

理解 node.js 的事件循环
node.js 的第一个基本观点是,I/O 操作是昂贵的:

目前的编程技术最大的浪费来自等待 I/O 操作的完成。有几种方法可以解决这些对性能的影响(来自 Sam Rushing):
同步:依次处理单个请求。
优点:简单。
缺点:任何一个请求都会阻塞其余请求。
创建新进程:为每个请求创建一个进程处理
优点:容易。
缺点:扩展性不好,数百个连接意味着数百个进程。fork()是 Unix 程序员的锤子。因为它很有用,所有的问题都像是钉子。但这通常是多余的。
线程:为每个请求创建一个线程处理。
优点:容易;由于线程的开销通常都很小,相比于使用 fork 对内核更友好。
缺点:你的机器可能没有线程,并且线程编程很容易变得复杂,也存在如何访问共享资源的问题。
第二个基本观点是,单线程连接非常消耗内存。
Apach 是多线程的:为每一个请求创建一个线程(或者进程,这取决于配置)。你可以看到增加当前连接数是如何消耗内存的,多个线程需要同时服务多个客户。Nginx 和 Node.js 不是多线程的,因为多线程和多进程会带来沉重的内存开销。它们是单线程的,但是基于事件的。通过单线程处理多个连接,解决数千个线程/进程的开销问题。
Node.js 为代码保持着单线程的运行环境
Node.js 确实是单线程运行的:你不能执行任何并发代码;例如“sleep”,这会使服务器停止。
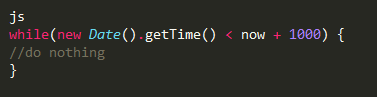
当代码运行时,node.js不会响应客户端的其他请求,因为它只有一个线程在执行代码。或者你可以使用一些 CPU-密集型代码,例如,调整图片尺寸,这仍然会阻塞其他请求。
然而,一切代码都能并行执行
并没有办法让代码在单线程中并行运行。除了所有的 I/O 操作和异步事件,以下代码并不会阻塞服务器:[codesyntax lang="javascript"]
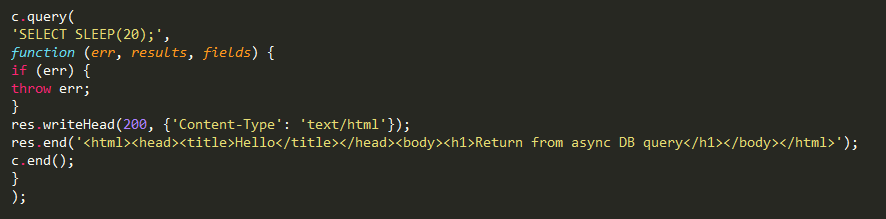
在一个请求中执行以上代码,数据库在休眠时其他请求也能被很好的处理。
这样有什么好处?我们什么时候应该将同步改为异步/并行执行?
同步执行是好方法,因为这使代码编写变得简单(与多线程相比,并发问题导致了 WTFs)。
在 node.js 中,你不需要担心后台会发生什么:只需要使用回调执行 I/O 操作;这保证了你的代码不会被中断,同时 I/O 操作不会阻塞其他请求,每个请求也不会增加线程/进程的开销(例如,Apache 中的内存开销)。
异步 I/O 操作也是好方法,因为 I/O 操作相较于大多数代码的执行更昂贵,我们应该做其他的事情,而不是等待 I/O 操作
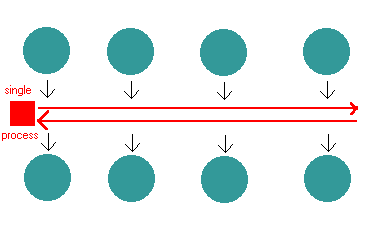
时间循环是“一个能够加工和处理外部事件并将它们转换为回调调用的实体”。因此 I/O 调用的关键在于 Node.js 能够从一个请求切换到另一个请求。在一个 I/O 调用中,代码会保存回调函数,并将控制权返回给 node.js 的运行时环境。当数据可用时回调函数将被调用。
当然,在后台中,有用于数据库访问和执行进程的线程和进程。然而,这并没有使代码暴露,因此你不需要为 I/O 操作担心,例如,数据库或者其他进程对于每一个请求都是异步的,这些线程的执行结果会通过事件循环返回给代码。与 Apache 模式相比,不需要为每个连接提供单个线程,因此需要更少的线程和线程开销;只有当真的需要并行运行时,即使管理权在 Node.js 也能够运行。
除了 I/O 操作的调用,Node.js 希望其他的所有请求都能迅速响应;例如:CPU-密集型工作应该被拆分到交互事件的进程中,或者像 WebWorkers 那样抽象的使用。(显然地)这意味着在后台没有其他的线程并发运行交互事件。基本上,所有的监听事件对象(都是 EventEmitter 的实例)都支持异步交互事件,你能够以这种方式与阻塞代码交互,例如使用 files,sockets 或者子进程,这些在 Node.js 中都是 EventEmitters。[多核][8]也可以使用这种方法,请参见:node-http-proxy
内部实现
在内部,node.js 依赖于 libev 实现事件循环,以 libeio 为辅助,使用混合线程实现异步 I/O 操作。要想学习更多,就需要查看 libev 的文档。
如何在 Node.js 中使用异步?
Tim Caswell 在他出色的演讲中描述了这种模式:
First-class 函数。例如,我们将函数作为参数传递,在需要的时候执行他们。
Function 形式。也被称作匿名函数或者闭包函数,当 I/0 操作完成后执行。
原文:Understanding the node.js event loop

