
摘要:人工智能一个主要开放问题是增量学习系统的开发,随着时间的推移,从数据流中学习越来越多的概念。这里引入一种新的策略iCaRL,以类增量的方式进行学习:开始只有少量的类,逐步添加新的类。iCaRL同时学习强分类器和数据表示。过去的工作受限于固定数据的表示,因此与深度学习架构不兼容。
一、介绍
视觉系统本质是递增的:新的视觉信息不断合并,现有的知识被保留下来。例如一个参观动物园的孩子了解新的动物但不会忘记家里的宠物。相比之下,大多人工识别系统智能在批量设置中训练,所有类已知,所有类的训练数据在同一时间读取,随机顺序访问。
随着视觉领域向人工智能发展,需要更灵活的策略处理真实世界的分类的大规模和动态性。至少有可用新类训练数据时,分类系统可用增量的学习到新类,将这种场景称为类增量学习。类增量算法有如下三个性质:1、可以训练不同时间出现不同类的数据流;2、为观察到的类提供一个有竞争力的多类分类器;3、对计算和内存的需求是有限的,或增长的非常慢。前两个是类增量学习的本质,第三个删除了一些算法,比如存储所有的训练样本,有新数据就重新训练。
目前还没有令人满意的类增量学习算法,现有技术违反了1和2,只能处理固定数量的类或需要同时提供所有培训数据。人们尝试从类增量的数据流中训练分类器,例如通过随机梯度下降优化。但这会导致分类的准确率迅速恶化,这种效应被称为灾难性遗忘或灾难性干扰。
现有技术局限于固定数据,不同同时学习分类器和特征表示的深度框架中,在分类准确率方面缺乏竞争力。在这里介绍ICARL,在类增量的设定中同时学习分类器和特征表示。为了满足上述标准,引入三个组件:1、根据最接近样本均值的规则进行分类;2、群体中优先范例选择;3、使用知识蒸馏和原型演练进行特征学习。
第2部分详述步骤,第3部分将方法放入先前的工作环境中,第4部分在CIFAR和ImageNet数据集上实验,第5部分讨论仍存在的限制和未来工作。
二、方法
2.1 类增量分类器学习
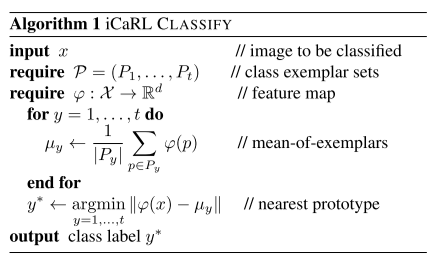
最近均值样本分类器:这里将X投到R空间,计算R空间每类的样本的均值,计算输入与每个均值点距离。u为特征向量。

样本容量固定为K,m为每类的样本数,训练中删掉一些已学习样本集中的代表样本,创建新类的代表样本集。
iCaRL利用CNN,将网络解释为一种可训练的特征提取器,Φ:X→Rd,所有特征向量被归一化。网络参数用Θ表示,包括固定数量的特征提取参数和数量可变的权重参数,wt表示后者,t表示目前为止观察到的类。注意这里的网络用于学习表示而不是实际分类。
![]()
内存需求为特征提取的参数大小、K个样例图片存储和与观察到的类一样多的权重向量。如果已知类数量的上限,就可以根据需要为权重向量分配空间,剩下内存存储范例。由于每类至少需要一个图像范例和权向量,最终只能学习有限数量的类。
2.2 最近平均样本分类器

μ为样本特征表示均值,选择最近均值为分类结果,相比于softmax需要有一个权值向量与φ做点积,后者的w和φ是解耦的,φ一旦变化w必须跟着改变,但前者不需要改变。最近平均样本分类方法只需要选出一些灵活数量的样本做平均。
2.3 特征表示学习
对于新加入的样本,网络参数需要更新,每次得到新的特征表示。这里的表示学习步骤类似于传统网络微调,但增加了两处修改使网络有抗遗忘性。1、训练集扩充,不仅包含新的样本集且存储了过去的样例;2、损失函数扩充,包含了新类的分类损失和旧类的蒸馏损失,使前面学到的知识保留下来。

2.4 样例管理
存储样例空间有限设为K个,当观察到t个类,每类只能存储m=K/t个样本。加入的每一类更新后需要挑选样例,旧类更新后需要减少样例。挑选原则是保存离类均值向量最近的样本,越接近的样本越早加入样例集,删除原则从末尾删除,直接删除后面的多余样例。



 浙公网安备 33010602011771号
浙公网安备 33010602011771号