
Set集合
Set接口
- 没有索引
- 底层是
hashMap 加载因子 默认是 0.75
加载因子 默认是 0.75 - 无序,哈希值
- 元素不能重复
数据结构
本质就是 数组+链表
Node[] table = new Node[16]这是一个 Node节点 的数组,所以 节点 还可以挂载节点,就成为了 链表
二者结合就是
HashMap(HashSet)


遍历
所以不能使用 普通for
hashSet
数组 + 链表,线程不安全
结论
添加元素的时候,会计算元素的哈希值,同一个元素的哈希值一定相同,相同哈希值的元素不一定相同,根据 hash 值得到元素应该存放的 数组的索引值
链表长度大于8转换为红黑树

底层原理
执行代码
table: 是HashMap中的存放 Node<K,V>[] 数组的属性值threshold:存放的hashMap扩容的阈值,临界点,计算方式负载因子 * 当前的table长度

1.无参构造
实际创建的是 hashMap 结构
2.
add方法**返回的是
null才代表添加成功 **
3.
put方法
计算
hash,key就是我们之前add那个元素,value是一个空的Object个人看法:Value 他是一个 不会改变的 null Object对象,只为了重写计算 hashCode,以及 equals 重写存在
**注意,
hash方法得出的不是单纯的 hashCode 的值,还有其他的运算 **如果
key为null,也就是添加的元素是 null,默认放到 Node数组 索引为 0 的位置4. 出来,进入
putVal方法final V putVal(int hash, K key, V value, boolean onlyIfAbsent, boolean evict) { Node<K,V>[] tab; Node<K,V> p; int n, i; //if 语句表示当前的 table 是 null 的话,或者大小为 0,就进行第一次 resize,也就是 扩容 if ((tab = table) == null || (n = tab.length) == 0) n = (tab = resize()).length; // table 的索引位置没有元素,为 null //(1)根据key,得到 hash 去计算该 key 应该存放在在 table 表的哪一个索引位置,并且将这位置对象 赋值 给 p //(2)判断 p 是否为 null //若 p == null,表示这个 table 的位置还没有存放元素,就创建一个 Node(key=“java”,value=PRESENT)对象 //这个对象就存放在这个 table数组 的索引空位置上,tab[i] = newNode(hash,key,value,null) if ((p = tab[i = (n - 1) & hash]) == null) tab[i] = newNode(hash, key, value, null); //将添加的元素放到 table 中 //table 的索引位置有元素,不为 null else { Node<K,V> e; K k; //辅助变量 //如果当前索引位置对应的链表第一个元素(节点)和准备添加的 key 的 hash 值一样的 //并且满足一下条件之一: //(1)准备添加的 key 和 p(当前 hash 计算出来的table位置)指向的 Node 节点的 key 是同一个对象 //(2)p 指向的 Node 节点的 key (Node节点有 key 和 value 属性)的 equals 和 准备加入的 key 比较 后相同,(注意:equals 方法取决我们是否重写,有我们定义比较的是是什么,比如 String 比较的内容) //那么就不能加入,赋值 辅助的 e Node 节点不为 null if (p.hash == hash && ((k = p.key) == key || (key != null && key.equals(k)))) e = p; //判断 p 是不是一颗 红黑树 //是,就调用 putTreeVal (比较复杂)方法,进行添加 key 元素 else if (p instanceof TreeNode) e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value); //如果table对应的索引位置已经是一条链表了,就使用 for 循环进行 循环比较 //(1)依次和链表每一个元素进行比较,相同的话,直接 break 退出 //(2)不相同的话,则加入到链表的最后位置 // 注意:吧元素添加到链表后,立即判断 链表的长度是否已经达到了 8 个节点,是的话,就调用 treeifyBin 方 法,将当前的链表树化(转成红黑树) // 注意:转成红黑之前,也就是 treeifyBin 方法里面还有一个条件 // (1)需要满足 table 的数组的长度已经 大于或等于 64 了 // 如果该条件不成立的话,先进行将 table 扩容,之前的链表节点会因为重新进行排序,就不会超过 8 了 else { for (int binCount = 0; ; ++binCount) { //p 下一个节点为 null,直接赋值 key 元素,直接添加成功的话,e 还是 null if ((e = p.next) == null) { p.next = newNode(hash, key, value, null); //添加完元素,立马判断 链表的长度,是否大于等于 7,因为从 0 开始计算的 if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st //树化 treeifyBin(tab, hash); break; } //e 是 p 下一个节点 //判断 准备添加的元素 key 是否和 链表中元素 相同 if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) break; //p 充当了辅助变量,为了 e 循环之后等于 p.next.next p = e; } } //(1)添加失败 //(2)添加到了链表上 //(3)添加了红黑树上 if (e != null) { // existing mapping for key V oldValue = e.value; if (!onlyIfAbsent || oldValue == null) //同一个 key,进行 value 的替换,hashMap 专属,set 没用 e.value = value; //value替换,只不过 set集合 value 都是 PRENSENT,对 hashMap 有用 afterNodeAccess(e); //返回 旧值,表示添加失败 return oldValue; } } ++modCount; //记录修改次数 //size 每一次添加元素成功就进行 ++ //如果 size 达到了 12 ,就行扩容 resize if (++size > threshold) resize(); afterNodeInsertion(evict); //该方法是空的,是给 hashSet 的子类进行实现的 return null; //null,代表的是添加成功了 }
