
摘要:
特征的寻找已取得巨大成功,从手工设计到机器自己学习。但是优化算法仍依靠人工设计,这篇文章试图将优化算法的设计转换成一个学习问题。借用LSTM实现学习算法,在训练任务上优于通用人工设计方法,且可推广到相似结构的新任务。这种方法适用于多种问题,例如简易凸优化、训练神经网络、 用神经学设计图像等。
1、介绍
机器学习的任务可以看作在某些领域内目标函数的优化问题,虽然任何最小化这个目标函数的方法都可以用,但是对可微函数来说,标准方法是梯度下降的一些形式。
vanilla(批梯度下降法)只利用梯度而忽略了二阶信息,影响了其性能。经典的优化技术通过曲率信息对梯度步长重新调节来纠正这种行为。典型的是,通过二阶偏导数的Hessian矩阵,或者通过广义Gauss-Newton矩阵和Fisher信息。
许多现代优化工作是针对特定的问题类别设计更新规则,在不同的社区中,感兴趣的问题类别是不同的。例如,在深度社区中,可以看到针对高维、非凸优化问题的优化方法激增,包括momentum, Rprop, Adagrad, Adadelta, RMSprop, ADAM. 如果对优化问题的结构有更多的认识,可以使用更有针对性的方法[2015]。相反,强调稀疏化的社区倾向于使用不同的方法,尤其是组合优化问题,默认使用松弛。
优化器设计领域允许不同的社区根据其感兴趣问题的结构创建优化方法,但在该范围之外的问题性能会很糟糕。此外,优化的No free lunch定理表明,在组合优化的设定中,没有算法比随机策略更好。这表明对问题的子类进行特殊化是提高性能的唯一方法。
在本工作中我们提出学习更新规则代替人工设计,这里称为优化器g,以下面的形式更新优化对象f。
![]()
图1从一个更高的层次看这个过程。我们将使用一个循环神经网络RNN对更新规则进行建模,使RNN在维持其状态的同时,根据其迭代自动更新。
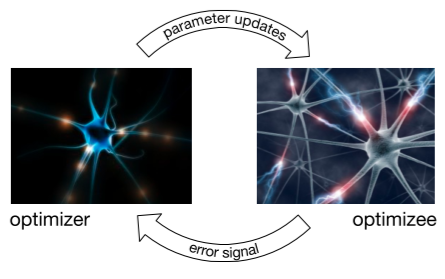
1.1 迁移学习和泛化
这项研究的目标是开发一个程序以建立学习算法,可以在一类特定的优化问题上表现良好。将算法设计转化为一个学习问题,可以通过以问题实例具体化感兴趣的问题类别。这与通常用解析方法描述感兴趣问题的性质,再手工设计学习算法截然相反。
在这个框架中,考虑泛化的意义是有趣的。在一般的统计学习中,我们有一个特定的兴趣函数,它的表现通过一个数据集的样本函数评价来约束。在选择模型时,我们指定一组兴趣函数没有观察到的点得到归纳偏差,泛化对应于目标函数在新点上的预测能力。在我们的设置中,样例是问题实例本身,这意味着泛化相当于不同问题间知识迁移的能力。这种问题结构的重用通常被称为迁移学习,并且被视为一个独立的主题。然而,从元学习的角度来看,我们可以把迁移问题理解成泛化问题,在机器学习领域得到更好的研究。
深度学习最成功的故事之一是,我们看看而已依靠深度网络的能力,通过学习子结构泛化到新的样例。在这里,我们的目标是利用这种泛化能力,但也将其从简单的监督学习提升到更一般的优化设置。
1.2 相关工作和简要历史
学习如何学习或元学习来获取知识或偏移归纳的方法由来已久[1998]。最近,Lake[2016]有力的论证了它作为人工智能中一个模块的重要性。一般来说,这些想法涉及到两个不同的时间尺度:在任务中快速学习或者在很多不同的任务中更渐进的全局学习。在一些最早的元学习中,Naik[1992]使用以前训练运行的结果来修改反向传播的下降方向,但这种更新策略在某种程度上是临时的,而且不是直接学到的。Santoro[2016]等人的工作采用了和我们类似的方法,将多任务学习转化为泛化,但他们训练了一个base learner,而不是更高级别的训练算法。
