
ElasticSearch为什么这么快
概要
1.高效的压缩
2.快速的编码解码
多维度分析
架构设计
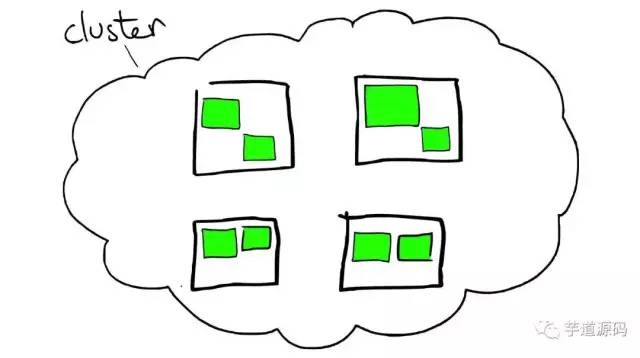
- cluster 集群
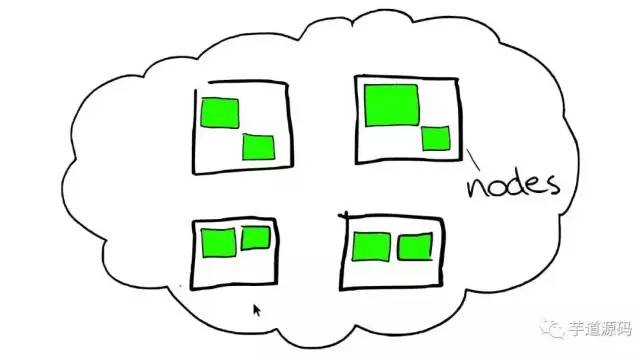
- node 节点--》机器
 index 索引
index 索引
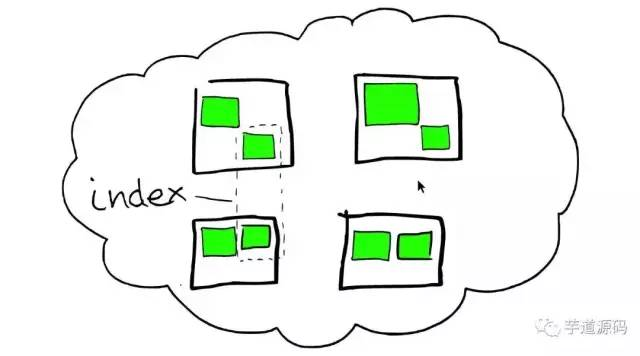
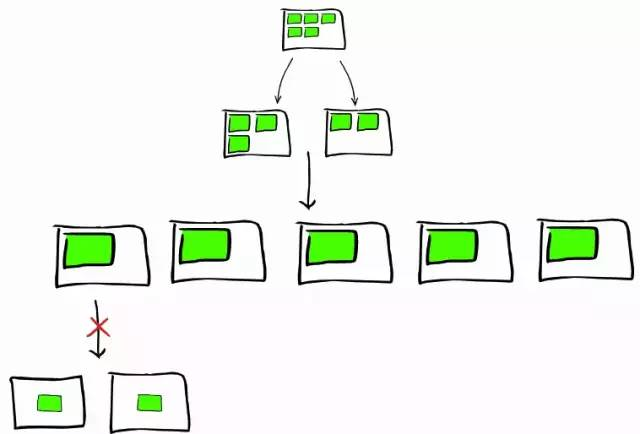
- 由一个或者多个节点,多个绿色小方块组合在一起形成一个ElasticSearch的索引
- shard 分片
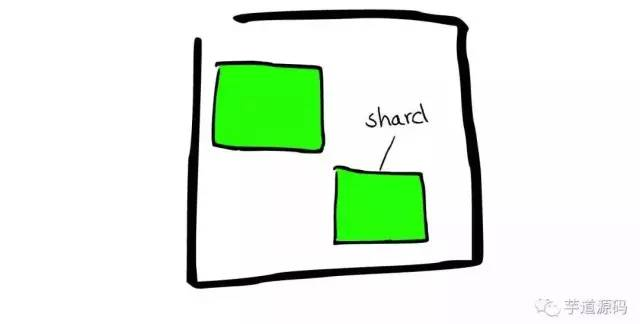
- Lucene Index
 Segment
Segment
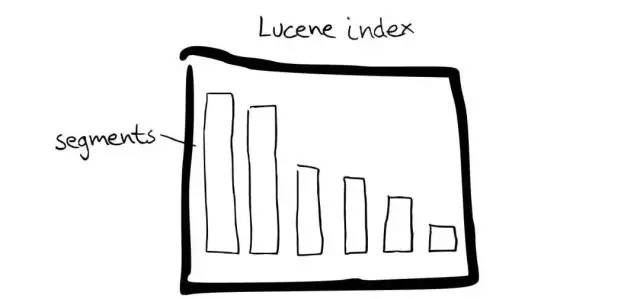
- 在Lucene里面有很多小的Segment,即为存储的最小管理单元
多节点的集群方案
多节点的集群方案,提高了整个系统的并发处理能力。
路由一个文档到一个分片中:当索引一个文档的时候,文档会被存储到一个主分片中。Elasticsearch 如何知道一个文档应该存放到哪个分片中呢?实际上,这个过程是根据下面这个公式决定的:
shard = hash(routing) %
number_of_primary_shards
routing 是一个可变值,默认是文档的 _id ,也可以设置成一个自定义的值。这就解释了为什么我们要在创建索引的时候就确定好主分片的数量,并且永远不会改变这个数量:因为如果数量变化了,那么所有之前路由的值都会无效,文档也再也找不到了。
确定了在哪个分片中,继而可以判定其在哪个节点上。
那么主分片数确定的情况下,如果做集群扩容呢?下图是一种主分片的扩容办法,开始设置为5个分片,在单个节点上,后来扩容到5个节点,每个节点有一个分片。也就是说单个分片的容量变大了,但是数量并不增加。
协调节点
节点分为主节点 Master Node、数据节点 Data Node和客户端节点 Client Node(单纯为了做请求的分发和汇总)。每个节点都可以接受客户端的请求,每个节点都知道集群中任一文档位置,所以可以直接将请求转发到需要的节点上。当接受请求后,节点变为「协调节点」。从这个角度,整个系统可以接受更高的并发请求,当然搜索的就更快了。
以更新文档为例:
-
客户端向 Node 1 发送更新请求。
-
它将请求转发到主分片所在的 Node 3 。
-
Node 3 从主分片检索文档,修改
_source字段中的 JSON ,并且尝试重新索引主分片的文档。如果文档已经被另一个进程修改,它会重试步骤 3 ,超过retry_on_conflict次后放弃。 -
如果 Node 3 成功地更新文档,它将新版本的文档并行转发到 Node 1 和 Node 2 上的副本分片,重新建立索引。一旦所有副本分片都返回成功, Node 3 向协调节点也返回成功,协调节点向客户端返回成功
乐观并发控制
Elasticsearch 中使用的这种方法假定冲突是不可能发生的,并且不会阻塞正在尝试的操作。因为没有阻塞,所以提升了索引的速度,同时可以通过_version字段来保证并发情况下的正确性:
