二分图匈牙利算法模板
不带权值的匈牙利算法(Hungarian algorithm) KM下次一定
一.前置
学习一种特殊的图:二分图
定义: 若能将无向图G=(V,E)的顶点V划分为两个交集为空的顶点集,并且任意边的两个端点都分属于两个集合,则称图G为一个为二分图
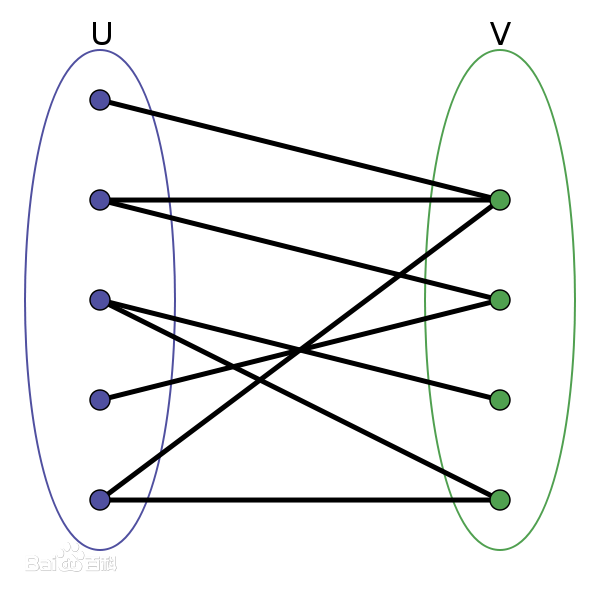
二分图的匹配指找到一个集合M,是边的集合,其中任意两条边都没有相同的顶点,也有是四个不同顶点,两两组合的两条边。
M集合的大小就是匹配个数(也就是匹配的边数)。
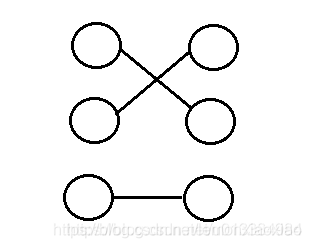
匹配的两个重点:
- 匹配是边的集合;
- 在该集合中,任意两条边不能有共同的顶点。
匈牙利算法就是求解二分图最大(最多)匹配的算法
二.重要核心
换句话来说,匈牙利算法又叫增广路算法
什么叫增广路呢 百度一下你就知道
从未匹配的一点出发,经过 未匹配,匹配,未匹配....的边 这样循环的路,最终达到一个未匹配的点的路径就叫增广路
明显:
1.最短的增广路就是从未匹配的一点经过一条未匹配的边到达另一个未匹配点的路径
2.增广路起点和终点都是未匹配的点
3.增广路上的点集个数肯定为偶数,边集肯定是奇数
4.任意一条增广路,必定未匹配的边数要大于匹配的边数 (匈牙利更新的关键)
三.算法核心内容
根据第二大点的第四条性质,我们就可以来增加匹配个数。
首先遍历左边的结点u,依次和右边的点连接,寻找增广路 :
情况1.找到未匹配边并且右边点也是未匹配点,形成最简单的增广路
情况2.找到未匹配边但右边点是匹配点,再递归顺着匹配边通过匹配点找下一个未匹配边,直到满足增广路的定义,找到增广路
由于未匹配的边数要大于匹配的边数,我们将找到的增广路的边集合状态全部翻转(未匹配的边变成匹配的,匹配的变成未匹配的)
这样匹配边就增加一个,更新最大值(有贪心的意思)
.-----.-----.-----.
翻转状态
.-----.-----.----.
(加粗表示匹配,未加粗表示未匹配)
四.代码模板
代码模板很短,但是写法很值得学习,很简练
#include <bits/stdc++.h>
#define ll long long
#define ri int
#define see(a,b) cout << a << ' ' << b << '\n'
using namespace std;
ll n,m,e;
ll vis[505]; //防止重复走
ll g[505][505];
ll lf[505]; //记录右边结点匹配的左边结点 left数组
ll u,v;
bool have(ll x)
{
for(ri i=1;i<=m;i++)
{
if(g[x][i] && !vis[i]) //如果有边并且没有访问过
{
vis[i]=1;
if(!lf[i] || have(lf[i])) //情况一或者情况二
{
lf[i]=x; //记录并且回溯的时候翻转状态
return true;
}
}
}
return false;
}
int main()
{
ios::sync_with_stdio(0);
cin.tie(0),cout.tie(0);
cin >> n >> m >> e;
for(ri i=1;i<=e;i++) //建图(建成有向图)
{
cin >> u >> v;
g[u][v]=1;
}
ll ans = 0;
for(ri i=1;i<=n;i++) //左边点开始遍历
{
for(ri i=1;i<=m;i++) vis[i]=0; //每次找一个点都需要清空标记
if(have(i)) ++ans; //如果有匹配的就增加一个匹配
}
cout << ans << '\n'; //最大匹配个数
return 0;
}
其中lf[](也就是left数组) 意思就是右边点所匹配的左边点,这样标记可以同时实现记录右边的点是否匹配,和在递归回溯的时候可以实现状态翻转
vis数组是为了防止找到的增广路形成一个循环,重复经过某一个已经经过的点
附:模板题:洛谷P3386
模板代码就是这题的答案