treeifyBin方法
5. 扩容方法
resize扩容为 table 数组长度的 2 倍
// resize 调整大小意思 final Node<K,V>[] resize() { //table 是 HashMap 的属性,存放的是 Node<K,V>[] Node<K,V>[] oldTab = table; //辅助变量 int oldCap = (oldTab == null) ? 0 : oldTab.length; int oldThr = threshold; int newCap, newThr = 0; //table 不为 0,之后的 扩容 才会进入这里 if (oldCap > 0) { if (oldCap >= MAXIMUM_CAPACITY) { threshold = Integer.MAX_VALUE; return oldTab; } //newCap 新的 table 长度赋值为 table.length * 2 //原数组大小大于16时,临界值设置为原来的两倍 else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY && oldCap >= DEFAULT_INITIAL_CAPACITY) //阈值(扩容临界点变为 之前的 2倍) newThr = oldThr << 1; // double threshold } //意味着老数组没有元素 else if (oldThr > 0) // initial capacity was placed in threshold newCap = oldThr; //初始容量设置为临界值 else { // zero initial threshold signifies using defaults //说明是调用无参构造器创建的旧数组,并且第一次添加元素 newCap = DEFAULT_INITIAL_CAPACITY; //指定 Node<K,V> 数组的大小,默认是 16 // 加载因子 0.75 * 16 = 12 , 12 就是扩容机制的触发容量大小 newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY); } if (newThr == 0) { float ft = (float)newCap * loadFactor; newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ? (int)ft : Integer.MAX_VALUE); } //保存扩容触发点,加载因子 0.75 是通过泊松分布计算而得 threshold = newThr; @SuppressWarnings({"rawtypes","unchecked"}) Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap]; //创建 16 容量的 Node<K,V>[] 数组 newTab table = newTab; //赋值 newTab 给 HashMap 的属性 Node<K,V>[]数组 table,记录作用 //原数组不为空,说明是扩容操作,则涉及到元素转移操作 //扩容之后,链表的节点的位置调动,复杂 if (oldTab != null) { for (int j = 0; j < oldCap; ++j) { Node<K,V> e; //如果当前位置元素不为空,那么需要转移该元素到新数组 if ((e = oldTab[j]) != null) { //置空 oldTab[j],便于虚拟机回收 oldTab[j] = null; //如果 e 的后结点为空,则计算 e 在 newTab 中的位置并置入 if (e.next == null) //如果这个oldTab[j]就一个元素,那么就直接放到newTab里面 // 把元素存储到新的数组中,存储到数组的哪个位置需要根据hash值和数组长度来进行取模 // 【hash值 % 数组长度】 = 【 hash值 & (数组长度-1)】 // 数组扩容后,所有元素都需要重新计算在新数组中的位置。 newTab[e.hash & (newCap - 1)] = e; //如果此时 e 已经转为红黑树结点 else if (e instanceof TreeNode) ((TreeNode<K,V>)e).split(this, newTab, j, oldCap); else { // e 有后结点 Node<K,V> loHead = null, loTail = null; Node<K,V> hiHead = null, hiTail = null; Node<K,V> next; do { next = e.next; //重点难点!!! //与运算 & 是 两个位都为1时,结果才为1 //(e.hash & oldCap) 得到的是 元素在数组中的位置是否需要移动 // 示例1: // e.hash=10 0000 1010 // oldCap=16 0001 0000 // & =0 0000 0000 比较高位的第一位 0 //结论:元素位置在扩容后数组中的位置没有发生改变 // 示例2: // e.hash=17 0001 0001 // oldCap=16 0001 0000 // & =1 0001 0000 //结论:元素位置在扩容后数组中的位置发生了改变,新的下标位置是原下标位置+原数组长度 if ((e.hash & oldCap) == 0) {//扩容后不需要移动的链表 if (loTail == null) loHead = e; else loTail.next = e; loTail = e; } else {//扩容后需要移动的链表 if (hiTail == null) hiHead = e; else hiTail.next = e; hiTail = e; } } while ((e = next) != null); if (loTail != null) { loTail.next = null; newTab[j] = loHead; } if (hiTail != null) { hiTail.next = null; newTab[j + oldCap] = hiHead; } } } } } //返回的是 newTab 辅助数组,避免把 table 修改了,不安全 return newTab; }




