
Spark算子
1.什么是SparkRDD算子:
总的来讲RDD是Spark最小的数据抽象,每一个rdd算子都拥有五个主要的属性:
1.RDD是一组已经分好区的数据集
2.RDD拥有计算分区数据的功能
3.依赖其他RDD
4.对于key-value格式的RDD,可以自定义分区
5.RDD更喜欢在数据本地计算数据(即移动计算而非移动数据)
2.RDD算子:
返回一个RDD与另一个RDD的并集,并且相同元素会多次出现

aggregate[U](zeroValue: U)(seqOp: (U, T) ⇒ U, combOp: (U, U) ⇒ U)(implicit arg0: ClassTag[U]): U
先对每一个分区进行局部计算再对计算后的结果进行总计算
def barrier(): RDDBarrier[T]
def cache(): RDD.this.type
def cartesian[U](other: RDD[U])(implicit arg0: ClassTag[U]): RDD[(T, U)]
返回两个RDD的笛卡尔积

def checkpoint(): Unit
设置检查点
def coalesce(numPartitions: Int, shuffle: Boolean = false, partitionCoalescer: Option[PartitionCoalescer] = Option.empty)(implicit ord: Ordering[T] = null): RDD[T]
返回一个减少分区数的RDD,如果设置的分区数大于RDD本身的分区,则分区数不变
def collect[U](f: PartialFunction[T, U])(implicit arg0: ClassTag[U]): RDD[U]
返回RDD中所有可用的值

def collect(): Array[T]
返回一个包含所有RDD的数组

def context: SparkContext
spark上下文

def count(): Long
返回RDD中的元素数量

def countApprox(timeout: Long, confidence: Double = 0.95): PartialResult[BoundedDouble]
类似于count算子,可能返回不完全的结果在延时之内,甚至正在执行的任务没有全部返程时
def countApproxDistinct(relativeSD: Double = 0.05): Long
返回一个已经去掉重复数据的countApprox
def countByValue()(implicit ord: Ordering[T] = null): Map[T, Long]
返回一个key-value格式的RDD用于记录每一个value出现的次数

defcountByValueApprox(timeout: Long, confidence: Double = 0.95)(implicit ord: Ordering[T] = null): PartialResult[Map[T, BoundedDouble]]
与上面类似
final def dependencies: Seq[Dependency[_]]
返回RDD的所有依赖

def distinct(): RDD[T]
返回一个一掉去掉重复数据的新RDD

def filter(f: (T) ⇒ Boolean): RDD[T]
返回一个数据过滤后新RDD
![]()
def first(): T
返回RDD中第一个值

def flatMap[U](f: (T) ⇒ TraversableOnce[U])(implicit arg0: ClassTag[U]): RDD[U]
对RDD中的所有数据进行处理,并且返回一个新的RDD

def fold(zeroValue: T)(op: (T, T) ⇒ T): T
def foreach(f: (T) ⇒ Unit): Unit
循环遍历RDD

def getCheckpointFile: Option[String]
如果这个RDD是检查点则返回数据目录的名字
def getStorageLevel: StorageLevel
获得当前RDD的存储等级

def glom(): RDD[Array[T]]
将每一个RDD分区中的数据放入数组中并且返回一个新的RDD

def groupBy[K](f: (T) ⇒ K, p: Partitioner)(implicit kt: ClassTag[K], ord: Ordering[K] = null): RDD[(K, Iterable[T])]
val id: Int
返回RDD的id

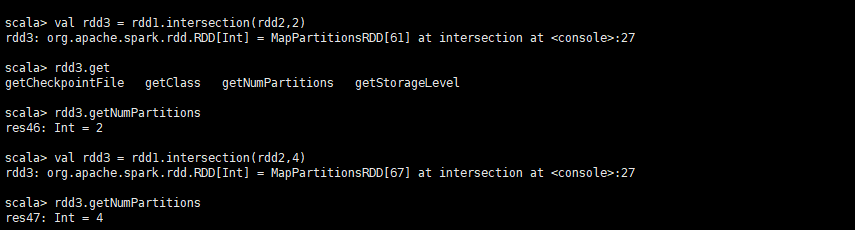
def intersection(other: RDD[T], numPartitions: Int): RDD[T]
返回两个RDD的交集
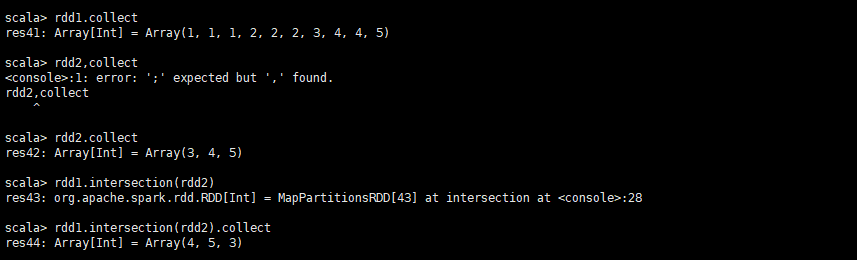
返回交集并且设置分区数
def isCheckpointed: Boolean
是否是检查点

