster/ltcluster.log'
shutdown_check_timeout=1800
use_replication_slots=true
check_lightdb_command='$LTHOME/etc/ltcluster/check_lightdb.sh'
check_lightdb_interval=10
5. DN1节点上执行以下两条命令:
ltcluster primary register -f $LTHOME/etc/ltcluster/ltcluster.conf –F
ltclusterd -d -f $LTHOME/etc/ltcluster/ltcluster.conf -p $LTHOME/etc/ltcluster/ltcluster.pid
此时DN1主已注册添加完成;
6. 在DN2节点服务器上使用LightDB安装包安装一个单机版数据库并创建实例,这里端口以5435为例,该实例作为DN1主的备节点;
7. 修改该实例配置文件$LTDATA/lightdb.conf中的shared_preload_libraries,添加ltcluster:
shared_preload_libraries='ltcluster,lt_stat_statements,lt_stat_activity,lt_prewarm,lt_cron,lt_hint_plan,lt_show_plans'
修改后重启数据库
8. 在DN2 5435库中执行以下三条SQL:
create extension ltcluster;
create role ltcluster superuser password 'ltcluster' login;
create database ltcluster owner ltcluster;
9. 停止DN2 5435实例,在DN2 5435的$LTHOME/etc/ltcluster下创建ltcluster.conf配置文件,内容如下(以下IP、端口、路径均针对为DN2 5435单机版数据库,此处仅作举例):
node_id=1305435
node_name='1231231231305435'
conninfo='host=123.123.123.130 port=5435 user=ltcluster dbname=ltcluster connect_timeout=2'
data_directory='$LTDATA'
pg_bindir='$LTHOME/bin'
failover='automatic'
promote_command='$LTHOME/bin/ltcluster standby promote -f $LTHOME/etc/ltcluster/ltcluster.conf'
follow_command='$LTHOME/bin/ltcluster standby follow -f $LTHOME/etc/ltcluster/ltcluster.conf --upstream-node-id=%n'
restore_command='cp $LTHOME/archive/%f %p'
monitoring_history=true #(Enable monitoring parameters)
monitor_interval_secs=2 #(Define monitoring data interval write time parameter)
connection_check_type='ping'
reconnect_attempts=3 #(before failover,Number of attempts to reconnect to primary before failover(default 6))
reconnect_interval=5
standby_disconnect_on_failover =true
failover_validation_command='$LTHOME/etc/ltcluster/ltcluster_failover.sh "$LTHOME" "$LTDATA"'
log_level=INFO
log_facility=STDERR
log_file='$LTHOME/etc/ltcluster/ltcluster.log'
shutdown_check_timeout=1800
use_replication_slots=true
check_lightdb_command='$LTHOME/etc/ltcluster/check_lightdb.sh'
check_lightdb_interval=10
10. DN2 5435备机克隆
ltcluster -h $DN1_PRIMARY_IP -p $DN1_PRIMARY_PORT -U ltcluster –d ltcluster -f $DN2_5435_HOME/etc/ltcluster/ltcluster.conf standby clone –F
(克隆时间根据DN1 主库大小时间不定)
克隆完成后修改DN2 5435的DATA/lightdb.conf,将port改为5435
port=5435
启动DN2 5435数据库;
