利用爬虫爬知乎少字回答
利用爬虫爬知乎少字回答
感谢马哥python说的指导
最近在学习有关的知识 如果怕对服务器影响 可以修改sleep 时间每次更长一点。
这样就不用看一些营销号的长篇大论 或者看别人写小说了。
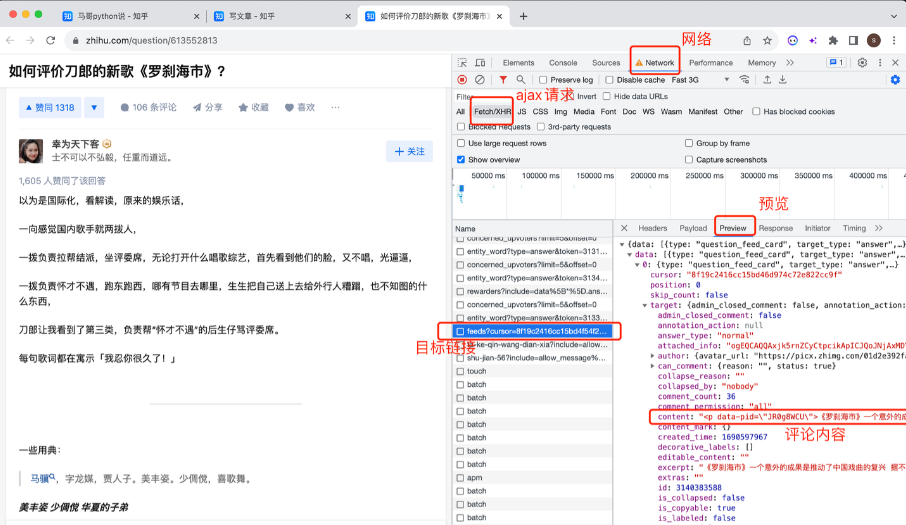

# 发送请求 有bug一次只有五个回答 但是我们可以拿到下一次回答。
# 最后一次回答的时候data等于[]如果data是[就退出循环]
r = requests.get(url, headers=headers)
# 接收返回数据 我已经成功请求到数据了
# 确保状态码为200,表示请求成功
if r.status_code == 200:
# 解析返回的JSON数据
j_data = r.json()
# 假设你想获取一个名为"data"的键对应的值的长度
# 注意,下面这行代码中的"data"应该是你想要操作的实际键的名称
answer_list = j_data["data"]
print(len(j_data["data"]))
title = answer_list[0]['target']['question']['title']
for answer in answer_list:
# 回答内容
try:
# 从HTML中想要提取有用的文字,你可以使用Python的第三方库来进行解析和处理HTML。
answer_content = answer['target']['content']
soup = BeautifulSoup(answer_content, 'html.parser')
# 使用.get_text()方法来提取纯文本内容
useful_text = soup.get_text()
# 时间
timestamp = answer['target']['updated_time']
# 使用datetime.fromtimestamp()方法将时间戳转换为datetime对象
dt_object = datetime.fromtimestamp(int(timestamp))
# 使用strftime()方法将datetime对象格式化为你想要的日期字符串
formatted_date = dt_object.strftime("%Y/%#m/%#d")
except:
useful_text = ''
formatted_date = ''
answer_content_list.append(useful_text)
answer_time_list.append(formatted_date)
Write2Csv(
{
'回答时间': answer_time_list,
'回答内容': answer_content_list,
},title)
print(j_data["paging"]["next"])
else:
print("请求失败了:", r.status_code)
v_question_id = 'session_id=1691645872201785699'
# 定义请求地址(含指定问题id):
# 请求地址
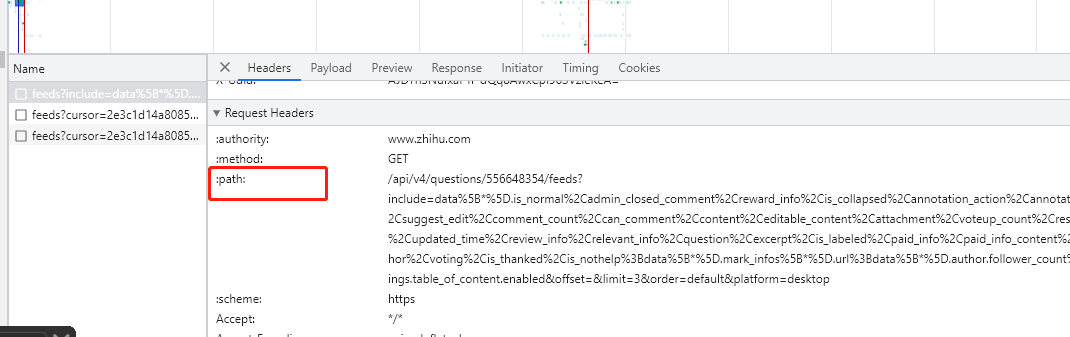
url = 'https://www.zhihu.com/api/v4/questions/556648354/feeds?include=data%5B*%5D.is_normal%2Cadmin_closed_comment%2Creward_info%2Cis_collapsed%2Cannotation_action%2Cannotation_detail%2Ccollapse_reason%2Cis_sticky%2Ccollapsed_by%2Csuggest_edit%2Ccomment_count%2Ccan_comment%2Ccontent%2Ceditable_content%2Cattachment%2Cvoteup_count%2Creshipment_settings%2Ccomment_permission%2Ccreated_time%2Cupdated_time%2Creview_info%2Crelevant_info%2Cquestion%2Cexcerpt%2Cis_labeled%2Cpaid_info%2Cpaid_info_content%2Creaction_instruction%2Crelationship.is_authorized%2Cis_author%2Cvoting%2Cis_thanked%2Cis_nothelp%3Bdata%5B*%5D.mark_infos%5B*%5D.url%3Bdata%5B*%5D.author.follower_count%2Cvip_info%2Cbadge%5B*%5D.topics%3Bdata%5B*%5D.settings.table_of_content.enabled&offset=&limit=3&order=default&platform=desktop'.format(v_question_id)
总共的代码
import requests
import time
import pandas as pd
import os
import re
import random
from datetime import datetime
from bs4 import BeautifulSoup
# 请求头 (如果数据量仍未满足且遇到反爬,请尝试增加cookie等其他请求头解决)
# 只需要这点数据量 这个请求头就够了
headers = {
'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36',
}
v_question_id = 'session_id=1691645872201785699'