扩容机制结论
table长度,threshold阈值(扩容临界点)都是 2 倍增长,也就是第一次 默认的 负载因子是 0.75,计算 默认的 table 长度 16,得到 默认的 临界点 12,之后都是进行的 翻倍 计算
注意:
size 是元素添加成功就进行加加,所以就是 元素添加的数量,达到了 临界点
threshold之后就进行扩容了resize,而不是 元素在 table 数组上面添加了 临界点个元素才会进行的 ++
问题
1.
hashmap如果计算出来的索引基本都不一样,那么不是需要进行创建很大的数组进行存储第一个链表的元素,hashCode的重复率很高吗?
2. size 为什么是每添加成功一个元素就进行++,不是元素添加了 table 的上才会 ++ 吗?

3.为什么重写需要
hashCode、equals一起?
因为源码中判断 hashcode、equals 的条件是 &&(与),也就是两者都为 true 才行(两者都 true 就判断为相同元素,不添加)
例子:(添加两个自定义的对象,属性都一样
new Dog(“掉毛”,18))因为重写了 hashcode,第一个 hash 条件确实是 true 了,但是第二个 equals 加入没有重写比较的是 地址,所以还是 false,就会添加成功,同理重写equals、不重写hashcode一样,直接 hash 出来的索引位置不一样,直接存进去

重写hashCode和equals
使用Lombok插件注意了,他自动重写了hash方法
快捷键
Alt + Insert,选择 重写 hashCode、equals


LinkedHashSet(了解)
数组 + 双向链表,其实和 HashSet 大体一样,只不过是多了双向(添加的元素的双向,而不是 table 数组上面的链表的双向),所以添加的元素变得有序了
原理图
LinkedHashSet加入的顺序和取出元素/数据的顺序是一样的LinkedHashSet底层 维护的是一个LinkedHashMap(是HashMap的子类)LinkedHashSet底层结构(数组table + 双向链表)- 添加一次时候,直接将 数组table 扩容到 16 ,存放的节点类型是
LinkedHashMap$Entry- 数组是
HashMap$Node[]存放的元素/数据是LinkedHashMap$Entry的类型
跟一遍源码,弄清楚双向链表在哪加的,还有就是 entry
底层原理
执行代码
1. 无参构造
创建的是
LinkedHashMap
LinkedHashSet的属性head、tail初始化
2.
add方法
基本和
hashSet一样的流程,只不过创建的newNode新元素的不太一样(LinkedHashMap重写了)就是 多了一个
linkNodeLast方法,将
这个是
HashSet创建新节点 Node(HashMap的方法)小知识
hashSet的 table 数组、链表 都是 Node 节点对象组成的
linkedHashSet的 table 数组是 Node 节点的数组,但是 链表是 Entry 对象构成的节点
Entry对象中包含了 after、before,也就是 next、prev,双向链表的指针,而且还包含了Node节点对象







