916数据结构与算法
前言
主要是记录下代码,根据考纲把一些简单算法记录下,方便学习和回忆。代码方面我尽量写的规范点,如果大家觉的不妥请自动脑部 = v =(算了,我还是为所欲为吧,毕竟自己爽的东西)
参考书是2021年王道数据结构,我写的是书上的补充,看时请配合书一起使用
请注意,我介绍的东西全部简化处理过了,就是有很多的定义,概念和高级算法直接舍去。原因很简单,因为我觉的它不会考,看了历年真题,考试只会考一些基础的东西,他不会让你去改进算法,不会太难。
为了确保我写的代码的准确性,我都会在oj上找题目做练习,算法前我都附上oj链接并测试,考试的时候只要把思想说清楚,关键的函数写出来问题就应该不大了。(为了应用题分数真的不容易)
我自己写的代码在这里https://github.com/taoyeh/DataStructure
简易版本请看这
考试重点
就两年真题,还能怎样。考试侧重点为:栈,二叉树,排序>图,队列,查找>复杂度,额外考点
#include<bits/stdc++.h> //万能头文件
请注意,考试重点考的是算法,是思想,不仔细看你每一步语法错还是对,请确保大抵方向对,还有C++它写起来方便多了。
基础
考试内容
- 计算机中算法的角色
- 算法复杂度分析
- 递归
计算机中算法的角色
算法的定义: 算法是解决特定问题求解决步骤的描述,再计算机中表现为指令的有限序列,并且每条指令表示一个或多个操作。其拥有五个重要特性:
1.有穷性2.确定性3.可行性4.输入5.输出
它的目标为:
1.正确性2.可读性3.健壮性4.效率和低储存量需求
算法复杂度分析
- 时间复杂度(考试重点)
- 空间复杂度
线性表
考试内容
- 基于顺序存储的定义和实现
- 基于链式存储的定义和实现
- 线性表的应用
基于顺序存储的定义和实现
线性表的顺序存储又称顺序表,特点为逻辑地址和物理地址相同
定义
静态分配
# define MaxSize 50
typedef struct
{
ElemType data[MaxSize];
int length;
}Sqlist
动态分配
# define InitSize 50
typedef struct
{
ElemType *data;
int length,MaxSize;
}Sqlist
申请空间
C言语版本 L.data=(ElemType*) malloc(sizeof(ElemType)*InitSize)
C++言语版本 L.data=new ElemType[InitSize]
我喜欢C++版本,我考场上我也写C++
实现:插入操作,删除操作和按值查找
插入操作:在顺序表L的第\(i(1\leq i\leq L.length+1)\)个位置插入新元素e。
bool ListInsert(SqList &L,int i,ElemType e)
{
if(i<=1 || i>L.length+1) return false; //判断是否合理
if(i>=MaxSize) return false; //判断是否满
for(int j=L.length;j>=i;j--)
L.data[j+1]=L.data[j];
L.length++;
return true;
}
删除操作:删除顺序表L的第\(i(1\leq i\leq L.length+1)\)个位置的元素
bool ListInsert(SqList &L,int i,ElemType &e)
{
if(i<=1 || i>L.length+1) return false; //判断是否合理
e=L.data[i-1] //判断是否满
for(int j=i;j<L.length;j++)
L.data[j-1]=L.data[j];
L.length--;
return true;
}
查找操作
基于链式存储的定义和实现
物理地址不一定连续
定义
typedef struct LNode
{
Elemtype data;
struct LNode *next;
}LNode,*LinkList;
头插法
LinkList List_HeadInsert(LinkList &L)
{
L=new LNode();
L->next=NULL;
int x;
while(scanf("%d",&x))
{
if(x==0) break;
LNode *s=new LNode();
s->next=L->next;
L->next=s;
s->data=x;
}
return L;
}
尾插法
LinkList List_TailInsert(LinkList &L)
{
L=new LNode();
L->next=NULL;
LNode *r=L;
int x;
while(scanf("%d",&x))
{
if(x==0) break;
LNode *s=new LNode();
r->next=s;
s->data=x;
s->next=NULL;
r=s;
}
return L;
}
遍历
void LocateElem(LinkList L)
{
LNode *p=L->next;
while(p!=NULL)
{
printf("%d\n",p->data);
p=p->next;
}
}
插入
void ListInsert(LinkList &L,int i,int e)
{
LNode *p=L;
int cnt=0;
while(cnt<i-1)
{
p=p->next;
cnt++;
}
LNode *s=new LNode();
s->data=e;
s->next=p->next;
p->next=s;
}
删除
