数据库连接池(dbcp、c3p0)与DBUtils工具包的使用
目 录(本篇字数:3036)
-
介绍
我们知道JDBC是连接数据库的基石,JDBC为Java访问数据库提供了简单、易用的功能特性。通常我们使用JDBC获取数据库连接时,只需要配置几步必要的参数就可以,虽然我们获取了连接,但是这个连接的获取却来自不易。
为什么说来之不易呢,也许你会觉得,我的代码连接数据库都是非常快的啊,叮,它就能给我查询出来想要的结果。这是没错的,通常这是在我们本地调试的情况下,这个状态下连接数据库几乎没有并发连接情况,这个时候是最理想的状态。但一个服务器不可能仅在本地使用,所以就有以下这种情况。
如果我们将数据库发布到云服务器上,现在有成千上万的用户在同时访问数据库,如果你的服务器不是特别高端,或者说在一个配置不咋样的服务器上来同时访问,每次访问数据库 Connection 就会被加载到内存中,当在庞大的并发量下,你的服务器就会boom(奔溃了)。如果不限制并发连接的数量,那系统就会毫无顾及的一直将资源消耗下去,直到它内存溢出。
例如下面获取数据库连接的代码:
@Deprecated
public static Connection getConnection() throws Exception {
String driver = null;
String jdbcUrl = null;
String user = null;
String password = null;
InputStream inputStream = JdbcUtils.class.getClassLoader().getResourceAsStream("jdbc.properties");
Properties properties = new Properties();
properties.load(inputStream);
driver = properties.getProperty("driver");
jdbcUrl = properties.getProperty("jdbcUrl");
user = properties.getProperty("user");
password = properties.getProperty("password");
Class.forName(driver);
return (Connection) DriverManager.getConnection(jdbcUrl, user, password);
}-
数据库连接池
就如上面所说的那样,这种实现方式去获取连接,每次我们一关闭连接又得重新来获取,显得有点鸡肋,而且无法控制并发数量,一般在企业开发中是不会用这种方式去获取数据库连接的。所以,我们就引入了数据库连接池(Connection Pool)的概念。
什么是数据库连接池呢?看名词的字面意思,就是存储数据库连接的一个池子,和线程池的概念类似。一个存放数据库连接的池子,它应该有大小(连接数量)、进出水量(连接的并发量)、不能溢出(连接最大数量)、不能干涸(连接最小数量)等等属性。
关于数据库连接池的一些官方介绍:
- 数据库连接池的基本思想就是为数据库连接建立一个“缓冲池”。预先在缓冲池中放入一定数量的连接,当需要建立数据库连接时,只需从“缓冲池”中取出一个,使用完毕之后再放回去。
- 数据库连接池负责分配、管理和释放数据库连接,它允许应用程序重复使用一个现有的数据库连接,而不是重新建立一个。
- 数据库连接池在初始化时将创建一定数量的数据库连接放到连接池中,这些数据库连接的数量是由最小数据库连接数来设定的。无论这些数据库连接是否被使用,连接池都将一直保证至少拥有这么多的连接数量。连接池的最大数据库连接数量限定了这个连接池能占有的最大连接数,当应用程序向连接池请求的连接数超过最大连接数量时,这些请求将被加入到等待队列中。
一、优点
- 资源重用,由于数据库连接得以重用,避免了频繁创建,释放连接引起的大量性能开销。在减少系统消耗的基础上,另一方面也增加了系统运行环境的平稳性。
- 更快的系统反应速度,数据库连接池在初始化过程中,往往已经创建了若干数据库连接置于连接池中备用。此时连接的初始化工作均已完成。对于业务请求处理而言,直接利用现有可用连接,避免了数据库连接初始化和释放过程的时间开销,从而减少了系统的响应时间
- 新的资源分配手段,对于多应用共享同一数据库的系统而言,可在应用层通过数据库连接池的配置,实现某一应用最大可用数据库连接数的限制,避免某一应用独占所有的数据库资源
- 统一的连接管理,避免数据库连接泄露 在较为完善的数据库连接池实现中,可根据预先的占用超时设定,强制回收被占用连接,从而避免了常规数据库连接操作中可能出现的资源泄露
二、开源工具
数据库连接池既然如此重要,那么一些开源组织也已经为我们准备好了两种开源的数据库连接池,我们不需要自己写数据库连接池,拿来就可以使用。这两种分别是:DBCP 、C3P0
1、DBCP连接池
DBCP(database connection pool),是 Apache 软件基金组织下的开源连接池实现,该连接池依赖该组织下的另一个开源系统:Common-pool

DBCP与JDBC一样,提供两种可连接的方式,一种是通过代码的方式(局限性比较大)。
@Test
public void dbcpTest() {
BasicDataSource dataSource = new BasicDataSource();
dataSource.setDriverClassName("com.mysql.jdbc.Driver");
dataSource.setUrl("jdbc:mysql://localhost:3306/person");
dataSource.setUsername("root");
dataSource.setPassword("123456");
// 指定初始化的连接数
dataSource.setInitialSize(50);
// 设置允许被同时连接的最大数,意味着同一时刻可以并发连接的最大数
dataSource.setMaxTotal(20);
// 设置向数据库连接时延迟的最长时间,超过该时间则连接失败
dataSource.setMaxWaitMillis(5 * 1000);
// 设置空闲时最小能保持的连接数,在连接关闭时,多余的连接数将在连接池中销毁
dataSource.setMinIdle(5);
try {