PUT /website/blog/1?version=1
{
"title": "My first blog entry",
"text": "Starting to get the hang of this..."
}
索引
倒排索引
- 数据
| ID | Name | Age | Sex |
|---|---|---|---|
| 1 | Kate | 24 | Female |
| 2 | John | 24 | Male |
| 3 | Bill | 29 | Male |
- 索引
Name
| Term | Posting List |
|---|---|
| Kate | 1 |
| John | 2 |
| Bill | 3 |
Age
| Term | Posting List |
|---|---|
| 24 | [1,2] |
| 29 | 3 |
Sex
| Term | Posting List |
|---|---|
| Female | 1 |
| Male | [2,3] |
Posting List
简介:倒排表 int数组,存储了所有符合某个term的文档id。
压缩算法:
FOR:稠密数组
RBM:稀疏数组
Term Dictionary
简介:将所有的term排序,二分法查找term,logN的查找效率,就像通过字典树查找一样。
Term Index
B-Tree通过减少磁盘寻道次数来提高查询性能,Elasticsearch也是采用同样的思路,直接通过内存查找term,不读磁盘,但是如果term太多,term dictionary也会很大,放内存不现实,于是有了Term Index,就像字典里的索引页一样,A开头的有哪些term,分别在哪页,可以理解term index是一颗树
Term Index → Term Directionary → Posting List
term index不需要存下所有的term,而仅仅是他们的一些前缀与Term Dictionary的block之间的映射关系。再结合FST的压缩技术,可以使term index缓存到内存中。从term index查到对应的term dictionary的block位置之后,再去磁盘上找term,大大减少了磁盘随机读的次数。
数据结构
fsm:有限状态机
有限的状态
不同状态可以相互转换
同一时间只有一个状态
fsa:有限状态接收机
FST--有限状态转移机 键值对
数据结构演示: https://www.cs.usfcas.edu/~galles/visualization/Algorithms.html
fst 演示:http://examples.mikemccandless.com/fst.py
原理简析:
- 插入mon

- 插入thurs

- 插入thurs的时候,会导致之前的mon被冻结。当FSA中一部分被冻结的时候,我们知道,它以后再也不会被更改了。因为按照字典序排序的,后面的key肯定都是大于等于thurs的。因此不会和mon有相同前缀的key插入了。蓝色的state代表被冻结住,以后不会被更改但是可以被复用。