void ListDelete(LinkList &L,int i)
{
LNode *p=L;
LNode *q=new LNode();
int cnt=0;
while(cnt<i-1)
{
p=p->next;
cnt++;
}
q=p->next;
p->next=q->next;
delete(q);
}
静态链表定义
# define MaxSize 50
typedef struct
{
ElemType data;
int next;
}Sqlist[MaxSize]
栈与队列
考试内容
- 栈、 队列、 字符串、 数组的基本概念、 特点
- 栈和队列基于顺序存储的定义与实现
- 栈和队列基于链式存储的定义与实现
- 稀疏矩阵的压缩存储及转置算法实现
栈
定义
typedef struct
{
Elemtype data[MaxSize];
int top;
}SqStack;
typedef struct Linknode
{
Elemtype data;
struct Linknode *next;
}*LiStack;
初始化
void InitStack(SqStack &S)
{
S.top=-1;
}
进栈
bool Push(SqStack &S,int e)
{
if(S.top==MaxSize-1) return false;
S.data[++S.top]=e;
return true;
}
出栈
bool Pop(SqStack &S,int &e)
{
if(S.top==-1) return false;
e=S.data[S.top--];
return true;
}
查看
bool GetTop(SqStack &S,int &x)
{
if(S.top==-1) return false;
x=S.data[S.top];
return true;
}
队列
定义
typedef struct
{
Elemtype data[MaxSize];
int front,rear;
}SqQueue;
初始化
void InitQueue(SqQueue &Q)
{
Q.front=Q.rear=0;
}
入队
bool EnQueue(SqQueue &Q,int x)
{
if((Q.rear+1)%MaxSize==Q.front) return false;
Q.data[Q.rear]=x;
Q.rear=(Q.rear+1)%MaxSize;
return true;
}
出队
bool DeQueue(SqQueue &Q)
{
if(Q.front==Q.rear) return false;
Q.front=(Q.front+1)%MaxSize;
return true;
}
查看
bool GetHead(SqQueue &Q,int &x)
{
if(Q.front==Q.rear) return false;
x=Q.data[Q.front];
return true;
}
括号匹配
问题描述http://acm.usx.edu.cn/AspNet/question.aspx?qid=9523
#include <stdio.h>
#include <string>
#include <iostream>
using namespace std;
#define MaxSize 50
typedef struct
{
char data[MaxSize];
int top;
}SqStack;
bool Push(SqStack &S,char e)
{
if(S.top==MaxSize-1) return false;
S.data[++S.top]=e;
return true;
}
bool Pop(SqStack &S,char &e)
{
if(S.top==-1) return false;
e=S.data[S.top--];
return true;
}
bool judge(SqStack &S,string s)
{
int i;
char ch;
for(i=0;i<s.size();i++)
{
if(s[i]=='('|| s[i]=='[') Push(S,s[i]);
else
{
if(S.top==-1) return false;
Pop(S,ch);
if (s[i]==')' && ch!='(' ) return false;
if (s[i]==']' && ch!='[' ) return false;
}
}
return S.top==-1;
}
int main()
{
string s;
while(cin>>s)
{
SqStack S;
S.top=-1;
if(judge(S,s)) printf("yes\n");
else printf("no\n");
}
return 0;
}
表达式
考了很多次了,其中后缀表达式为重点,那只讲后缀吧
左优先原则:只要左边的运算符能先计算,就优先计算
后缀表达式计算方法:
问题描述http://acm.usx.edu.cn/AspNet/question.aspx?qid=9518
#include <iostream>
#include <stack>
#include <string>
#include <iomanip>
using namespace std;
double soul(string s)
{
int sum=0,i;
for(i=0;i<s.size();i++)
sum=sum*10+(s[i]-'0');
return sum;
}
int main()
{
int n,i;
double a,b,c;