Connection conn = dataSource.getConnection();
System.out.println(conn);
System.out.println("连接成功了");
} catch (SQLException e) {
e.printStackTrace();
}
}另一种则是通过配置文件的方式:dbcp.properties

通过代码加载配置文件并连接
@Test
public void dbcpTest2() throws Exception {
Properties properties = new Properties();
InputStream inStream = this.getClass().getClassLoader().getResourceAsStream("dbcp.properties");
properties.load(inStream);
BasicDataSource dataSource = new BasicDataSourceFactory().createDataSource(properties);
Connection conn = dataSource.getConnection();
System.out.println(conn);
System.out.println("连接成功了");
}2、C3P0连接池
C3P0,它实现了数据源和JNDI绑定,支持JDBC3规范和JDBC2的标准扩展。目前使用它的开源项目有Hibernate,Spring等,这个被推荐使用,它需要的库如下:
通过代码连接:
@Test
public void c3p0Test() throws Exception{
ComboPooledDataSource cpds = new ComboPooledDataSource();
cpds.setDriverClass("com.mysql.jdbc.Driver");
cpds.setJdbcUrl("jdbc:mysql://localhost:3306/person");
cpds.setUser("root");
cpds.setPassword("123456");
Connection conn = cpds.getConnection();
System.out.println(conn);
System.out.println("连接成功了");
}C3P0比较特殊,它可以通过XML文件来配置连接属性,并且规定为:c3p0-config.xml
<?xml version="1.0" encoding="UTF-8"?>
<c3p0-config>
<named-config name="jdbcConfig">
<property name="driverClass">com.mysql.jdbc.Driver</property>
<property name="jdbcUrl">jdbc:mysql://localhost:3306/person</property>
<property name="user">root</property>
<property name="password">123456</property>
<!-- 当连接数量用尽时,可定期的增量数 -->
<property name="acquireIncrement">10</property>
<!-- 数据库初始化时,需要初始化连接池中连接的数量 -->
<property name="initialPoolSize">100</property>
<!-- 连接池的最小连接数 -->
<property name="minPoolSize">10</property>
<!-- 连接池的最大连接数 -->
<property name="maxPoolSize">200</property>
<!-- 连接池中 Statement 的最大个数 -->
<property name="maxStatements">20</property>
<!-- 连接池中每个连接可以同时使用的 Statement 的个数 -->
<property name="maxStatementsPerConnection">5</property>
</named-config>
</c3p0-config>连接代码:
@Test
public void c3p0Test2() throws Exception{
DataSource dataSource = new ComboPooledDataSource("jdbcConfig");
Connection conn = dataSource.getConnection();
System.out.println(conn);
System.out.println("连接成功了");
}3、区别
从代码上看,相比之下c3p0的代码更加精简,而且是被推荐于使用,大多第三方开源框架都是基于c3p0来建立连接的。从两个开源库本质特点上来说,它们应用于不同的场景,所以它们拥有各自的特点。
- dbcp:无法自动回收空闲的连接,提供最大的连接数,如果连接数超出,则会断开连接。
- c3p0,可以自动回收空闲的连接,提供最大的空闲时间,如果超出最大的连接时间,则会断开连接。
-
DBUtils工具包
DBUtils是Apache组织提供的一个开源JDBC工具类库,它是对JDBC的简单封装,学习成本极低,并且使用dbutils能极大简化JDBC编码的工作量,同时也不会影响程序的性能。
QueryRunner类简单化了SQL查询,它与ResultSetHandler接口组合在一起使用可以完成大部分的数据库操作,能够大大减少编码量。ResultSetHandler接口提供将数据按要求转换为另一种形式。
一、常用实现类
1、BeanHandler
将结果集中的第一行数据封装到一个对应的JavaBean实例中
例如:
@Test
public void testBeanHandler() {
QueryRunner queryRunner = new QueryRunner();
Connection conn = null;
try {
conn = JdbcUtils.getConnectionForC3P0();
String sql = "select username,password,register_time,sex,user_role,id_card from user where username=?";