更密切相关的工作是Cotter[1990]以及后来的Younger[1999]等人的工作,他们指出由于hidden state,固定权重的RNN不需要修改其网络权重就能表现出动态行为。在Younger的工作中,一个更高级别的网络执行梯度下降程序,两个级别网络都在学习中进行训练。早期的工作Runarsson[2000]使用进化策略训练类似前馈网络的元学习规则。Schmidhuber[1992]认为,在元学习中,修改自己的行为的网络可以替代循环网络。但是,这些早期的工作关注于在线环境中的适应性,而不是将学到的训练过程迁移到一个新的问题实例中。类似的工作还有Feldkamp[1998]和Sutton[1992]。最后,Daniel[2016]等人使用增强学习训练一个控制器来选择步长,但这项工作的限制比我们的工作多,且仍然需要手工微调特征。
2、用RNN学习如何学习
在这项工作中,我们直接参数化优化器。优化的参数写为Θ*(Φ,f),其中优化器的参数Φ,问题中的函数为f。问题是如何判定一个好的优化器?给出函数 f 的分布,可将期望误差写为
![]()
正如前面所提,我们呢将更新值 gt 作为RNN网络m的输出,m由Φ参数化,Φ的状态由ht显性表示。虽然上式中的目标函数仅依赖于最终的参数值,但是为了训练优化器,对于一些horizon T,需要一个依赖于整个优化轨迹的目标:
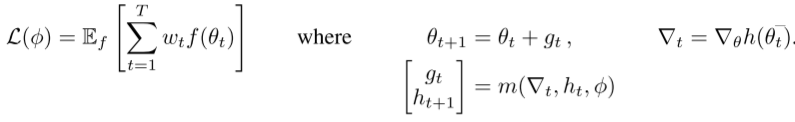
权重wt 取正值,与每个时间步有关,当全部等于1时与上上式相同,但不同的权值是有价值的。
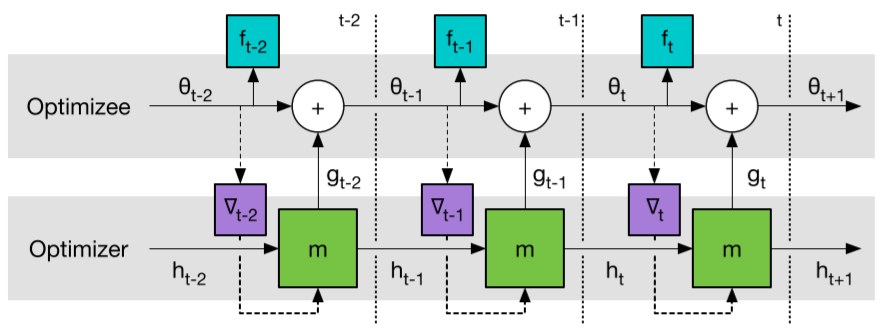
通过对Φ进行梯度下降,可以最小化L(Φ)。这个梯度估计可以通过采样随机函数f 和在图2中应用反向传播计算得到。我们允许梯度沿着图形的实线流动,但是沿着虚线的梯度被删除了。忽略沿着许仙的梯度相当于假设优化的梯度不取决于优化器的参数,例如∂∇t/∂φ = 0。这个假设可以避免计算 f 的二阶导数。
考察上式的目标,可以看出只有对wt≠0的项梯度非0。如果使用wt=1(t=T)来匹配原始问题,那么轨迹前面的梯度为0且只有最后的优化步为训练优化器提供了信息。这使得通过时间的反向传播Backpropagation Through Time (BPTT) 效率低下。我们通过放宽目标使轨迹上的中间点上wt>0来解决这一问题。这里改变了目标函数,但允许了在部分轨迹上训练优化器。为了简单起见,在所有的实验中,对所有t使用wt=1。
2.1 Coordinatewise LSTM优化器
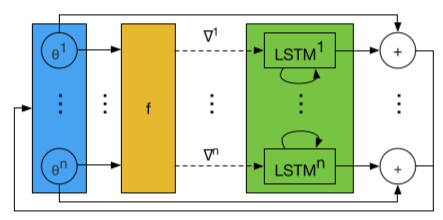
在我们的设置中应用RNN的一个挑战是,我们希望优化至少数万个参数。在这种规模下,使用全连通的RNN不可行,他需要巨大的隐藏状态和大量的参数。为了避免这个困难,我们使用一个优化器m,对目标函数的的参数进行coordinatewise,类似于常见的更新规则如RMSprop和ADAM等。这种协调的网络结构允许我们使用一个非常小的网络来定义优化器,并在不同optimizee的参数中共享优化器参数。
每个coordinate的不同体现在对每个目标函数参数使用单独的激活函数。除了为这个优化器使用一个小网络外,这种设置还有一个很好的效果,在每个coordinate上独立使用相同的更新规则,使优化器不受网络中参数顺序的影响。
我们使用两层的LSTM来实现每个coordinate的更新。网络将单个cooridate的优化梯度和前一个隐藏状态作为输入,相关优化参数的更新作为输出。这个架构称为LSTM优化器。所有LSTM共享参数,但隐含状态独立。