11. DN2 5435注册为从节点
ltcluster standby register -f $LTHOME/etc/ltcluster/ltcluster.conf –F
ltclusterd -d -f $LTHOME/etc/ltcluster/ltcluster.conf -p $LTHOME/etc/ltcluster/ltcluster.pid
此时DN1主-DN2备高可用已完成;
12. 可使用以下命令查看DN的主备状态:
ltcluster –f $LTHOME/etc/ltcluster/ltcluster.conf cluster show
ltcluster –f $LTHOME/etc/ltcluster/ltcluster.conf service status
13. DN2主-DN1备环境搭建及CN备机的环境搭建与上述的DN1主-DN2备操作步骤相同,此处不再赘述。
手动添加witness节点
上节DN互为主备环境中并未部署witness节点,如果需要可以进行手动添加witness部署,具体安装步骤如下:
(注:以下部署流程中所设计的IP、端口、HOME/DATA等路径需根据实际环境进行替换为绝对路径,此处仅为举例说明)
1. 使用同一个安装包在新的服务器上安装一个单机版并创建实例(这里以创建的实例端口为以5432 为例);
http://www.light-pg.com/docs/LightDB_Install_Manual/current/install.html#id3
http://www.light-pg.com/docs/LightDB_Install_Manual/current/install.html#id9
2. 修改实例配置文件,vim $LTDATA/lightdb.conf,修改配置shared_preload_libraries,添加ltcluster (注:仅添加ltcluster,其他项无需改动)
shared_preload_libraries='ltcluster,lt_stat_statements,lt_stat_activity,lt_prewarm,lt_cron,ltaudit,lt_hint_plan,lt_show_plans,lt_standby_forward,lt_ope,lt_pathman'
3. 重启实例,lt_ctl -D $LTDATA start,然后配置ltcluster,执行以下命令:
$LTHOME/bin/ltsql -h 127.0.0.1 -p 5432 -d postgres -c"create extension ltcluster;"
$LTHOME/bin/ltsql -h 127.0.0.1 -p 5432 -d postgres -c "create role ltcluster superuser password 'ltcluster' login;"
$LTHOME/bin/ltsql -h 127.0.0.1 -p 5432 -d postgres -c "create database ltcluster owner ltcluster;"
4. 在$LTHOME/etc/ltcluster下创建witness配置文件 ltcluster.conf,内容如下:
node_id=3
node_name='1231231231305432'
conninfo='host=123.123.123.130 port=5432 user=ltcluster dbname=ltcluster connect_timeout=2'
data_directory='$LTDATA'
pg_bindir='$LTHOME/bin'
failover='automatic'
promote_command='$LTHOME/bin/ltcluster standby promote -f $LTHOME/etc/ltcluster/ltcluster.conf'
follow_command='$LTHOME/bin/ltcluster standby follow -f $LTHOME/etc/ltcluster/ltcluster.conf --upstream-node-id=%n'
restore_command='cp $LTHOME/archive/%f %p'
monitoring_history=true #(Enable monitoring parameters)
monitor_interval_secs=2 #(Define monitoring data interval write time parameter)
connection_check_type='ping'
reconnect_attempts=3 #(before failover,Number of attempts to reconnect to primary before failover(default 6))
reconnect_interval=5
standby_disconnect_on_failover =true
log_level=INFO
log_facility=STDERR