User user = queryRunner.query(conn, sql, new BeanHandler<>(User.class), "小王");
System.out.println(user);
} catch (Exception e) {
e.printStackTrace();
} finally {
if (conn != null) {
JdbcUtils.release(null, conn, null);
}
}
}2、BeanListHandler
将结果集中的每一行数据都封装到一个对应的JavaBean实例中,存放到List里
例如:
@Test
public void testBeanListHandler() {
QueryRunner queryRunner = new QueryRunner();
Connection conn = null;
try {
conn = JdbcUtils.getConnectionForC3P0();
String sql = "select username,password,register_time,sex,user_role,id_card from user";
List<User> user = queryRunner.query(conn, sql, new BeanListHandler<>(User.class));
System.out.println(user);
} catch (Exception e) {
e.printStackTrace();
} finally {
if (conn != null) {
JdbcUtils.release(null, conn, null);
}
}
}3、MapHandler
将结果集中的第一行数据封装为一个Map
例如:
@Test
public void testMapHandler() {
QueryRunner queryRunner = new QueryRunner();
Connection conn = null;
try {
conn = JdbcUtils.getConnectionForC3P0();
String sql = "select username,password,register_time,sex,user_role,id_card from user where username=?";
Map<String, Object> user = queryRunner.query(conn, sql, new MapHandler(), "小王");
System.out.println(user);
} catch (Exception e) {
e.printStackTrace();
} finally {
if (conn != null) {
JdbcUtils.release(null, conn, null);
}
}
}4、MapListHandler
将结果集中的每一行数据都封装到一个Map里,然后再存放到List
例如:
@Test
public void testMapListHandler() {
QueryRunner queryRunner = new QueryRunner();
Connection conn = null;
try {
conn = JdbcUtils.getConnectionForC3P0();
String sql = "select username,password,register_time,sex,user_role,id_card from user";
List<Map<String, Object>> user = queryRunner.query(conn, sql, new MapListHandler());
System.out.println(user);
} catch (Exception e) {
e.printStackTrace();
} finally {
if (conn != null) {
JdbcUtils.release(null, conn, null);
}
}
}5、ScalarHandler
将结果集中的单个值返回
例如:
@Test
public void testScalarHandler2() {
QueryRunner queryRunner = new QueryRunner();
Connection conn = null;
try {
conn = JdbcUtils.getConnectionForC3P0();
String sql = "select register_time from user where id_card=?";
Object register_time = queryRunner.query(conn, sql, new ScalarHandler(), "321...");
System.out.println(register_time);
} catch (Exception e) {
e.printStackTrace();
} finally {
if (conn != null) {
JdbcUtils.release(null, conn, null);
}
}
}6、需注意的坑
通过BeanHandler和BeanListHandler得到的结果集会有不存在(NULL)的情况,比如这种情况下就会导致NULL,图:

出现这种情况的原因是:实体类(User)中的对应属性名与数据库的字段(列名)无法匹配,数据库的数据如下图:
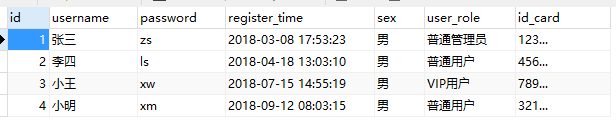
其中register_time、user_role、id_card与类变量registerTime、userRole、idCard无法对应赋值,这也是BeanHandler的一种缺陷,而其它如MapHandler、ScalarHandler就不会出现这种情况。
原因是:MapHandler、ScalarHandler的底层运用了反射来获取元数据的列名,所以它可以获取的到结果。
©原文链接:https://blog.csdn.net/smile_Running/article/details/86766460
@作者博客:_Xu2WeI
@更多博文:查看作者的更多博文