循环的使用允许LSTM学习动态更新规则,这些规则集成了梯度的历史信息,类似于momentum。众所周知,这在凸优化中有很多令人满意的特性,事实上最近许多学习过程,例如ADAM,都在更新中使用了动量。
预处理和后处理:优化器的输入输出可以有不同的尺寸,取决于被优化函数的类别。但是神经网络通常对不过大且过小的输入输出有效。在实践中,使用合适的常量(对所有时间步和函数f共享)重新调节LSTM优化器的输入输出,可以避免这一问题。在附录A中,为优化器的输入提出了一种不同的预处理方法,使鲁棒性和表现性能更好。
2.2 coordinates之间信息共享
在前一节中,作者考虑了一种coordinatewise结构,通过类比与RMSprop或ADAM的学习机制相对应。虽然对角方法在实践中是非常有效的,但我们同样可以考虑学习更多更复杂的优化器,将coordinates之间的相关性考虑在内。为此,我们引入一种允许不同的LSTM彼此通信的机制。
全局平均cells:最简单的解决方案是在每个LSTM层中制定一个cell子集进行通信,这些cell像普通LSTM cell一样工作,但是他们的输出激活值在每个时间步对全部coordinate进行平均。假设每个LSTM可以计算梯度的平方,这些全局平均cell(GAC)足以让网络实现L2梯度裁剪[Bengio 2013]。该架构可以记为LSTM+GAC优化器。
NTM-BFGS优化器:作者还考虑使用coordinate间共享外部存储扩展LSTM+GAC架构。如果适当设计内存,可以让优化器去学习类似于牛顿的方法,如(L-)BFGS。这样的方法可以被看成是一组独立工作进程,但是通过存储在内存中的逆Hessian近似进行了通信。作者设计了一个存储架构,允许网络模拟(L-)BFGS,这个架构对外部存储的使用类似神经图灵机[Graves 2014],称为NTM-BFGS优化器,详细描述见附录B。这种结构和NTM的区别在于:1、这种方法的内存仅允许低rank更新;2、控制器在coordinatewise运行。
3、实验
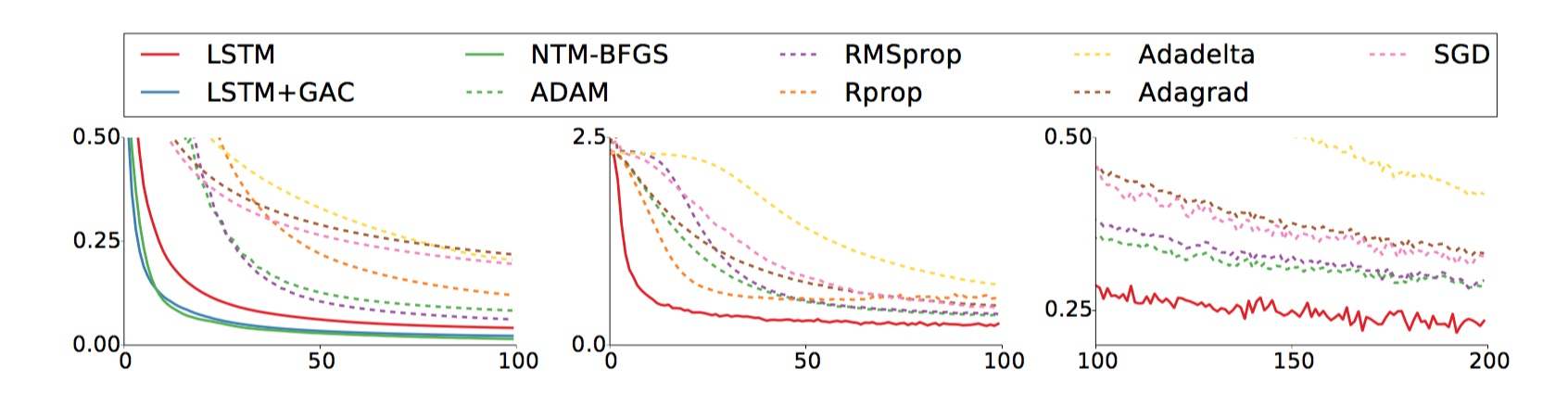
算法效果如下,其中实线为文中方法,左图是不同优化器对随机采样的10维二次函数的性能,中间是MINIST上的测试结果,右图是中图的后续100-200步:
论文解读:
方法主体是一个神经网络优化器和一个被优化的神经网络。这里把数据输入到被优化的神经网络中,然后输出误差,把误差信号传给神经网络优化器,这个优化器自己计算并输出参数的更新值,然后更新被优化的神经网络。
以前使用某种形式的梯度下降法更新参数,模型参数的梯度可以通过反向传播计算得到,但这里没有考虑二阶梯度的影响,针对这个问题研究者们设计了各种各样的优化方法。经典的优化技术通过加入曲率信息改变步长来纠正,如Hessian矩阵的二阶偏导数。DL社区的壮大衍生出很多求解高维非凸的优化求解器,如momentum,Rprop,Adagrad,RMSprop,ADAM。No free lunch表明,没有一个算法绝对好过随即策略,对于一个子问题,特殊化其优化算法是提升性能的唯一方法,也就是针对一个特定的优化问题,也许一个特定的优化器能够更好的优化它,我们是否可以不人工设计,而是让优化器本身根据模型与数据自适应的调节。
![]()
这里作者神经网络化了这个优化方法,即把公式的后半部分用神经网络替代:
![]()
这里g是神经网络,Φ是网络内部参数,输入是参数的梯度值或者说是误差值,输出要更新的数值大小。这里网络选用RNN模型,关键问题是如何训练这个网络?如何评价它的好坏?