虚线的状态表示thurs还没有被真正加入到FSA中去,下面插入tues:
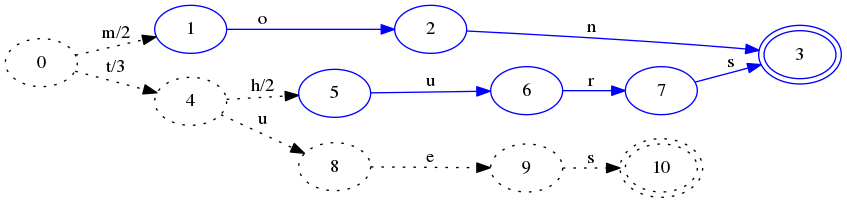
-
在这一步里,我们可以确定hurs会被冻住。因为将会不会有和它有相同前缀的词插入进来了。因为thurs和mon可以有相同的final state了。
这里状态4仍然是虚线,因为还不能确定t开头的key还有没有了。如果下面插入zon:
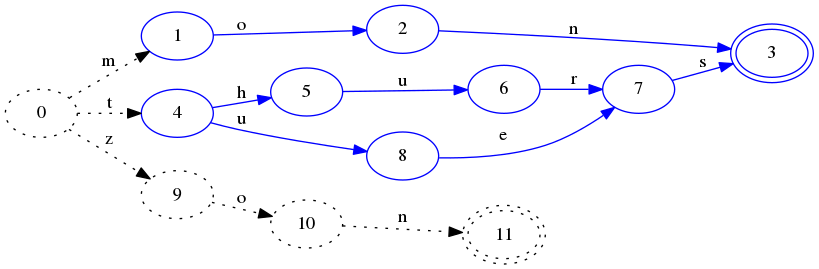
-
看到,这时状态4已经被冻住了,因为不会在有t开头的key出现了,另外thurs和tues有一个共同的后缀s,因此状态7和状态9被合并了。
最后,在结束操作以后,把FSA的最后一部分冻住,一个完整的没有重复的结构如下:
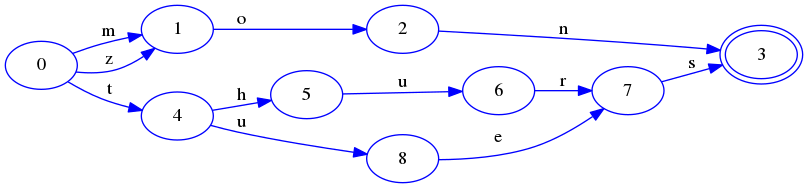
对比trie
- 插入mon
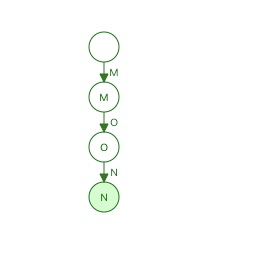
- 插入thurs
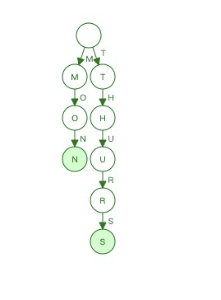
- 插入tues
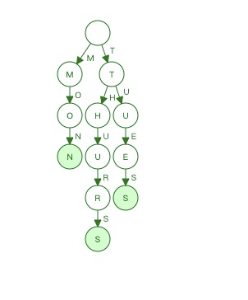
- 插入zon
优点:
- 空间占用小。通过对词典中单词前缀和后缀的重复利用,压缩了存储空间
- 查询速度快。O(len(str))的查询时间复杂度
联合查询
回到上面的例子,给定查询过滤条件 age=24 的过程就是先从 term index 找到 24 在 term dictionary 的大概位置,然后再从 term dictionary 里精确地找到 24 这个 term,然后得到一个 posting list 或者一个指向 posting list 位置的指针。然后再查询 sex=Female 的过程也是类似的。最后得出 age= 24 AND sex=Female 就是把两个 posting list 做一个“与”的合并。
这个理论上的“与”合并的操作可不容易。对于 mysql 来说,如果你给 age 和 gender 两个字段都建立了索引,查询的时候只会选择其中最 selective 的来用,做回表,然后另外一个条件是在遍历行的过程中在内存中计算之后过滤掉。那么要如何才能联合使用两个索引呢?有两种办法:
-
使用 skip list 数据结构。同时遍历 gender 和 age 的 posting list,互相 skip;
-
使用 bitset 数据结构,对 gender 和 age 两个 filter 分别求出 bitset,对两个 bitset 做 AN 操作。
Elasticsearch 支持以上两种的联合索引方式,如果查询的 filter 缓存到了内存中(以 bitset 的形式),那么合并就是两个 bitset 的 AND。如果查询的 filter 没有缓存,那么就用 skip list 的方式去遍历两个 on disk 的 posting list。
评分算法
性能优化
es的性能问题主要是搜索性能,写的性能瓶颈在于服务器资源
查询性能主要表现在分片,路由,查询方式
分片:
-
每个分片本质上就是一个Lucene索引, 因此会消耗相应的文件句柄, 内存和CPU资源
