
朴素贝叶斯的分类
-
在sk_learn中提供了三种不同类型的贝叶斯模型算法
-
高斯模型
-
多项式模型
-
伯努利模型
-
高斯模型
-
介绍:
-
高斯分布,也就是正态分布,当频率直方图的区间变得特别小的时候拟合的曲线,想一座小山峰,两边特别小,中间高
-
正太分布,就是正常形态的分布,它是自然界的一种规律
-
现实生活中有很多现象均服从高斯分布,比如收入,身高,体重等,大部分都处于中等水平,特别少和特别多的比例都会比较低
-
-
-
为什么在现实生活中正太分布会如此常见
-
通常情况下一个事物的影响因素往往有多个,比如身高的影响有:
-
家庭的饮食习惯
-
家庭长辈的身高
-
运动情况
-
···
-
-
其中每一个因素,都会对身高产生一定的影响,要么是正向的影响,要么是反向的影响,所有因素最终让整体身高接近正态分布
-
在数学中正太分布往往被称为高斯分布
-
-
-
exp函数为高等数学里以自然常熟e为低的指数函数
-
-
通过假设P(xi|Y)是服从高斯分布(也就是正态分布),来估计每个特征分到每个类别上的Y上的条件概率。来估计每个特征下每个类别上的条件概率,对于每个特征下的对应每个分类结果概率的取值,高斯朴素贝叶斯有如下公式:
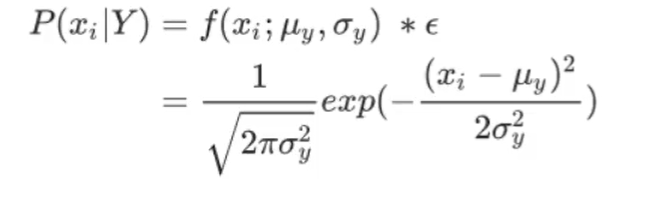
高斯分布模型的作用

-
API
from sklearn.naive_bayes import GaussianNB
from sklearn.naive_bayes import GaussianNB
import numpy as np
from sklearn.datasets import load_digits
from sklearn.model_selection import train_test_split
data = load_digits()
feature = data.data
target = data.target
x_train, x_test, y_train, y_test = train_test_split(feature, target, test_size=0.2, random_state=2020)
nb = GaussianNB()
nb = nb.fit(x_train, y_train)
sco = nb.score(x_test, y_test)
print(sco)
# 预测
an1 = nb.predict(x_test[5].reshape(1, -1))
print(an1)
print(y_test[5])
# 预测成功
# 返回分到每个类别的概率
ret = nb.predict_log_proba(x_test[9].reshape(1, -1))
print(ret)
0.825
[7]
7
[[-1.67710920e+03 -1.90132293e+00 -1.48844027e+02 -1.15381154e+02
-2.91633664e+08 -3.03655520e+02 -5.25168350e+03 -3.38304019e+08
-1.61779063e-01 -1.26100500e+02]]
Process finished with exit code 0

 浙公网安备 33010602011771号
浙公网安备 33010602011771号