double sum;
string s;
while(1)
{
stack <double> S;
while(cin>>s)
{
if(s=="$") break;
else if(s=="+"||s=="-"||s=="*"||s=="/" )
{
a=S.top();
S.pop();
b=S.top();
S.pop();
if(s=="-") c=b-a;
else if(s=="+") c=a+b;
else if(s=="*") c=a*b;
else if(s=="/") c=b/a;
S.push(c);
}
else
S.push(soul(s));
}
sum=S.top();
S.pop();
cout<<fixed<<setprecision(2)<<sum<<endl;
}
return 0;
}
中缀转后缀方法
- 遇到操作符,直接加入后缀表达式
- 遇到界限符,如果是“(”打入栈,如果是“)”,弹出栈中所有运算符直到“(”,当然左右括号不加入后缀表达式
- 遇到运算符,依次弹出栈中优先级大于等于自己的的所有运算符,加入后缀表达式,若碰到“(”和栈空则停止。之后再把当前的运算符压入栈
- 不会考,放心 = v =
稀疏矩阵
一个二维数组中元素十分少,所以用一个三元组(行标,列表,值)记录所有的有效值,至于转置,把行标和列表互换就行。
串
只需看KMP中next和nextval,会手算就行,考纲里面没有要求
树
考试内容
- 二叉树
①二叉树的定义、 主要特征
②二叉树基于顺序存储和链式存储的实现
③二叉树重要操作的实现
④线索二叉树的基本概念和构造 - 树、 森林
①树的存储结构
②森林与二叉树的相互转换
③树和森林的遍历 - 特殊二叉树及应用
①哈夫曼(Huffman) 树
②二叉排序树
③平衡二叉树
④堆(堆的构造和调整过程)
二叉树
二叉树性质
- \(n_0=n_2+1\)
- 每层最多 \(2^{i-1}\)个结点(\(i \geq 1\))
完全二叉树
- n个结点的完全二叉树的高度为\(\lceil log_2(n+1) \rceil\) 或者为\(\lfloor log_2(n)+1 \rfloor\)
二叉树的基本操作
满二叉树或者完全二叉树适合顺序存储
struct TreeNode
{
Elemtype value;
bool isEmpty;
};
TreeNode t[MaxSize] ;
一般都是采用链式存储结构
typedef struct BiTNode
{
Elemtype data;
struct BiTNode *left ,*right;
}BiTNode,*BiTree;
建立
BiTree build()
{
char ch;
scanf("%c",&ch);
if(ch=='*')
return NULL;
BiTNode *root=new BiTNode();
root->data=ch;
root->left=build();
root->right=build();
return root;
}
先序
void PreOrder(BiTNode *T)
{
if(T!=NULL)
{
printf("%c",T->data);
PreOrder(T->left);
PreOrder(T->right);
}
}
中序
void InOrder(BiTNode *T)
{
if(T!=NULL)
{
InOrder(T->left);
printf("%c",T->data);
InOrder(T->right);
}
}
后序
void PostOrder(BiTNode *T)
{
if(T!=NULL)
{
PostOrder(T->left);
PostOrder(T->right);
printf("%c",T->data);
}
}
求深度
int TreeDepth(BiTNode *T)
{
if(T==NULL) return 0;
int l,r;
l=TreeDepth(T->left);
r=TreeDepth(T->right);
return l>r ? l+1:r+1;
}
层次遍历
void LevelOrder(BiTree T)
{
queue<BiTNode*>q;
q.push(T);
while(!q.empty())
{
BiTNode *node=q.front(); q.pop();
printf("%c",node->data);
if(node->left!=NULL) q.push(node->left) ;
if(node->right!=NULL) q.push(node->right) ;
}
}
根据前序,中序,后序三种中的两种构造唯一确定的树的方法,手会写就行
线索二叉树
考试要求为:线索二叉树的基本概念和构造
看来没有操作,看来懂就行,手会写就好了。(只要看中序)
定义
typedef struct ThreadNode
{
char data;
struct BiTNode *left ,*right;
int ltag,rtag; //1表示是线索,0表示是孩子
}ThreadNode,*ThreadTree;
树
树的存储方式
- 双亲表示法(纯数组)
- 孩子表示法(数组链表,指向孩子)
- 孩子兄弟表示法(纯链表,且最重要):森林与二叉树可以相互转换
孩子兄弟表示法定义
typedef struct CSNode
{
ElemType data;
struct CSNode *firstchild,*nextsibling;//第一个指向左孩子,第二个指向兄弟
}CSNode,*CSTree;
二叉树和森林相互转换:通过孩子兄弟表示法实现相互转化