-
每个搜索请求会调度到索引的每个分片中. 如果分片分散在不同的节点倒是问题不太. 但当分片开始竞争相同的硬件资源时, 性能便会逐步下降
-
ES使用词频统计来计算相关性. 当然这些统计也会分配到各个分片上. 如果在大量分片上只维护了很少的数据, 则将导致最终的文档相关性较差
-
ElasticSearch推荐的最大JVM堆空间是30~32G, 所以把你的分片最大容量限制为30GB, 然后再对分片数量做合理估算. 例如, 你认为你的数据能达到200GB, 我们推荐你最多分配7到8个分片。
路由:尽量控制相同数据放在同一个路由中
查询方式:
- 减少查询分片数,控制范围
- 深度分页查询
-
es因性能做了默认返回10000条数据的限制
es 默认采用的分页方式是 from+ size 的形式,在深度分页的情况下,这种使用方式效率是非常低的
例子:
GET /student/student/_search
{
"query":{
"match_all": {}
},
"from":5000,
"size":10
}如果现在需要执行上面这个查询,
意味着 es 需要在各个分片上匹配排序并得到5010条数据,协调节点拿到这些数据再进行排序等处理,然后结果集中取最后10条数据返回。
我们会发现这样的深度分页将会使得效率非常低,因为我只需要查询10条数据,而es则需要执行from+size条数据然后处理后返回。
其次:es为了性能,限制了我们分页的深度,es目前支持的最大的 max_result_window = 10000;也就是说我们不能分页到10000条数据以上。
from + size <= 10000所以这个分页深度依然能够执行。
那么这种情况怎么解决呢?
- scroll search
- 游标的方式,相当于mysql中生成快照的方式,所以如果在游标查询期间有增删改操作,是获取不到最新的数据的.
- search_after
- search_after 是一种假分页方式,根据上一页的最后一条数据来确定下一页的位置,同时在分页请求的过程中,如果有索引数据的增删改查,这些变更也会实时的反映到游标上。为了找到每一页最后一条数据,每个文档必须有一个全局唯一值,官方推荐使用 _uid 作为全局唯一值,但是只要能表示其唯一性就可以。
对比三种分页方式
分页方式 性能 优点 缺点 场景 from + size 低 灵活性好,实现简单 深度分页问题 数据量比较小,能容忍深度分页问题 scroll 中 解决了深度分页问题 无法反应数据的实时性(快照版本)
维护成本高,需要维护一个 scroll_id
海量数据的导出(比如笔者刚遇到的将es中20w的数据导入到excel)
需要查询海量结果集的数据
search_after 高 性能最好
不存在深度分页问题
能够反映数据的实时变更
实现复杂,需要有一个全局唯一的字段
连续分页的实现会比较复杂,因为每一次查询都需要上次查询的结果
海量数据的分页 - scroll search
-
监控
-
X-Pack的Monitoring(监控组件)
-
Grafana :https://blog.csdn.net/DPnice/article/details/80818217
-
kibana 仪表盘