log_file='$LTHOME/etc/ltcluster/ltcluster.log'
failover_validation_command='$LTHOME/etc/ltcluster/ltcluster_failover.sh "$LTHOME" "$LTDATA"'
shutdown_check_timeout=1800
use_replication_slots=true
5. 将witness注册添加到环境中,执行以下命令:
$LTHOME/bin/ltcluster -f $LTHOME/etc/ltcluster/ltcluster.conf witness register -h192.168.11.128 -p 5432 -F
$LTHOME/bin/ltclusterd -d -f $LTHOME/etc/ltcluster/ltcluster.conf -p ${LTHOME}/etc/ltcluster/ltcluster.pid
6. 可使用以下命令查看DN的主备状态:
ltcluster –f $LTHOME/etc/ltcluster/ltcluster.conf cluster show

ltcluster –f $LTHOME/etc/ltcluster/ltcluster.conf service status

分布式实践
LihgtDB分布式模式通过上述步骤安装后,分布式集群会默认部署在postgres库中,针对其他业务库,需手动将CN和DN节点添加到pg_dist_node表中。
查看分布式节点信息:select * from pg_dist_node;
设置分布式CN节点:select canopy_set_coordinator_host('CN_NODE_IP', CN_NODE_PORT);
添加分布式DN节点:select master_add_node('DN_NODE_IP', DN_NODE_PORT); -- 在CN节点上执行该步骤即可,对应的DN节点会同步分布式集群信息
删除节点:select canopy_remove_node('NODE_IP', NODE_PORT);

上图中5437为CN节点,65501~65503为DN节点,四个节点部署在同一台服务器中。
分布式表类型
1. 分布表
分布式表是跨数据节点的水平分区(即,分片),可通过select create_distributed_table函数来进创建。
LightDB Canopy默认使用Hash算法来将数据分配给分片,分片的规则需依赖特殊的分布列来进行划分不同的分片,因此在创建分布表时必须指定此列。
分布式表的数据存储在DN节点上。
2. 参考表
参考表是一种分布式表,它的全部内容集中在一个分片中,在每个数据节点上复制该内容。因此,对任何数据节点的查询都可以在本地访问参考表,无需从另一个节点请求行而带来的网络开销。参考表没有分布列,因为不需要区分每行的不同切分,可通过select create_reference_table函数来进创建。
参考表通常很小,用于存储与在任何数据节点上运行的查询相关的数据,例如,订单状态或产品类别等枚举值等。
参考表的数据存储在DN节点上。
3. 本地表
本地表一般不会和广播表、分布表进行关联,默认CN创建表的时候就是local表,也可以通过select undistribute_table('github_events');将分布表切换回local表(此时会数据先迁移回来,也是缩容的一种方式)。
本地表的表结构和数据仅存储在当前数据库实例中。
广播表和分库表,广播表和广播表之间关联会很多。同时会存在多种业务存在于同一个数据库中的情况,例如库存和客户,操作日志和订单,小二和菜单、功能、客户,并且同时有从菜单维度查,也有从小二维度查。所以LightDB Canopy支持对表进行分组,相关分组的表,LightDB Canopy在生成分布式执行计划的时候就知道哪些是相关的,哪些是无关的。如下:
SELECT create_distributed_table('event', 'tenant_id');
SELECT create_distributed_table('page', 'tenant_id', colocate_with
=> 'event');
分组的前提是两个表使用相同字段作为分片字段。分组可以使得SQL的优化更加进一步。
通常会发现库存和客户表进行关联,是通过订单进行的。这个时候库存是根据产品分片的,客户是通过客户id分片的。
不同于greenplum支持distributed by语法,LightDB Canopy采用extension实现,用函数的方式来指定表是否为分布式表。
CREATE TABLE companies (
id bigserial PRIMARY KEY,
name text NOT NULL,
image_url text,
created_at timestamp without time zone NOT NULL,
updated_at timestamp without time zone NOT NULL
);
SELECT create_distributed_table('companies', 'id'); -- companies表为分布式表,id是用于分片的字段