def keyBy[K](f: (T) ⇒ K): RDD[(K, T)]
将RDD转化成key-value格式并且为每一个value设置一个key

deflocalCheckpoint(): RDD.this.type
def map[U](f: (T) ⇒ U)(implicit arg0: ClassTag[U]): RDD[U]
将一个函数作用于RDD中的每一个值,并且返回一个新的RDD
defmapPartitions[U](f: (Iterator[T]) ⇒ Iterator[U], preservesPartitioning: Boolean = false)(implicit arg0: ClassTag[U]): RDD[U]

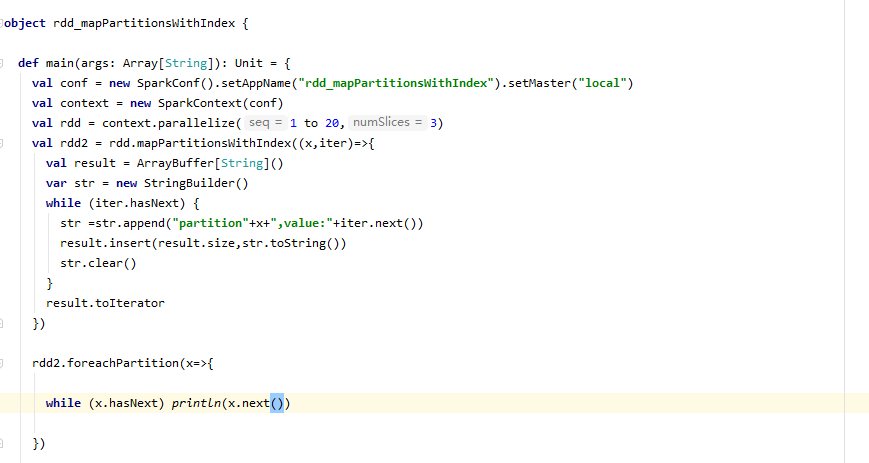
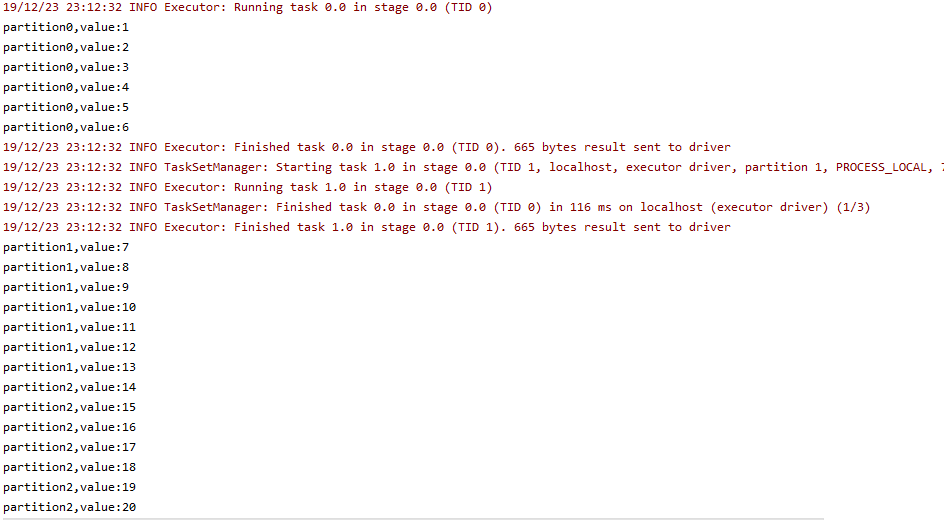
def mapPartitionsWithIndex[U](f: (Int, Iterator[T]) ⇒ Iterator[U], preservesPartitioning: Boolean = false)(implicit arg0: ClassTag[U]): RDD[U]
def max()(implicit ord: Ordering[T]): T
返回最大值
def min()(implicit ord: Ordering[T]): T
返回最小值

final defpartitions: Array[Partition]
返回分区数组

def persist(): RDD.this.type
设置缓存(等级为MEMORY_ONLY)
def persist(newLevel: StorageLevel): RDD.this.type
设置缓存并且设置缓存等级
defpipe(command: Seq[String], env: Map[String, String] = Map(), printPipeContext: ((String) ⇒ Unit) ⇒ Unit = null, printRDDElement: (T, (String) ⇒ Unit) ⇒ Unit = null,)
final defpreferredLocations(split: Partition): Seq[String]
