
Cassandra维护数据一致性的策略
1、逆熵
Cassandra数据库在分布式的架构上借鉴了Amazon的Dynamo,而在数据的存储模型上参考了Google的Bigtable,因而在数据一致性方面与Dynamo和Bigtable有着很深的联系,逆熵机制就是这种联系的一种体现。
逆熵与gossip协议一样也是基于传染病理论的算法,它主要用来保证不同节点上的数据能够更新到最新的版本。要了解逆熵必须先来了解一下Merkle Tree,在Cassandra中每个数据项可以表示为 (key, value) 对,key 均匀的分布在一个 2^n 的 key 空间中(比如 key 可以取 value 的 SHA1 hash 值)。两个节点在进行数据同步时分别对数据集生成一个 Merkle Tree。Merkey Tree 是一棵二叉数。Merkel Tree 的最底层可以是 16 个 key 的异或值 (xor)。每个父节点是两个子节点的 xor 值。这样,在比较的时候,两个节点首先传最顶层的 tree node, 如果相等,那么就不用继续比较了。否则,分别比较左右子树。 Cassandra正是基于上述所说的比较机制来确定两个节点之间数据是否一致的,如果不一致节点将通过数据记录中的时间戳来进行更行。
Cassandra中的Merkle树与Amazon的Dynamo中的Merkle树有一些不同,在Cassandra中我们要求每个列族都有自己的Merkle树,并且在主压紧操作过程中,Merkle树将作为一个快照被创建,而其生命周期仅限于它被需要发送给换上邻居节点的时候,从而降低了磁盘的I/O操作。在每一次更新中逆熵算法都会被引入,这会对数据库进行校验和,并且与其他节点比较校验和。如果校验和不同,就会进行数据的交换,这需要一个时间窗口来保证其他节点可以有机会得到最近的更新,这样系统就不会中时进行没有必要的逆熵操作了。
逆熵在很大程度上解决了Cassandra数据库的数据一致性的问题,但是这种策略也存在着一些问题。在数据量差异很小的情况下, Merkle Tree 可以减少网络传输开销。但是两个参与节点都需要遍历所有数据项以计算 Merkle Tree, 计算开销 (或 IO 开销,如果需要从磁盘读数据项)是很大的,可能会影响服务器的对外服务,这也是一些大公司放弃Cassandra的主要原因。
2、读修复
有两种类型的读请求,一个协调器(读代理)可以将这两种读请求发送到一个副本:直接读请求和读修理请求。读请求所要读取的副本的数量将会有用户在调用读请求自己进行设定,例如:设定为ONE时,将会只对一个副本进行读取,设定为QUORUM,则会在读取超过半数的一致性的副本后返回一份副本给客户端。读修复机制在读请求结果发送回用户之后将对所有的副本就行检测和修复,确保所有的副本保持一致。
用户在向Cassandra请求数据时已经指定了一致性的级别,读请求的协调器就根据用户的一致性界别对Cassandra数据库中的符合一致性界别的节点进行读取,并将读取出来的结果进行比较,检查他们是不是一致的,如果是一致的,那么毫无意外返回相应的值即可,如果不是一致的,则基于时间戳从这些数据中提取出最新的数据返回给用户。结果已经返回给用户了,然而为了确保数据在数据库中的一致性,Cassandra将会在后台自己进行所有相关数据的副本一致性的检测,并且对那些不满足一致性的数据进行一致性同步,这就是读修复机制的修复过程。
例如:在一个集群中,副本因子为3(同一种数据存三份),在读取时一致性级别指定为2,也就是说对已一种数据将会读取3个备份中的两个。在这种情况下,如图1所示,Cassandra将会为我们读取两个副本,并且在两个副本中决定出最新的那个副本数据,然后返回给用户,之后读修复策略将会对第三份未进行读取的副本进行修复,以确定这三个副本的数据是一致的。