需要注意的是,LightDB Canopy分片数量和worker数量不是一一对应,这和gp不同,但类似于现在tidb、oceanbase的做法。如下:

可以使用以下命令查询库中所有的分布式表:
select * from canopy_tables;
分片和规则
协调节点上的pg_dist_shard元数据表包含系统中每个分布式表的每个分片的信息。每一行匹配一个shardid和一个Hash空间中的整数范围(shardminvalue, shardmaxvalue):
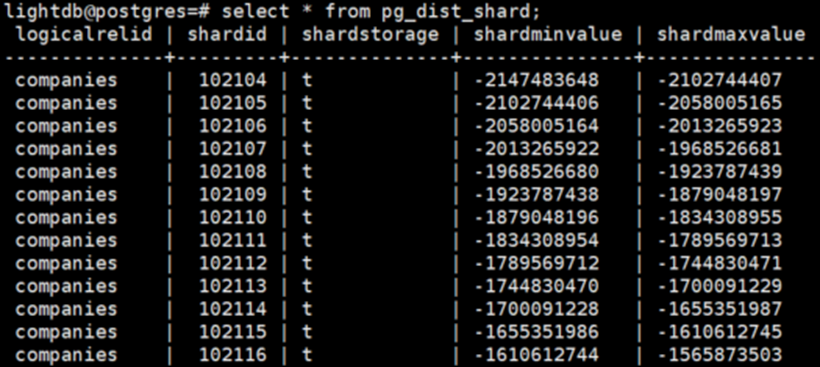
如果协调节点希望确定哪个分片包含companies行,需要根据Hash该行中的分布列的值,检查哪个shard的范围包含该Hash值。假设要查询的行与分片102104相关联,那么应该将行读写到一个数据节点中名为companies _102104的表中。具体是哪个数据节点,这完全由元数据表决定,可通过pg_dist_shard_placement表查看到所有分片在DN节点上的分布情况。
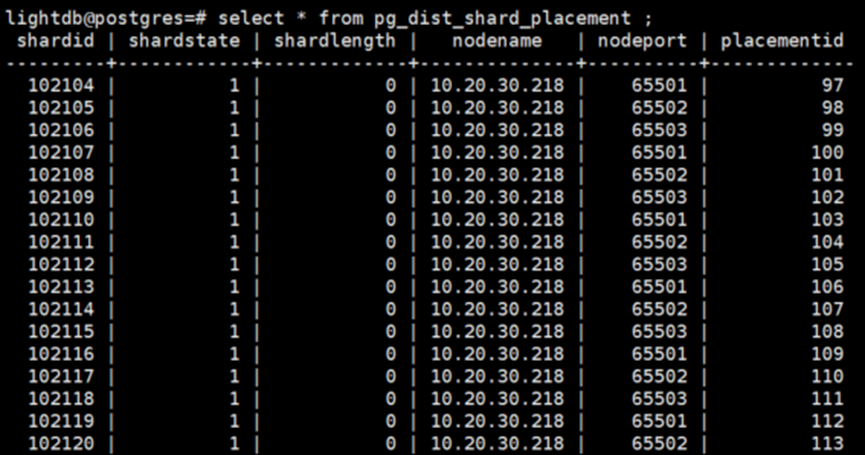
由上图可知102104分片分布在65501端口的DN中。
或者可通过以下查询来确定对应分片所在的节点信息:
SELECT
shardid,
node.nodename,
node.nodeport
FROM pg_dist_placement placement
JOIN pg_dist_node node
ON placement.groupid = node.groupid
AND node.noderole = 'primary'::noderole
WHERE shardid = 102104;
shardid | nodename | nodeport
---------+--------------+----------
102104 | 10.20.30.218 | 65501
(1 row)
在表跨集群分布时,每个表的分片数量是可配置的。分片数量的最佳选择取决于具体的使用场景。
分布式表的分片方式具体可分为Hash分片(根据列的Hash进行分片)和range分片(根据列的值进行分片)。分片方式可通过pg_dist_partition表来进行查询。

上图中partmethod字段,h代表根据hash值分区,r代表根据列值分区。
默认情况下,Hash分片为均匀的,可以直接对Hash值和分片数相除,获取分片编号。
如:Hash值是32,节点数是16 (32+2147483648)/(4294967296/16),分配在8上,如果分片编号等与分片总数,则分片编号是分片总数-1。
选择分布列
LightDB Canopy 使用分布式表中的分布列将表行分配给分片。为每个表选择分布列是最重要的建模决策之一,因为它决定了数据如何跨节点分布。
如果正确选择了分布列,那么相关数据将在相同的物理节点上组合在一起,从而使查询快速。如果列选择不正确,可能会导致系统缓慢运行,并且无法支持跨节点的 SQL 功能。具体可参考上一节的分片和规则,结合实际的业务场景来进行合理的设计分片列。
新增节点
新增节点后,默认不会启用分布式集群,需要调用rebalance_table_shards让LightDB Canopy对数据进行迁移,然后才会被访问。
SELECT rebalance_table_shards('companies');
具体步骤可参考:https://www.cnblogs.com/xxl-cr7/p/17170589.html
DML
正常的高可用主备环境,备机是无法执行DML的。协调节点属于Master-Standby架构,仅CN节点支持数据写入,势必会有单点可入瓶颈。例如在CN-Standby备机中执行insert,会报如下错误:
ERROR: cannot execute INSERT in a read-only transaction
ERROR: writing to worker nodes is not currently allowed
DETAIL: the database is read-only
在LightDB分布式环境中,当将参数canopy.writable_standby_coordinator由默认off改为on时,此时会使CN-Standby备节点中的分布式表也支持DML,比如insert等操作,使得写入能力得到扩展。具体启用CN-Standby节点支持DML步骤如下:
1. 执行命令确认当前CN主备状态是否正常:
ltcluster –f $LTHOME/etc/ltcluster/ltcluster.conf service status(在CN主或备服务器上执行均可)

2. 修改CN备节点的配置文件($LTDATA/lightdb.conf),在配置文件中增加以下命令,完成后保存退出文件;
canopy.writable_standby_coordinator = on
3. 重启CN备节点,命令如下:
lt_ctl -D $LTDATA restart
4. 进入CN备节点中,此时分布式库中的分布式表已可以支持DML操作。
性能优化
co-location是分布式数据库性能好坏和扩展性的关键。
