MySQL的加锁规则
这次的内容是学习极客时间的MySQL实战45讲课程中的实验和总结,具体课程是第21篇文章。
首先是课程中的总结的加锁规则,两个“原则”、两个“优化”和一个“bug”(可重复读的事务隔离级别下)。
原则 1:加锁的基本单位是 next-key lock。希望你还记得,next-key lock 是前开后闭区间。 原则 2:查找过程中访问到的对象才会加锁。 优化 1:索引上的等值查询,给唯一索引加锁的时候,next-key lock 退化为行锁。 优化 2:索引上的等值查询,向右遍历时且最后一个值不满足等值条件的时候,next-key lock 退化为间隙锁。 一个 bug:唯一索引上的范围查询会访问到不满足条件的第一个值为止。
然后是这次用到的表和数据
CREATE TABLE `t` ( `id` int(11) NOT NULL, `c` int(11) DEFAULT NULL, `d` int(11) DEFAULT NULL, PRIMARY KEY (`id`), KEY `c` (`c`) ) ENGINE=InnoDB; insert into t values(0,0,0),(5,5,5), (10,10,10),(15,15,15),(20,20,20),(25,25,25);
再然后就是实际例子了
1.在主键上,访问不存在的数据

根据原则1加的next-key lock锁是id(5,10],因为id等于7的数据并不存在,所以不满足优化1,根据优化2将会退化为间隙锁id(5,10),从上面的实际例子中也能看出来,只有插入id=6的数据在等待锁,id=4、11、10、5的数据在插入和更新的时候都正常。
2.在主键上,访问存在的数据

这个和上一个例子类似区别是满足优化1所以就从next-key lock锁id(5,10],退化为id=5的行锁,所以id=6,4的数据可以插入进去,只有id=5的数据在更新的时候等待锁。
3.在主键上 范围查询时会根据扫描的情况加锁

这种情况就是
- 根据原则1加的是next-key lock锁id(0,5],
- 根据bug知道扫描到了10所以还加了next-key lock锁id(0,10]
- 再然后根据优化2,因为这里有等值查询(id=5),所以next-key lock锁id(0,5]退化成了id=5行锁
所以id=4、11的数据可以插入,而id=6、10的数据的更新和插入的时候需要等待锁
4.在主键上 范围查询时会根据扫描的情况加锁2

分析:
- 根据原则1加上了id(5,10],id(10,15]的next-key lock锁
- 根据优化1id(10,15]的next-key lock锁退化成行锁id=10
但是实际情况上id=11的数据插入也需要等待锁,这就是上面规则说的bug唯一索引上的范围查询会访问到不满足条件的第一个值为止,这里的id<=10,会一直扫描到id=15,所以会加上(10,15]的next-key lock锁
5.在非唯一索引上等值查询的情况
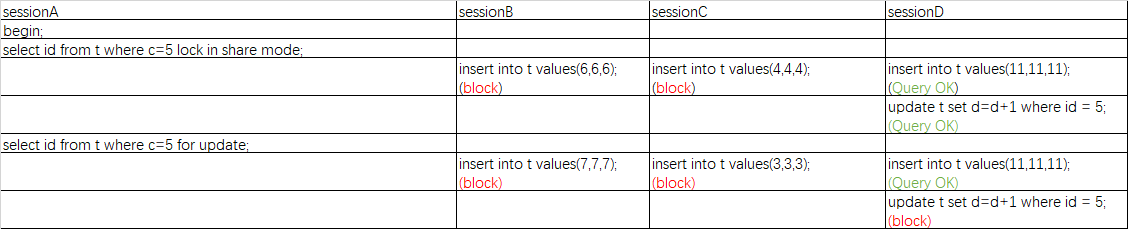
这其实是两个例子,因为只有一个区别就放一起了,先按照规则来分析
- 根据原则1就能知道都加上了c(0,5],c(5,10]的next-key lock锁
- 根据优化2c(5,10]的next-key lock锁会退化为c(5,10)的间隙锁
这两个加锁的区别就是对于id=5的锁的问题,lock in share mode没有对id=5加锁,所以可以得到的信息是,lock in share mode只锁覆盖索引,但是如果是 for update 就不一样了。 执行 for update 时,系统会认为你接下来要更新数据,因此会顺便给主键索引上满足条件的行加上行锁。
6.在非唯一索引上范围查询的情况