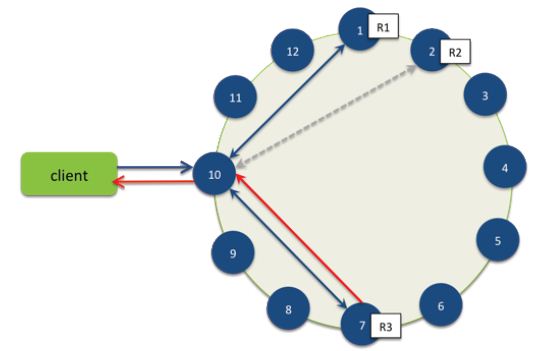
图1 Cassandra读修复机制(虚线为读修复过程)
3、提示移交
当一个写请求到达Cassandra时,如果此时负责这部分的Cassandra节点由于种种原因不能够达到用户指定的副本因子的要求,这个时候写入将会成为麻烦的事情,写入将会因为节点的缺失而失败。为了解决这样的问题,Cassandra和其他一些分布式的场景一样提出了提示移交机制。该机制是指当写入因为相应节点不能够满足副本因子时,将会把数据写到其他的节点上去,之后向用户返回写入成功,当相关的节点又恢复服务之后,Cassandra将写入其他节点的那部分数据在从新写入到该节点。
提示移交允许Cassandra对于写操作永远可用,降低了在写节点恢复服务之后的不一致的时间,当用户的一致性级别定为ANY时,也就是意味着即便是有一个提示被记录下来,写操作也就可以认为是成功了。例如:Key A按照规则首要写入节点为N1,然后复制到N2。假如N1宕机,如果写入N2能满足一致性级别要求,则Key A对应的Row Mutation将封装一个带hint信息的头部(包含了目标为N1的信息),然后随机写入一个节点N3,此副本不可读。同时正常复制一份数据到N2,此副本可以提供读。如果写N2不满足写一致性要求,则写会失败。 等到N1恢复后,原本应该写入N1的带hint头的信息将重新写回N1。
提示移交机制在很多分布式的场景下被用来保持数据写时的一致性,被认为是一个保持数据库持久性的深思熟虑的设计,并且这种机制还在很多的分布式的计算模式中出现,例如Java消息服务(JMS)。在具有持久性的“保障传递”JMS队列中,如果消息无法发送该接受者,JMS将会等待一个给定的时间,然后重新传递,直到成功接收为止。然而在实际的系统中,不论是对于JMS的可靠传输还是对于Cassandra的提示移交,都存在一个问题:如果节点离线持续了一段时间,已经有很多的提示信息存在了其他的节点上了,那么在节点重新上线之后,请求将会集中的发送到这个节点,对于这个刚刚恢复服务、非常脆弱的节点来说是无法承受的。
4、分布式删除
很多在单机中非常简单的操作,一旦放在集中分布式的环境当中就没有那么简单了,就像删除一样,单机删除非常简单,只需要把数据直接从磁盘上去掉即可,而对于分布式,则大大不同了。分布式删除的难点在于:如果某对象的一个备份节点 A 当前不在线,而其他备份节点删除了该对象,那么等 A 再次上线时,它并不知道该数据已被删除,所以会尝试恢复其他备份节点上的这个对象,这使得删除操作无效。
分布式删除机制正是为了解决以上的所提到的分布式删除的所遇到的问题。删除一个 column 其实只是插入一个关于这个 column 的墓碑(tombstone),并不直接删除原有的 column。该墓碑被作为对该列族的一次修改,记录在 Memtable 和 SSTable 中。墓碑的内容是删除请求被执行的时间,该时间是接受客户端请求的存储节点在执行该请求时的本地时间(local delete time),称为本地删除时间。需要注意区分本地删除时间和时间戳,每个列族修改记录都有一个时间戳,这个时间戳可以理解为该 column 的修改时间,是由客户端给定的,而本地删除时间只有在采用分布式删除机制时才会有。
由于被删除的 column 并不会立即被从磁盘中删除,所以系统占用的磁盘空间会越来越大,这就需要有一种垃圾回收的机制,定期删除被标记了墓碑的 column,而在Cassandra当中垃圾回收是在压紧的过程中完成。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号