树和森林的遍历
- 树的先根遍历和这棵树相应二叉树的先序序列是相同的
- 树的后根遍历和这棵树相应二叉树的中序序列是相同的
- 当然问你一颗树的先根(后根)遍历直接对其进行先序(后根)遍历就好了
- 对于森林的先根遍历则是对其各自子树进行先序遍历
- 对于森林的中序遍历则是对其各自子树进行类似后根遍历
- 反正就两种遍历 1.先序 2.不是先序
| 树 | 森林 | 二叉树 |
|---|---|---|
| 先根遍历 | 先序遍历 | 先序遍历 |
| 后根遍历 | 中序遍历 | 中序遍历 |
二叉排序树
又称二叉查找树(BST)
定义
typedef struct BSTNode
{
int data;
struct BSTNode *left,*right;
}BSTNode,*BSTree;
建立
void insert(BSTNode *&root,int x)
{
if(root==NULL)
{
root=new BSTNode();
root->left=root->right=NULL;
root->data=x;
return ;
}
if(root->data<x)
insert(root->left,x);
else if(root->data>x)
insert(root->right,x);
}
查找
BSTNode *BST_Search(BSTree T, int x)
{
while(T!=NULL&& T->data!=x)
{
if(T->data>x) T=T->left;
else T=T->right;
}
return T;
}
删除
- 若删除的结点为叶子结点,直接删
- 若删除的结点只有左子树或者右子树,使其替代
- 若删除的结点既有左子树又有右子树。找右子树的最小值替代或者找左子树的最大值替代,产生的后果再用前两种情况弥补
查找效率分析:
- 查找成功时:ASL=(\(\sum\)本层高度*本层个数)/结点个数
- 查找失败时:ASL=(\(\sum\)本层高度*本层补上的叶子个数)/补上的叶子个数
平衡二叉树
简称平衡树(AVL)
结点的平衡因子:左子树高-右子树高
- 插入新节点后为保持平衡,有四种解决方式,分别为:LL,RR,LR,RL。手会变换就行
- 每次调整的都是最小不平衡子树
- 每次调整的时候都要满足二叉排序树的特性
查找效率分析:查找一个关键词最多需要对比h次,即\(log_2n\)
哈夫曼树
WPL(带权路径长度)=\(\sum\) 路径长度*叶子结点权重
- 哈夫曼树构造方法:每次从集合中获得两个权重最小的结点,把他们从集合中删除,并让其成为兄弟结点,生成的新结点为两结点权重之和,并把新节点放入集合中。
- n个叶子结点的哈夫曼树总结点为2n-1
- 哈夫曼树不唯一,但WPL必然相同
- 哈夫曼编码:可变长度编码。 先构造哈夫曼树,向左走为0,向右走为1(当然相反也可以),叶子结点就有固定的编码了。
堆
在完全二叉树中,让根结点大于孩子结点,同样孩子结点也满足这样的条件我们叫做大根堆。若根结点小于孩子结点,同样孩子结点也满足这样的条件我们叫做小根堆(具体操作我们在堆排序里面讲)
图
考试内容
- 基本的图算法
- 最小生成树
- 单源最短路径
- 最短路径
- 最大流
定义
- G= (V,E)V为顶点,E为边。
- 线性表和树可以为空,但是图的顶点不能为空
- 若E为无向边,则称边。若E为有向边,则称弧。
- 一条弧中没有箭头的为弧尾,有箭头的为弧头。
- 我们谈论的都是简单图(没有重复边,不存在顶点到自己的边)
- 无向边的度(TD)为2e,有向图的度(TD)=出度(OD)+入度(ID)=e
- 无向图中顶点v和顶点w路径存在,则称连通。在有向图中,顶点v和顶点w相互有路径则称强连通
- 连通图:无向图所有顶点连通。强连通图:所有顶点强连通。
- 极大:边尽可能的多,极小:边尽可能的少
- 连通图的生成树是包含所有顶点的一个极小联通子图。
- 无向完全图:无向图任意两个顶点之间都存在边。有向完全图:有向图任意两个顶点之间都存在方向相反的两条弧。
存储方式
- 邻接矩阵:一个二维数组。其中\(A^n[i][j]\)表示由顶点i到顶点j长度为n的路径的数目
- 邻接表:一个一维数组加链表。
- 十字链表:存储有向图,解决了邻接表找入边不方便的问题
- 邻接多重表:存储无向图,删除边删除节点很方便
- 后两种考的少,懂就行
基本的图算法
- 广度优先遍历(BFS)
- 深度优先遍历(DFS)
- 时间复杂度:BFS和DFS一样,邻接矩阵O(\(|V|^2\)),邻接矩阵O(|V|+|E|)
最小生成树
- 最小生成树(MST)的树形是不唯一的
测试数据http://acm.usx.edu.cn/aspnet/question.aspx?qid=9561
Prime
#include <iostream>
using namespace std;
int map[12][12]; //图
int dist[12]; //距离
bool visit[12];//判断是否被放入树中
int inf=0x3f3f3f3f; //最大值
int n;// 顶点数
int m;// 边数
int cost;//代价
void Prime(int u)
{
int i,v;
//初始化
for(i=1;i<=n;i++) visit[i]=false;
for(i=1;i<=n;i++) dist[i]=inf;
for(i=1;i<=n;i++) dist[i]=map[u][i];
visit[u]=true;
for(v=0;v<n-1;v++)
{
int k=-1,mmin=inf;