这个和例3类似,区别是这里不是主键,也就是说不是唯一索引,所以这里的分析过程就是
- 根据原则1加上了c(0,5],c(5,10]的next-key lock锁
- 因为不是唯一索引不满足优化1,所以c(0,5]不会退化成c=5的行锁,所以最终结果就是c(0,5],c(5,10]
7.在非唯一索引范围查询时 会根据扫描的情况加锁
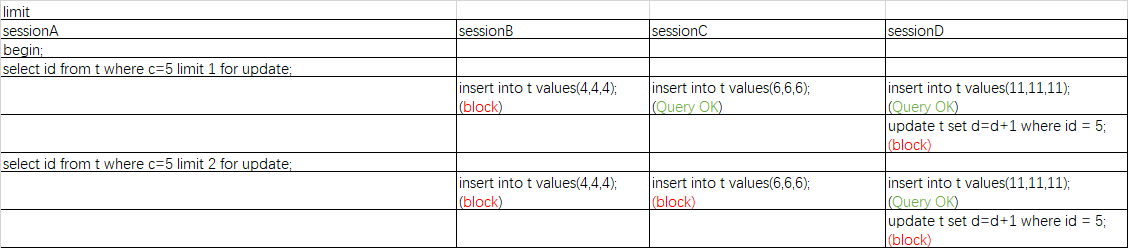
这个例子和例5类似,区别就是limit的问题,因为规则中总结的bug可以解释,limit 1只需要扫描一行,所以c(5,10)的间隙锁就没加上,而limit 2就再次证明了,如果需要返回两条数据需要再扫描就加上了c(5,10)的间隙锁
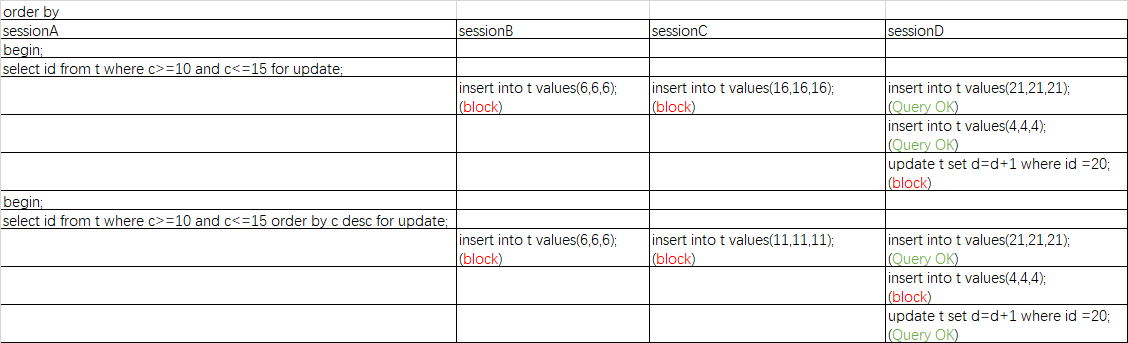
先来分析没有order by的情况:
- 根据原则1c(5,10]、c(10,15]、c(15,20]都加上了next-key lock锁
- 根据优化2c(15,20]退化为间隙锁,c(15,20)
- 根据bugc<=15会一直扫描到20,所以c(10,15]的锁还是会加上
- 所以最终结果是c(5,10]、c(10,15]、c(15,20]都加上了锁
然后是有order by desc的情况:
- 因为order by所以第一个定位的是索引上c=15的数据行,所以会加上c(10,15]的next-key lock锁和c(15,20)的间隙锁
- 因为向左扫描,扫描到了c=5才停下来,所以加上了c(0,5]、c(5,10]的next-key lock锁
- 因为c=5、c=10、c=15都有值,且select id,所以这三行的id索引上加了3个行锁
- 所以最终情况是c(5,20),id=5、10、15的锁
总结
这上面总结的规则,其实没啥道理可言,MySQL代码就是这样写的,加锁的意义是实际上为了保持数据的一致性和语义的正确,从例子4我们就能看到明明我们想锁的是5-10,但是因为bug(10,15]也加上了锁。所以考虑MySQL的这个加锁问题的时候,最好还是根据扫描的情况来考虑
然后是一些细节的记录:
- <=a 怎么判断是间隙锁还是行锁,这个要看扫描的过程来看,要先找到这个a,这个用等值判断来判定,然后在索引中扫描的过程使用范围查找来判断,就像最后一个例子中的order by desc一样,向左向右扫描出现的情况也不一样
- 加锁的情况其实不仅仅是通过for update 和lock in share mode来决定的,还得看查询的结果,如果是select * 查到了主键,一样会锁主键索引,这和访问的对象有关,访问到了就加锁,就像扫描一样
- 有行才会加行锁,如果查询没有命中行就加next-key lock锁,然后如果是等值查询还需要根据优化2来判断怎么加间隙锁

 浙公网安备 33010602011771号
浙公网安备 33010602011771号