爬B站评论区
爬B站评论区
最近在学习python。
本文由马哥python说 SmartCrane 奔涌的康 倾情付出 文章一些函数会用中文注释标出来 这个demo可以作为实战的解释 新手也可以看懂。
(莫要频繁爬 对服务器不好 这样我们就可以看到一些有用的评论了 主要为了娱乐 所以改成xlsx格式的 方便看)
1.cookie
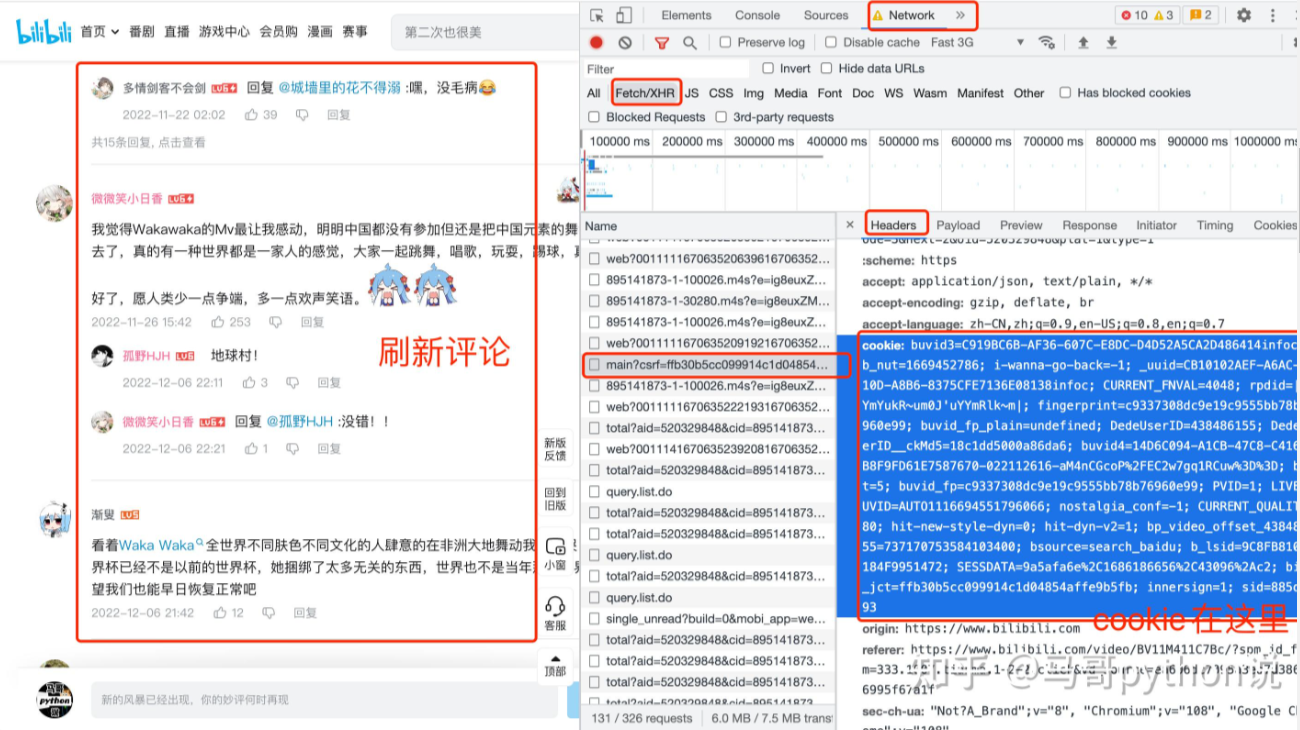
# 导入需要用到的库
import requests # 发送请求
import pandas as pd # 保存csv文件
import json
import time
from time import sleep # 设置等待,防止反爬
import re
# 请求头
headers = {
'authority': 'api.bilibili.com',
'accept': 'application/json, text/plain, */*',
'accept-language': 'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6',
# 需定期更换cookie,否则location爬不到
'cookie': "需定期更换cookie,否则location爬不到",
'origin': 'https://www.bilibili.com',
'referer': 'https://www.bilibili.com/video/BV1FG4y1Z7po/?spm_id_from=333.337.search-card.all.click&vd_source=69a50ad969074af9e79ad13b34b1a548',
'sec-ch-ua': '"Chromium";v="106", "Microsoft Edge";v="106", "Not;A=Brand";v="99"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"Windows"',
'sec-fetch-dest': 'empty',
'sec-fetch-mode': 'cors',
'sec-fetch-site': 'same-site',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/106.0.0.0 Safari/537.36 Edg/106.0.1370.47'
}
CommentList = [['IP属地' , '昵称' , 'ID' , '发表时间' , '评论内容' , '点赞数' , '回复内容']]
def fetchURL(url):
# response = requests.get(url = url , headers=headers)
#print('Have got the html\n')
# return response.text
return requests.get(url=url , headers=headers).text
# 格式化
def parseHtml(html):
s = json.loads(html)
# print(f"the type of html is {type(html)}\n") Str
#print(f"the type of s is {type(s['data']['replies'])}\n") # Dictionary
# the function 'json.loads' turned string into dictionary
'''
CommentList = []
hlist = []
hlist.append('IP属地')
hlist.append('昵称')
hlist.append('ID')
hlist.append('发表时间')
hlist.append('评论内容')
hlist.append('点赞数')
hlist.append('回复数')
CommentList.append(hlist)
'''
# 一页15条评论
for i in range(0 , 15) :
# 可能会出现bug那就是评论太少了 已经修复了
try:
comment = s['data']['replies'][i]
except IndexError:
print("没有更多的评论了")
break # 跳出循环
# KeyError: 'location'有的人没地区
# 如果你确定 'reply_control' 键存在,但是 'location'
# 键可能不一定存在,你可以尝试使用 .get() 方法来访问键,
# 这样如果键不存在时不会引发 KeyError:
reply_control = comment.get('reply_control', {})
location_value = reply_control.get('location', '')
if len(location_value) >= 1:
location = comment['reply_control']['location'][5:]
else:
# 我猜是国外的IP 或者关闭了定位
location = "未知地区"
#print(location[5:])
uname = comment['member']['uname']
ID = comment['member']['mid']
ctime = time.strftime("%Y-%m-%d %H:%M:%S",time.localtime(comment['ctime'])) # time of comment
content = comment['content']['message']
like = comment['like']
rcontent = ""
# 判断这个类型是不是NoneType
# 评论回复也加上去吧
if comment['replies'] is not None:
# rcount = comment['rcount']
for j in range(0 , len(comment['replies'])) :