for(i=1;i<=n;i++)
{
if(dist[i]<mmin && visit[i]==false) k=i,mmin=dist[i];
}
visit[k]=true;
for(i=1;i<=n;i++)
{
if(dist[i]>map[k][i] && visit[i]==false) dist[i]=map[k][i];
}
}
}
int main()
{
int i,j,x,y,z;
while(scanf("%d %d",&n,&m)!=-1) //输入数据
{
if(n==0 && m==0) break;
//初始化
for(i=1;i<=n;i++)
{
for(j=1;j<=n;j++) map[i][j]=inf;
map[i][i]=0;
}
for(i=1;i<=m;i++)
{
scanf("%d %d %d",&x,&y,&z);
map[x][y]=map[y][x]=z;
}
Prime(1);
cost=0;
for(i=1;i<=n;i++) cost+=dist[i];
printf("%d\n",cost);
}
return 0;
}
Kruskal
#include <iostream>
#include <algorithm>
using namespace std;
int inf=0x3f3f3f3f; //最大值
int n;// 顶点数
int m;// 边数
int cost;//代价
struct node
{
int from,to,w;//出发点,目的地,权重
}e[150];
int parent[12];
bool cmp(node a,node b)
{
return a.w<b.w;
}
int find(int x)
{
while(x!=parent[x]) x=parent[x];
return x;
}
bool join(int x,int y)
{
int fx=find(x);
int fy=find(y);
if(fx==fy) return false;
else parent[fx]=fy;return true;
}
void Kruskal()
{
int i,j,cnt=0;cost=0;
for(i=1;i<=n;i++) parent[i]=i;
for(i=1;i<=m;i++)
{
if(join(e[i].from,e[i].to)==true) cost+=e[i].w,cnt++;
if(cnt==n-1) break;
}
}
int main()
{
int i,j,x,y,z;
while(scanf("%d %d",&n,&m)!=-1) //输入数据
{
if(n==0 && m==0) break;
//初始化
for(i=1;i<=m;i++)
{
scanf("%d %d %d",&x,&y,&z);
e[i].from=x;e[i].to=y;e[i].w=z;
}
sort(e+1,e+m+1,cmp);
Kruskal();
printf("%d\n",cost);
}
return 0;
}
最短路径
测试数据http://poj.org/problem?id=2387
Dijkstra
#include <iostream>
#include <algorithm>
#include <cstring>
#include <cstdio>
using namespace std;
int inf=0x3f3f3f3f; //最大值
int n;// 顶点数
int m;// 边数
int map[1005][1005]; //图
int dist[1005];
bool visit[1005];
void Dijkstra(int u)
{
int i,v;
for(i=1;i<=n;i++) dist[i]=map[u][i];
visit[u]=true;
for(v=0;v<n-1;v++)
{
int k=-1,mmin=inf;
for(i=1;i<=n;i++) if(mmin>dist[i]&& visit[i]==false) k=i,mmin=dist[i];
visit[k]=true;
for(i=1;i<=n;i++)
{
if(dist[i]>dist[k]+map[k][i] && visit[i]==false ) dist[i]=dist[k]+map[k][i];
}
}
}
int main()
{
int i,j,x,y,z;
scanf("%d %d",&m,&n);
memset(map,inf,sizeof(map));
memset(dist,inf,sizeof(dist));
memset(visit,false,sizeof(visit));
for(i= 0;i<m;i++)
{
scanf("%d %d %d",&x,&y,&z);
if(z < map[x][y])
map[x][y] = map[y][x] = z;
}
Dijkstra(1);
printf("%d\n",dist[n]);
return 0;
}
Floyd
void Floyd()
{
int k,i,j;
for(k=1;k<=n;k++)
{
for(i=1;i<=n;i++)
{
for(j=1;j<=n;j++)
map[i][j]=min(map[i][j],map[i][k]+map[k][j]);
}
}
}
二分图(Bipartite Graph)
先插个题外话,介绍下二分图,2020考了个题,我大但的预测2021是不可能再考了,但还是记录下。其实按考纲来准确来说二分图的内容应该归为最大流。(因为他求解的方式是通过最大流)