如果实在无法实现colocation,可通过LightDB逻辑复制,尽可能避免下列操作:
1、agg(distinct value2),带distinct的聚合函数;
2、分析函数<window_function>() OVER (PARTITION BY
<...> ORDER BY <...> <window_frame>);
3、任意字段排序和分页查询;
注:对于这三种情况,gp的interconnect也无能为力,CN必然是瓶颈,流式计算也不能解决to B端的问题,只能靠更加智能的算法和空间换时间。
常见问题
当对数据进行哈希分区时,如何选择分片计数
在多租户数据库用例中,建议分片数量在32到128个分片之间进行选择。对于小于100GB的较小工作负载,可以从32个分片开始,对于较大的工作负载,可以选择64或128个分片。这意味着可以从32台worker扩展到128台worker。
在实时分析用例中,分片计数应该与工作线程上的核心总数相关。为了确保最大的并行性,应该在每个节点上创建足够的分片,以便每个CPU核心至少有一个分片。通常建议创建大量的初始分片,例如当前CPU内核数量的2倍或4倍。如果想添加更多的worker和CPU核心,允许在将来进行扩展。
使用canopy.shard_count参数为要分发的表选择分片计数。这会影响后续对create_distributed_table的调用。
mx架构下DN节点自增主键报错
报错信息:"nextval(sequence) calls in worker nodes are not supported for column defaults of type int or smallint"
原因:dn节点不支持nextval特性,需要使用人工生成的主键,比如雪花ID。
/*
* worker_nextval calculates nextval() in worker nodes
* for int and smallint column default types
* TODO: not error out but get the proper nextval()
*/
Datum
worker_nextval(PG_FUNCTION_ARGS)
{
ereport(ERROR, (errmsg(
"nextval(sequence) calls in worker nodes are not supported"
" for column defaults of type int or smallint")));
PG_RETURN_INT32(0);
}
分区键的要求(唯一约束必须包含分片键)
DETAIL: Distributed relations cannot have UNIQUE, EXCLUDE, or PRIMARY KEY constraints that do not include the partition column (with an equality operator if EXCLUDE).
这个错误提示在 Canopy 中创建了一个分布式表,并且在表上定义了 UNIQUE、EXCLUDE 或 PRIMARY KEY 约束,但约束中没有包含分区列(或分区列的一部分),因此 Canopy 无法在分布式环境中正确地强制执行这些约束。
在 Canopy 中,数据通常被分区并存储在不同的节点上,每个节点上存储的数据子集只能部分地表示分布式表的完整数据集。这就需要 Canopy 在整个分布式集群上保证数据一致性和正确性,因此 Canopy 需要在分布式表上使用分区键或分区键的一部分来定义这些约束。
分布式表和本地表不支持直接join
SQL 错误 [0A000]: ERROR:
direct joins between distributed and local tables are not supported
Hint: Use CTE's or subqueries to select from local tables and use them in joins
这个错误提示是因为 Canopy不支持在分布式表和本地表之间进行直接连接操作。
在 Canopy中,分布式表是由多个节点上的数据子集组成的,而本地表只存在于单个节点上。由于分布式表和本地表之间的数据分布不同,Canopy不能有效地执行这种连接操作。
相反,可以使用公共表表达式 (CTE) 或子查询来从本地表中选择数据,然后将其与分布式表连接。例如:
WITH local_data AS (
SELECT *
FROM my_local_table
)
SELECT *
FROM my_distributed_table
JOIN local_data ON my_distributed_table.key = local_data.key
参考资料
http://www.light-pg.com/docs/canopy/current/index.html
https://blog.51cto.com/zhjh256/5927620


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)
· Vue3状态管理终极指南:Pinia保姆级教程