# 定义请求地址(含指定问题id):
# 请求地址
url = 'https://www.zhihu.com/api/v4/questions/556648354/feeds?include=data%5B*%5D.is_normal%2Cadmin_closed_comment%2Creward_info%2Cis_collapsed%2Cannotation_action%2Cannotation_detail%2Ccollapse_reason%2Cis_sticky%2Ccollapsed_by%2Csuggest_edit%2Ccomment_count%2Ccan_comment%2Ccontent%2Ceditable_content%2Cattachment%2Cvoteup_count%2Creshipment_settings%2Ccomment_permission%2Ccreated_time%2Cupdated_time%2Creview_info%2Crelevant_info%2Cquestion%2Cexcerpt%2Cis_labeled%2Cpaid_info%2Cpaid_info_content%2Creaction_instruction%2Crelationship.is_authorized%2Cis_author%2Cvoting%2Cis_thanked%2Cis_nothelp%3Bdata%5B*%5D.mark_infos%5B*%5D.url%3Bdata%5B*%5D.author.follower_count%2Cvip_info%2Cbadge%5B*%5D.topics%3Bdata%5B*%5D.settings.table_of_content.enabled&offset=&limit=3&order=default&platform=desktop'.format(v_question_id)
# 定义一些空列表用于存放解析后数据: 一些对我没用我不写了
author_name_list = [] # 答主昵称
author_gender_list = [] # 答主性别
follower_count_list = [] # 答主粉丝数
author_url_list = [] # 答主主页
headline_list = [] # 答主签名
answer_id_list = [] # 回答id
answer_time_list = [] # 回答时间
answer_content_list = [] # 回答内容
comment_count_list = [] # 评论数
voteup_count_list = [] # 点赞数
thanks_count_list = [] # 喜欢数
def Write2Csv(List,title) :
import pandas as pd
dataframe = pd.DataFrame(List)
print('请选择输出的格式1是slsx 2是csv,输入1或者2:')
typeinput = input()
if typeinput == '1':
filepath = title+'.xlsx'
dataframe.to_excel(filepath)
elif typeinput == '2':
filepath = title +'.csv'
dataframe.to_csv( filepath , index=False , sep = '\n' , header = False , encoding='utf_8_sig')
title = ""
def whileurl(urls) :
global title
print("执行一次")
# 发送请求 有bug一次只有五个回答 但是我们可以拿到下一次回答。
# 最后一次回答的时候data等于[]如果data是[就退出循环]
r = requests.get(urls, headers=headers)
# 接收返回数据 我已经成功请求到数据了
# 确保状态码为200,表示请求成功
if r.status_code == 200:
# 解析返回的JSON数据
j_data = r.json()
if len(j_data) == 0 or j_data["paging"]["page"]==100:
Write2Csv({'回答时间': answer_time_list,'回答内容': answer_content_list,},title)
return # 退出递归调用
# 假设你想获取一个名为"data"的键对应的值的长度
# 注意,下面这行代码中的"data"应该是你想要操作的实际键的名称
answer_list = j_data["data"]
title = answer_list[0]['target']['question']['title']
for answer in answer_list:
# 回答内容
try:
# 从HTML中想要提取有用的文字,你可以使用Python的第三方库来进行解析和处理HTML。
answer_content = answer['target']['content']
soup = BeautifulSoup(answer_content, 'html.parser')
# 使用.get_text()方法来提取纯文本内容
useful_text = soup.get_text()
# 时间
timestamp = answer['target']['updated_time']
# 使用datetime.fromtimestamp()方法将时间戳转换为datetime对象
dt_object = datetime.fromtimestamp(int(timestamp))
# 使用strftime()方法将datetime对象格式化为你想要的日期字符串
formatted_date = dt_object.strftime("%Y/%#m/%#d")
except:
useful_text = ''
formatted_date = ''
if len(useful_text)<=200:
answer_content_list.append(useful_text)
answer_time_list.append(formatted_date)
urls = j_data["paging"]["next"]
time.sleep(5)
whileurl(urls)
else:
print("请求失败了:", r.status_code)
whileurl(url)