二分图又称作二部图,是图论中的一种特殊模型。 设G=(V,E)是一个无向图,如果顶点V可分割为两个互不相交的子集(A,B),并且图中的每条边(i,j)所关联的两个顶点i和j分别属于这两个不同的顶点集(i in A,j in B),则称图G为一个二分图。
简而言之,就是顶点集V可分割为两个互不相交的子集,并且图中每条边依附的两个顶点都分属于这两个互不相交的子集,两个子集内的顶点不相邻。区别二分图,关键是看点集是否能分成两个独立的点集。如下图:
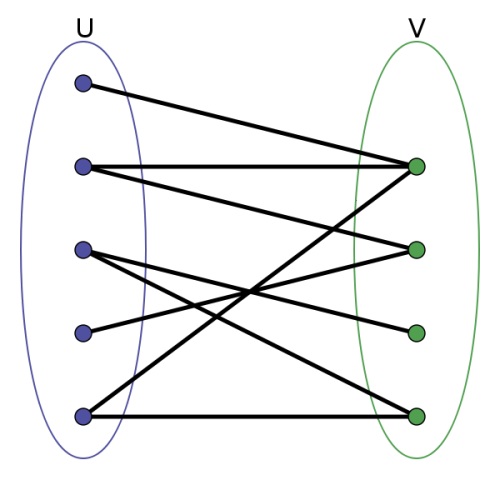
因为二分图本质来说不是考试内容,诸多性质和概念就不介绍了
- 最大匹配:边数最多的匹配
这是2020年宁波大学招生考试中的一题算法题

还是这张图,帮你清楚认知题目意思,有连线的就是彼此同意,没有连线就是彼此不同意,请注意,一旦学生1去了岗位1,学生2就不能去岗位1了,问你实习人数最大化就是求最大匹配
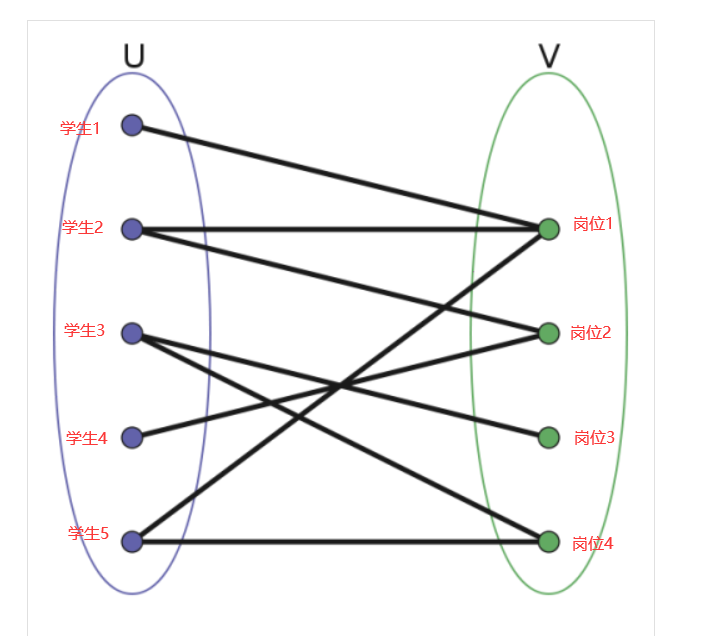
求二分图的方法很多,有匈牙利算法,Hopcroft-Carp算法等等,我们这边采用最大流(先学最大流回头再来做这题)
最大流(Maximum Flow)
太好,b站有大佬,https://www.bilibili.com/video/BV1eQ4y1K7db?from=search&seid=12110115477561942610,视频看起来生动形象,就很棒,因为考试不会去要求算法的优劣性,所以我们直接学一个最简单的FF算法就行了。
测试数据http://poj.org/problem?id=1273
FF算法模板如下
#include<iostream>
#include<stdio.h>
#include<string.h>
#include<math.h>
#include<algorithm>
using namespace std;
int map[300][300];
int used[300];
int n,m;
const int INF= 0x3f3f3f3f;
int DFS(int s, int t, int f)
{
if(s==t)
return f;//找到终点了,此时剩下的流量就是能获得的流量
int i;
for(i=1;i<=n;i++)
{
if(map[s][i] >0 && used[i] ==0)//从s开始找
{
used[i]=1;
int d=DFS(i, t, min(f, map[s][i]));//问有没有增广路
if(d>0)
{
map[s][i] -=d;
map[i][s] +=d;
return d;
}
}
}
return 0;
}
int maxflow(int s, int t)
{
int flow=0;
while(true)
{
memset(used, 0, sizeof(used));
int f= DFS(s,t, INF);//不断找s到t的增广路
if(f == 0)
return flow; //找不到了就回去
flow += f;//找到一个流量f的就赚了
}
}
void init()
{
memset(map, 0, sizeof(map));
return ;
}
int main()
{
while(scanf("%d %d", &m, &n) != EOF)
{
init();
int k1,k2, cap;
int i;
for(i=1;i<=m;i++)
{
scanf("%d %d %d", &k1, &k2, &cap);
map[k1][k2] += cap; //可能有多条路 ,所以要加,考试的时候直接写等于没什么关系
}
int ans=maxflow(1,n);
printf("%d\n", ans);
}
return 0;
}

最大流介绍到此,那么我们来思考下上述二分图的解决方法,其实也很简单,就是将连线的容值全部是看成是1,并且人为造一个汇源和汇点,最后的最大流就是我们的实习人数最大化,如下图:
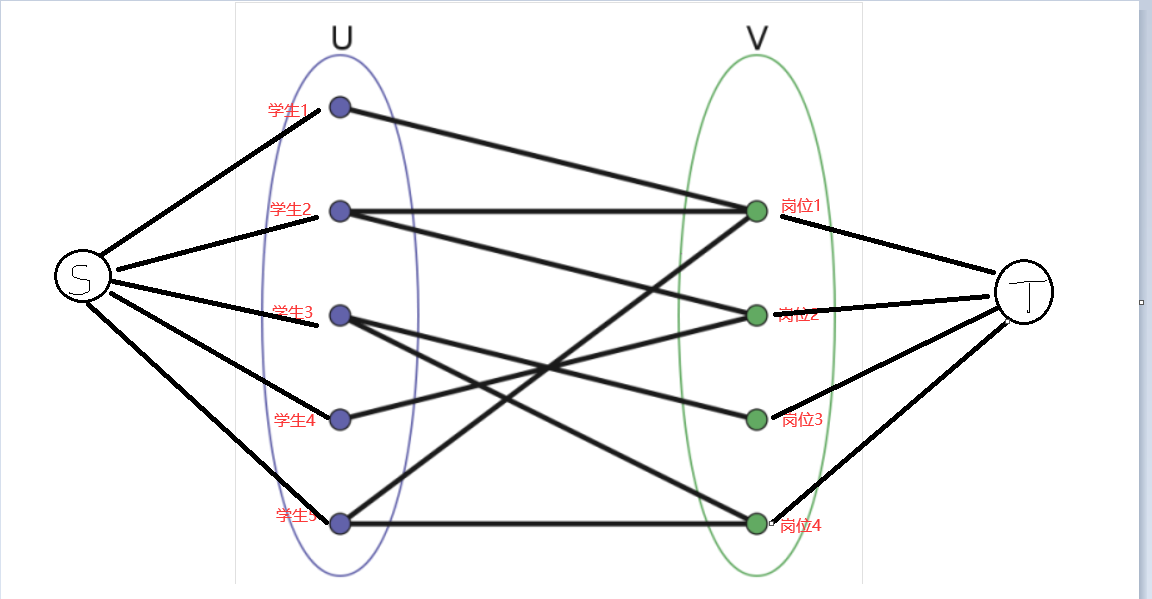
测试数据http://poj.org/problem?id=1274(一摸一样的二分图问题)
二分图解法:
#include<iostream>
#include<stdio.h>
#include<string.h>
#include<math.h>
#include<algorithm>
using namespace std;
int map[405][405];
int used[405];
int n,m;
const int INF= 0x3f3f3f3f;
int DFS(int s, int t, int f)
{
if(s==t)
return f;//找到终点了,此时剩下的流量就是能获得的流量
int i;
for(i=1;i<=n+m+2;i++)
{
if(map[s][i] >0 && used[i] ==0)//从s开始找
{
used[i]=1;
int d=DFS(i, t, min(f, map[s][i]));//问有没有增广路
if(d>0)
{
map[s][i] -=d;
map[i][s] +=d;
return d;
}
}
}
return 0;
}
int maxflow(int s, int t)
{
int flow=0;
while(true)
{
memset(used, 0, sizeof(used));
int f= DFS(s,t, INF);//不断找s到t的增广路
if(f == 0)