treeSet
- TreeSet的无参构造器本来就是按照字符串大小来排的
- treeset无参构造就是无序的,你们输出的有序的是因为String或者Integer里实现了Compareto()
底层原理
代码逻辑
1.有参构造
因为默认比较器是 null,所以是无序的,但是如果存储的的是 String 对象,自带 Comparator,实现自然排序
this()方法有参构造
CompareTo方法public int compareTo(String anotherString) { int len1 = value.length; int len2 = anotherString.value.length; int lim = Math.min(len1, len2); char v1[] = value; char v2[] = anotherString.value; int k = 0; while (k < lim) { char c1 = v1[k]; char c2 = v2[k]; if (c1 != c2) { return c1 - c2; } k++; } return len1 - len2; }2.选择比较器
如果比较器为空(也就是我们没有自定义比较器),就使用我们比较的对象的类型的 比较器
Comparator不为空,就使用 自定义的比较器,比如我们进行传参构造函数的时候就自定义的比较器
3.
add方法,添加元素
put方法,添加元素public V put(K key, V value) { Entry<K,V> t = root; //辅助变量 if (t == null) { //避免 key 为 null compare(key, key); // type (and possibly null) check root = new Entry<>(key, value, null); //root 被赋值为 当前添加的元素Entry size = 1; modCount++; return null; } int cmp; Entry<K,V> parent; // split comparator and comparable paths Comparator<? super K> cpr = comparator; //比较器不为 null if (cpr != null) { do { parent = t; cmp = cpr.compare(key, t.key); //第一次比较为 0,因为比较的是同一个元素 if (cmp < 0) t = t.left; //排序 else if (cmp > 0) t = t.right; //排序 else return t.setValue(value); //假如为 0 ,就说明两个是一样的(比较方式决定),直接返回,值替换,但是这里是 treeSet,value都是一个固定的值,不用管, treeMap 才需要管 } while (t != null); } //没有比较器,获取 当前比较的对象的类型实现的比较器 Comparator,比如String实现的,默认是自然排序 else { if (key == null) throw new NullPointerException(); @SuppressWarnings("unchecked") Comparable<? super K> k = (Comparable<? super K>) key; do { parent = t; cmp = k.compareTo(t.key); if (cmp < 0) t = t.left; else if (cmp > 0) t = t.right; else return t.setValue(value); } while (t != null); } Entry<K,V> e = new Entry<>(key, value, parent); if (cmp < 0) parent.left = e; else parent.right = e; fixAfterInsertion(e); size++; modCount++; return null; }






Set集合的去重机制

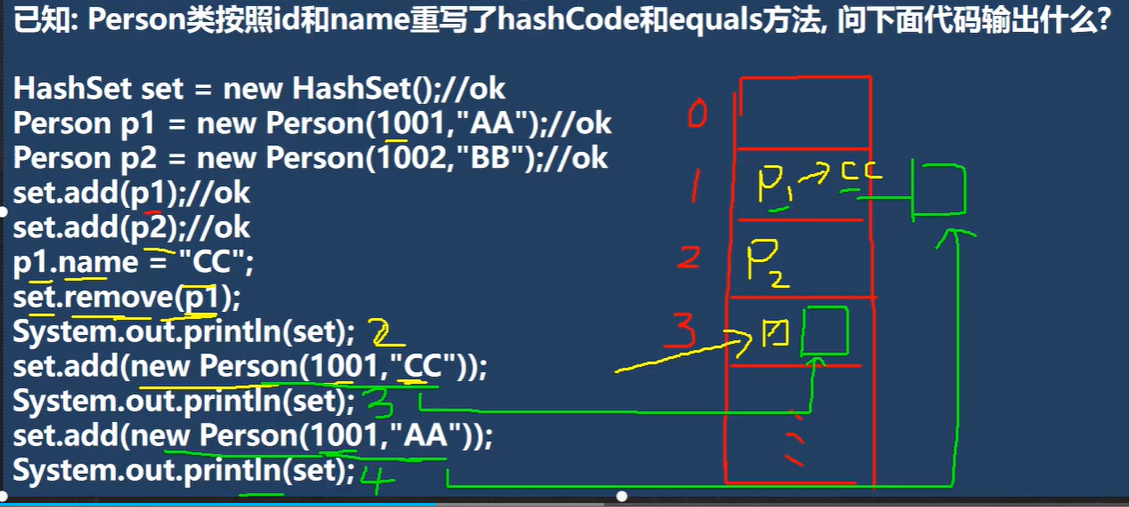
例题解析
重点在于 重写 了方法,如果是地址的话, p1 就会被删除 remove 了
解析:(全部添加成功)
添加 p1 的时候,放的是 1001,AA,但是之后改成了 CC
因为
hashcode被重写了,所以计算出来的索引位置很大可能是不一样的,比如 AA 的时候,索引是1,变成了 CC的时候,计算索引可能就是 3,那么就会 remove 失败,导致 P1 没有进行删除就是删除 p1 的时候,因为 p1 已经变成了 cc,所以remove计算应该是删除索引3的位置,而不是索引1的位置,所以导致 p1 没有删除成功,还是保留在了 索引1 的位置
p2 肯定是添加成功了
因为新的 new 的 1001,cc 计算的索引位置是 3,但是 3 位置没有元素,所以会被添加
虽然 索引 1 存放的也是 1001,cc,但是这个索引的位置 是通过 1001,AA 进行计算而得的
new 1001,AA,计算索引位置为 1,但是因为 p1 的name 已经改为了 CC,所以两者是不一样的,还是添加成功了
本文来自博客园,作者:小小俊少,转载请注明原文链接:https://www.cnblogs.com/xxjs168/articles/17486835.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号