作者给出了一个损失函数的定义,最优化的参数下函数的期望值,
![]()
传统优化器进行梯度下降所站视角是在某个周期内,而作者用了更全局的视角,例如下棋每走一步前,能看到未来很多步对这一步的影响,那么就能做出当前的最佳策略。LSTM的优化过程,就是把历史全局的步放在一起进行优化,具备瞻前顾后的能力。
- Meta-optimizer优化:目标函数“所有周期的loss都要很小!”,而且这个目标函数是独立同分布采样的(比如,这里意味着任意初始化一个优化问题模型的参数,我们都希望这个优化器能够找到一个优化问题的稳定解)
- 传统优化器:"对于当前的目标函数,只要这一步的loss比上一步的loss值要小就行”
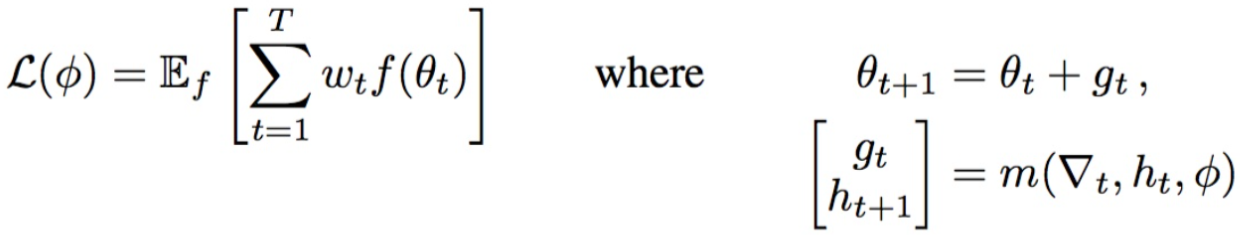
当wt=1(t=T)时,与最初目标等价,在实验中所有wt=1,对每个时间片平等对待,从历史的全局适应这个优化过程,g的参数对每个时刻结点都保持“聪明”。说明:在LSTM优化时的参数,是在所有Unroll_TRAIN_STEPS=[0,T]中保持不变的,在进行完所有Unroll_TRAIN_STEPS以后,再整体优化LSTM的参数。这也就是论文里面提到的coordinate-wise,即“对每个时刻点都保持‘全局聪明’”,即学习到LSTM的参数是全局最优的了。因为我们是站在所有TRAIN_STEPS=[0,T]的视角下进行的优化!
对上述损失函数使用梯度下降更新Φ:1、采样随机函数f,2、使用反向传播计算损失函数的梯度,3、使用梯度下降更新参数。
每个时间片内,优化器输入状态h,从被优化的网络中得到梯度,输入神经网络优化器m输出要更新的参数值g,更新被优化的参数θ,并输出参数结果f。
由于RNN的输入是每一个被优化网络参数的梯度,数量太多导致优化器的网络庞大不可行,需要一个小网络且可输入巨量的参数信息。这里让不同参数公用一个网络,由于网络训练的是参数梯度的变化情况,和参数的具体位置没关系,因此只需要使用一个共同的LSTM网络。即Coordinatewise LSTM优化器。所有LSTM公用参数,知识输入的隐含层状态h不同。
参考文献:
⭕ 知乎博客解读

 浙公网安备 33010602011771号
浙公网安备 33010602011771号