return flow; //找不到了就回去
flow += f;//找到一个流量f的就赚了
}
}
void init()
{
memset(map, 0, sizeof(map));
return ;
}
int main()
{
while(scanf("%d %d", &n, &m) != EOF)
{
init();
int num, cap;
int i,j,k;
for(i=1;i<=n;i++)
{
scanf("%d", &num);
for(j=0;j<num;j++)
{
scanf("%d", &k);
map[i+1][k+n+1]=1;
}
}
for(i=1;i<=n;i++) map[1][i+1]=1;
for(i=1;i<=m;i++) map[n+1+i][n+m+2]=1;
int ans=maxflow(1,n+m+2);
printf("%d\n", ans);
}
return 0;
}

查找
考试要求
- 顺序查找法
- 折半查找法
- B 树及其基本操作、 B+树的基本概念
- 散列(Hash)表
顺序查找法
又称为线性查找,顺式存储和链式存储都可以
typedef struct{
Elemtype *elem;
int TableLen;
}SSTable;
查找函数
int Search_Seq(SSTable ST,int key)
{
ST.elem[0]=key;
int i;
for(i=ST.TableLen;ST.elem[i]!=key;i--);
return i;
}
- 查找成功ASL=\(\sum_{i=1}^n \dfrac{1}{n}*i=\dfrac{1+n}{2}\)
- 查找失败ASL=n+1
如果是有序的情况下,查找失败不用遍历完顺序表,只要找到第一个比自己大(小)的元素就可以停止,把情况想象成一棵树,失败的情况有n+1种
查找失败ASL=\(\dfrac{1+2+...+n+n}{n+1}=\dfrac{n}{2}+\dfrac{n}{n+1}\)
折半查找法
又称二分查找,适用于原本有序的顺序表,是不能用于链表储存的。
查找函数
int Binary_Search(int SeqList[],int key)
{
int low=0,high=11,i,mid;
while(low<=high)
{
mid=(low+high)/2;
if(SeqList[mid]==key) return mid;
if(SeqList[mid]<key) low=mid+1;
else high=mid-1;
}
return -1;
}
查找成功和失败ASL情况和二叉排序树情况一样
- 查找成功时:ASL=(\(\sum\)本层高度*本层个数)/结点个数
- 查找失败时:ASL=(\(\sum\)本层高度*本层补上的叶子个数)/补上的叶子个数
- 折半查找的时间复杂度为\(O(log_2n)\)
- 折半查找的时候向上取整还是向下取整要确认好(一般都是向下取整 )
B树
B(B-)树又称多路平衡查找树
B树的操作会手算就行,定义和性质如下
- B树就是m叉查找树
- B树除了根结点以外,每个结点必须最少有\(\lceil m/2 \rceil\)-1个关键字,最多有m-1个的关键字
- B树规定任意一个结点,其所有子树的高度都要相同
- B树关键字的值:子树0<关键字1<子树1<关键字2<子树2
- n个结点B树的高度:\(log_m(n+1) \leq h \leq log_{\lceil m/2\rceil}((n+1)/2)+1\)
操作
- 查找:查找类似二叉查找树,不同之处B树是m叉查找树
- 插入:不断插入新结点的时候,当个数等于m时,从中间位置(\(\lceil m/2 \rceil\))将其中的关键字分为两部分,左部分的不动,右部分的放到新结点中,中间的结点插入到原结点的父节点中,产生的影响也也按这种方式处理
删除
- 若删除的是终端结点的情况下,
- 终端结点个数大于\(\lceil m/2 \rceil\)-1直接删除。
- 若个数等于\(\lceil m/2 \rceil\)-1时,不够删,则找左右兄弟借,若兄弟不够借,则将它和它的兄弟和它的父亲的一个结点合并,产生的影响也按删除的情况来解决。
- 若不是终端结点,找被删除结点的直接前驱(或后继)来替代,转化为终端结点删除的情况。
B+树
只要概念就好
- 每个分支节点最多有m课子树
- 每个非叶结点至少有两颗子树,其他至少要有\(\lceil m/2 \rceil\)课子树
- 结点的子树个数和关键字个数相等
- 所有的叶子结点包含所有的关键字及指向相应记录的指针,并且从小到大
散列(Hash)表
散列(Hash Table)又叫哈希表,特点是关键字与其存储地址直接相关,利用空间换时间
构造方法:
- 除留余数法(没错就考这个其他都不太行):H(key)=key%m,m为素数
- 直接定址法:H(key)=key 或者 H(key)=a*key+b,不会产生冲突,他适用于关键字的分布基本连续的情况
- 数字分析法:关键字为r进制数,r个数码在各位出现的频率不一定相同。(比如电话号码前几位都相同我们不做当关键字,但后面4位基本不相同我们就用它作为关键字)
- 平方取中法:关键字的平方值的中间几位作为散列地址
解决处理冲突的方法:
- 拉链法:用链表
- 开放地址法:一般都是都是用线性探测法。不同开放地址法只是\(d_i\)不同,H(key)=(key+\(d_i\))%m表示第i次冲突时H(key)的取值
查找长度:需要对比关键字的个数
- 成功时ASL=(\(\sum\)每个关键词比较个数)/关键词个数