rcomment = comment['replies'][j]
rcontent += rcomment['content']['message'] + '\n'
rcount = rcontent
alist = []
alist.append(location)
alist.append(uname)
alist.append(ID)
alist.append(ctime)
alist.append(content)
alist.append(like)
# 回复内容
alist.append(rcount)
CommentList.append(alist)
#print('Have got CommentList\n')
#return CommentList
def Write2Csv(List , title ) :
import pandas as pd
# DataFrame是一个二维的表格型数据结构,通常由行(rows)和列(columns)组成
dataframe = pd.DataFrame(List)
# print(title)
# filepath ='D:\Desktop\SpiderOfComment\CSVComment\\' + title + '.csv'
# filepath = title +'.csv'
# print(filepath)
# index=False:指定不将索引列写入CSV文件中。如果需要保留索引列,可以将此参数设置为True。
# sep:指定CSV文件中分隔符的字符。默认分隔符是逗号(,),但你可以根据需要修改为其他字符。
# header=False:指定不将列名写入CSV文件中。如果需要保留列名,可以将此参数设置为True。
#dataframe.to_csv( filepath , index=False , sep = ',' , header = False , encoding='utf_8_sig')
#print('Have written to the csv\n')
# 可以选中用那种形式输出
print('请选择输出的格式1是slsx 2是csv,输入1或者2:')
typeinput = input()
if typeinput == '1':
filepath = title[0] +'.xlsx'
dataframe.to_excel(filepath)
elif typeinput == '2':
filepath = title +'.csv'
dataframe.to_csv( filepath , index=False , sep = '\n' , header = False , encoding='utf_8_sig')
else:
print("你故意找事?")
# 发送url请求 并且获得标题
def GetTitle(url):
# 拿到了整个返回的html代码了
page_text = requests.get(url=url , headers=headers).text
#print(page_text)
# 这是一个正则表达式,用于匹配HTML中的<h1>标签
ex = '<h1 title="(.*?)".*?</h1>'
# re.S是一个特殊的标志,用于指定Python正则表达式在匹配时将整个字符串作为目标,包括换行符。
title = re.findall(ex , page_text , re.S)[0]
if title:
print(title)
else:
print("No match found.")
return title
# 获取视频的oid
def GetOid(url):
page_text = requests.get(url=url , headers=headers).text
# print(page_text)
# 这段代码的目的是从网页中获取一个 JSON 对象,并将其赋值给 window.__INITIAL_STATE__ 变量。
# 这个 JSON 对象应该包含 "aid" 和 "bvid" 两个属性,它们的值会被提取出来。
ex = '</script><script>window.__INITIAL_STATE__={"aid":(.*?),"bvid":'
# </script><script>window.__INITIAL_STATE__={"aid":269261816,"bvid"
oid = re.findall(ex , page_text , re.S)[0]
return oid
# 主函数
if __name__ == '__main__' :
print('请输入视频的网址:')
temp_url = input()
title = GetTitle(temp_url)
# print(title)
oid = GetOid(temp_url)
# pn(页数),type(=1)和oid(视频id)
# oid必须获得 不然无法访问的
url0 = 'https://api.bilibili.com/x/v2/reply?type=1&oid=' + oid + '&sort=2&pn='
# print(url)
print('Wait……')
# 在主函数中,通过写一个 for 循环,通过改变 pn 的值,获取每一页的评论数据。
# 这里只爬20页
#获取全部页数
for i in range(1, 20):
url = url0 + str(i)
# 再次获取整个html
html = fetchURL(url)
# parseHtml函数是用来解析HTML的。它将HTML字符串作为输入,并返回一个DOM对象,这个对象可以用来渲染HTML内容。
parseHtml(html)
# Python的方法可以接受任意数量的参数,包括零个或一个参数。
# Write2Csv(CommentList)
#如果 i 能被5整除,那么程序会暂停1秒钟。
if(i%5==0):
time.sleep(1)
Write2Csv(CommentList , title)
print('Success!\n')
