


在深度学习当中,我们训练模型通常要对模型进行反复的优化训练,仅用CPU来进行训练的话需要花费很长时间,但是我们可以使用GPU来加速训练模型,这样就可以大大减少训练模型花费的时间。
首先我们需要一张NVIDIA显卡
在搜索栏中搜索设备管理器
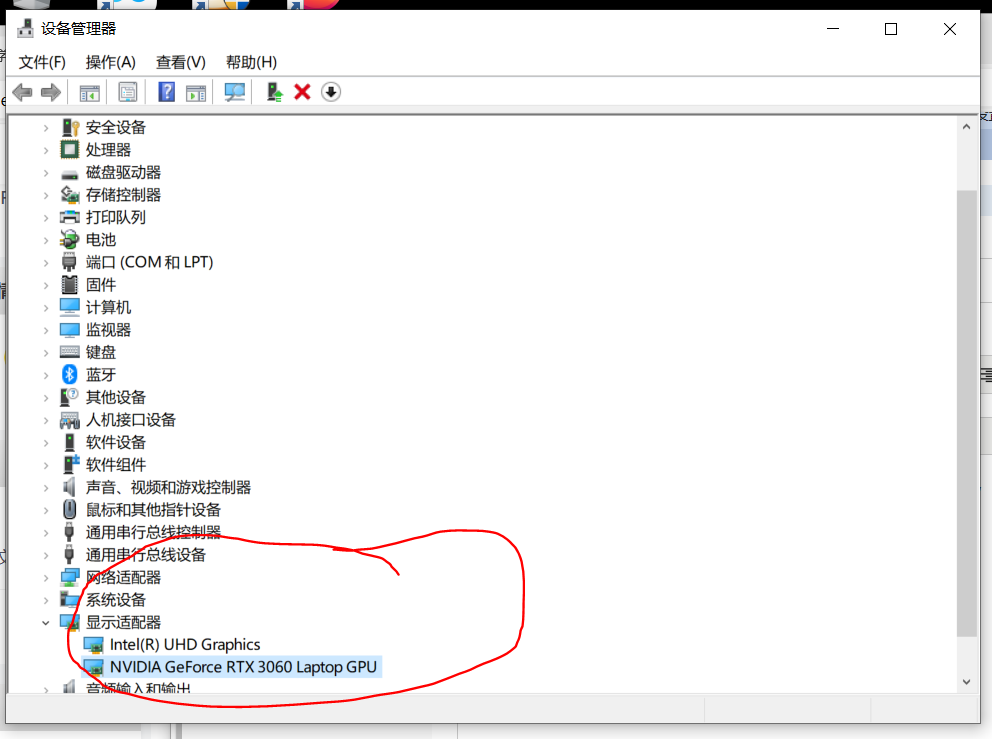
前往NVIDIA官网下载显卡对应的Studio驱动
NVIDIA GeForce 驱动程序 - N 卡驱动 | NVIDIA
(尽量安装比较早的驱动可以避免适配问题,新的应该也没什么大碍)
下载完直接安装在默认目录就行了
打开CMD输入
nvidia-smi
获取驱动对应的CUDA版本

去CUDA官网下载对应的CUDA版本
CUDA Toolkit Archive | NVIDIA Developer
同样安装在默认目录
需要注意的是,我们在这里选择自定义安装方式,取消勾选Visual Studio Integration(如果你有Visual Stduio环境可以忽略)
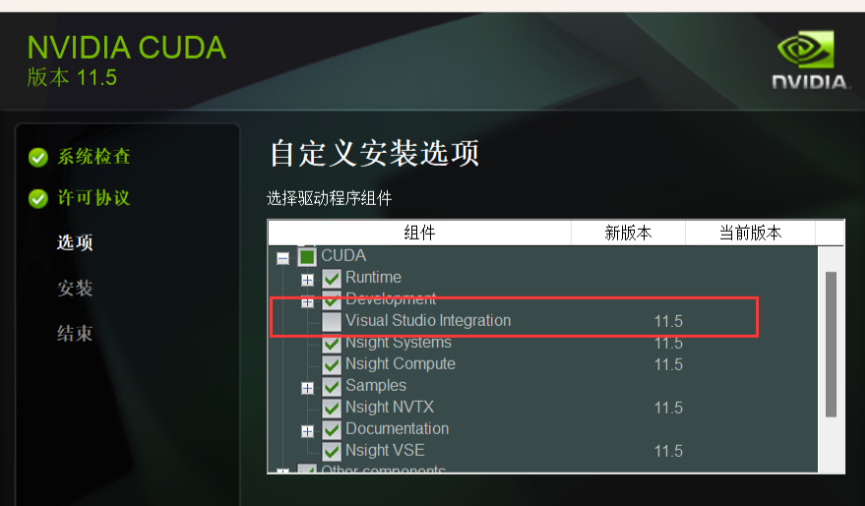
其他的可以不管
安装成功后应当会在系统变量中自动添加这几个环境变量

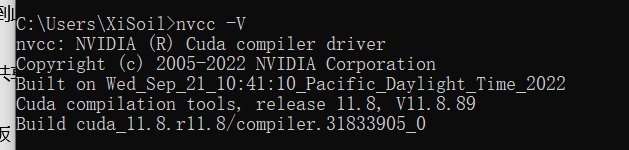
也可以打开cmd输入
nvcc -V 进行检验
下载cudnn的包
cuDNN Archive | NVIDIA Developer
解压之后,把这三个包复制到CUDA的本体文件夹中,然后替换相同文件,这个文件夹我们还需要设置环境变量

在path中添加最后的环境变量
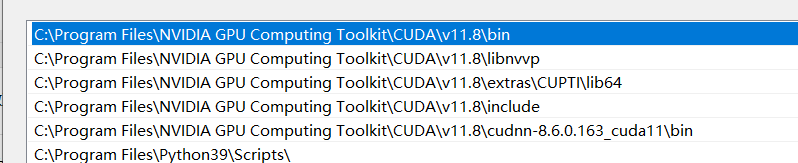
前四个都是CUDA本体,第五个是cuDNN这个包的bin文件夹(我把它放在CUDA本体的位置方便管理)