- 失败时ASL=(\(\sum\)表中序号比较个数)/表长的有效个数
装填因子\(\alpha\)=表中记录数/散列表长度(装填因子越大,则查找效率越低)
排序
插入排序
- 直接插入排序:时间复杂度O(\(n^2\)) 是稳定的
void InsertSort(int A[],int n)
{
int i,j;
for(i=2;i<=n;i++)
{
if(A[i]<A[i-1])
{
A[0]=A[i];
for(j=i-1;A[j]>A[0];j--)
A[j+1]=A[j];
}
A[j+1]=A[0];
}
}
- 折半插入排序:时间复杂度O(\(n^2\)) 是稳定的
void Binary_InsertSort(int A[],int n)
{
int i,j,low,high,mid;
for(i=2;i<=n;i++)
{
if(A[i]<A[i-1])
{
A[0]=A[i];
low=1,high=i-1;
while(high>=low)
{
mid=(low+high)/2;
if(A[mid]>A[0]) high=mid-1;
else low=mid+1;
}
for(j=i-1;j>=high+1;j--)
A[j+1]=A[j];
A[high+1]=A[0];
}
}
}
- 希尔排序 :时间复杂度O(\(n^{1.3}\)) 是不稳定的
别上代码了,大题目不会考的,会手算就行
交换排序
- 冒泡排序:时间复杂度O(\(n^2\)) 是稳定的
void BubbleSort(int A[],int n)
{
int i,j;
bool flag;
for(i=0;i<n-1;i++)
{
flag=false;
for(j=n-1;j>i;j--)
{
if(A[j-1]>A[j]) swap(A[j-1],A[j]),flag=true;
}
if(flag==false) return ;
}
}
- 快速排序(考试重点):时间复杂度O(\(nlog_2n\))空间复杂度O(\(log_2n\)) 是不稳定的
int Partition(int A[],int low,int high)
{
int pivot=A[low];
while(low<high)
{
while(low<high && A[high]>=pivot) high--;
A[low]=A[high];
while(low<high && A[low]<=pivot) low++;
A[high]=A[low];
}
A[low]=pivot;
return low;
}
void QucikSort(int A[],int low,int high)
{
if(low<high)
{
int pivotpos=Partition(A,low,high);
QucikSort(A,low,pivotpos-1);
QucikSort(A,pivotpos+1,high);
}
}
选择排序
- 简单选择排序:时间复杂度O(\(n^2\)) 是不稳定的
void SelectSort(int A[],int n)
{
int i,j,minn;
for(i=0;i<n-1;i++)
{
minn=i;
for(j=i+1;j<n;j++)
{
if(A[j]<A[minn]) minn=j;
}
if(i!=minn) swap(A[minn],A[i]);
}
}
- 堆排序(考试重点):时间复杂度O(\(nlog_2n\)) 是不稳定的
// 堆排序
// 调整元素k为根的子树
void HeadAdjust(int A[],int k,int len)
{
A[0]=A[k];
for(int i=2*k;i<=len;i=i*2)
{
if(i<len && A[i]<A[i+1]) i++;
if(A[0]>A[i]) break;
else
{
A[k]=A[i];
k=i;
}
}
A[k]=A[0];
}
// 先建立一个大根堆
void BuildMaxHeap(int A[],int len)
{
for(int i=len/2;i>0;i--) HeadAdjust(A,i,len);
}
void HeapSort(int A[],int len)
{
BuildMaxHeap(A,len);
for(int i=len;i>1;i--)
{
swap(A[i],A[1]);
HeadAdjust(A,1,i-1);
}
}
归并排序
(考试重点)时间复杂度O(\(nlog_2n\)) 空间复杂度O(n)是稳定的
void Merge(int A[],int low,int mid,int high)
{
int i,j,k;
for(k=low;k<=high;k++) B[k]=A[k];
for(i=low,j=mid+1,k=i;i<=mid&& j<=high;k++)
{
if(B[i]<B[j]) A[k]=B[i++];
else A[k]=B[j++];
}
while(i<=mid) A[k++]=B[i++];
while(j<=high) A[k++]=B[j++];
}
void MergeSort(int A[],int low,int high)
{
if(low<high)
{
int mid=(low+high)/2;
MergeSort(A,low,mid);
MergeSort(A,mid+1,high);
Merge(A,low,mid,high);
}
}
基数排序
没有比较关键字,而是按照(个十百)位序大小排序,比如我们先拿个位从大到小排序,然后我们再按十从大到小排序,再按百位操作就可以得到从大到小的排序。(会手算就行)

