目标
分析
- 根据接口分析,我们需要对密码逆向,识别验证码
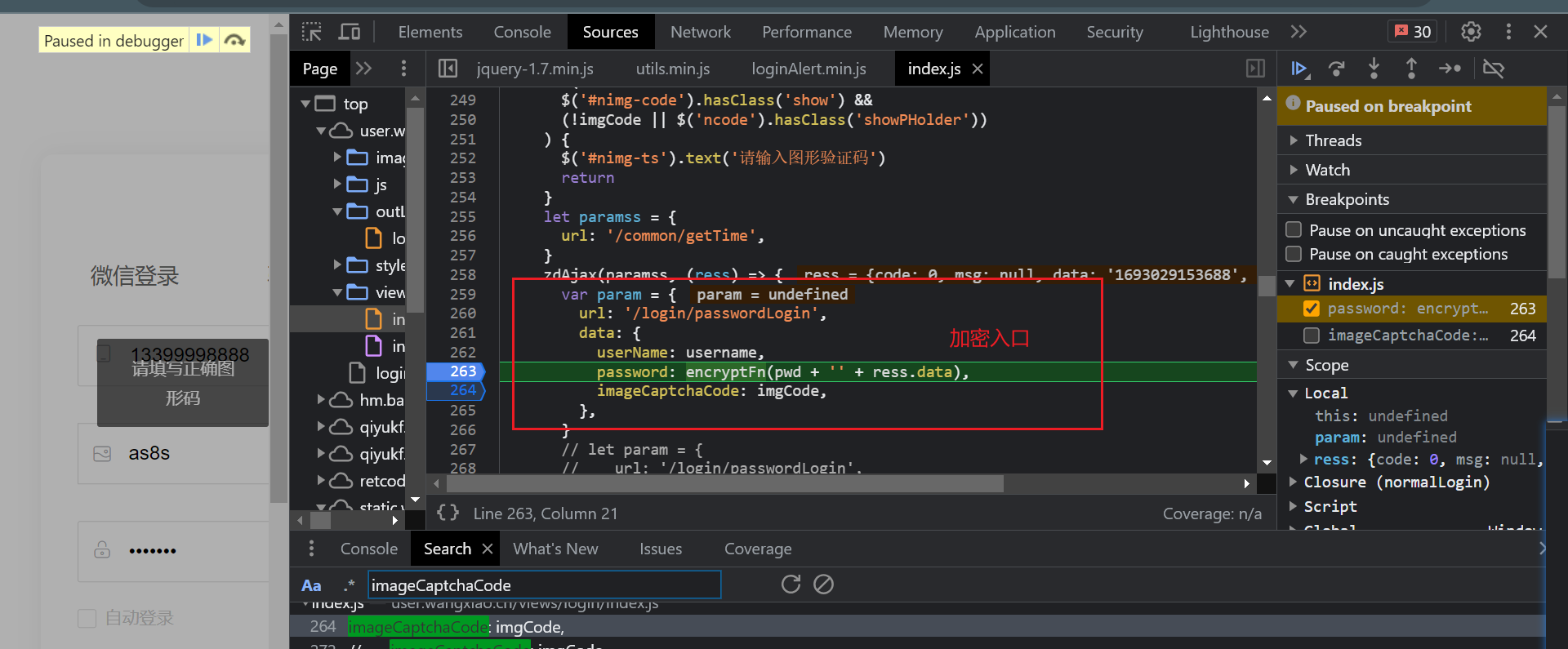
- 加密入口
![]()
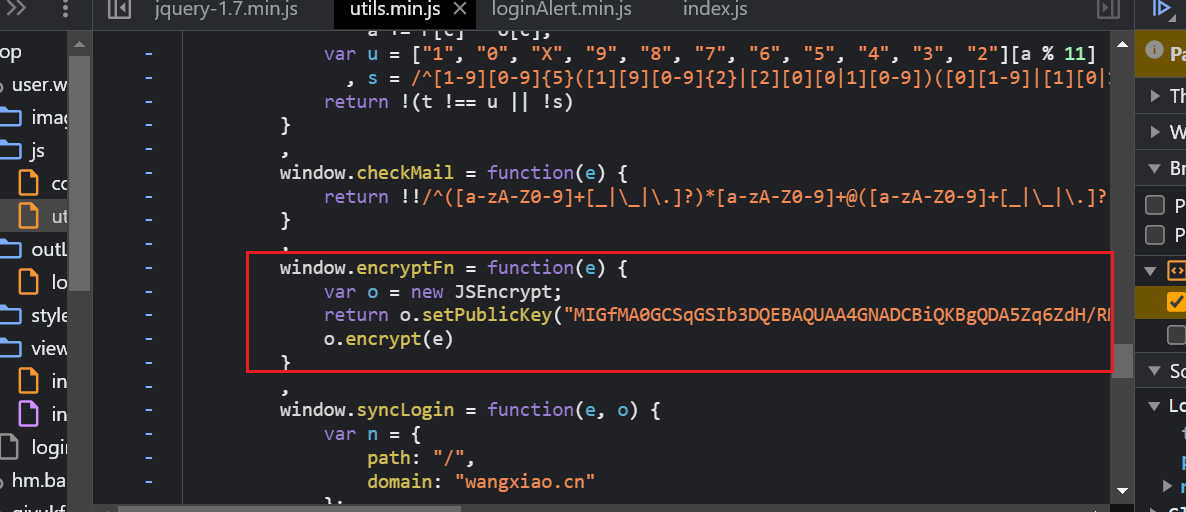
- 加密逻辑,标准的RSA加密
![]()
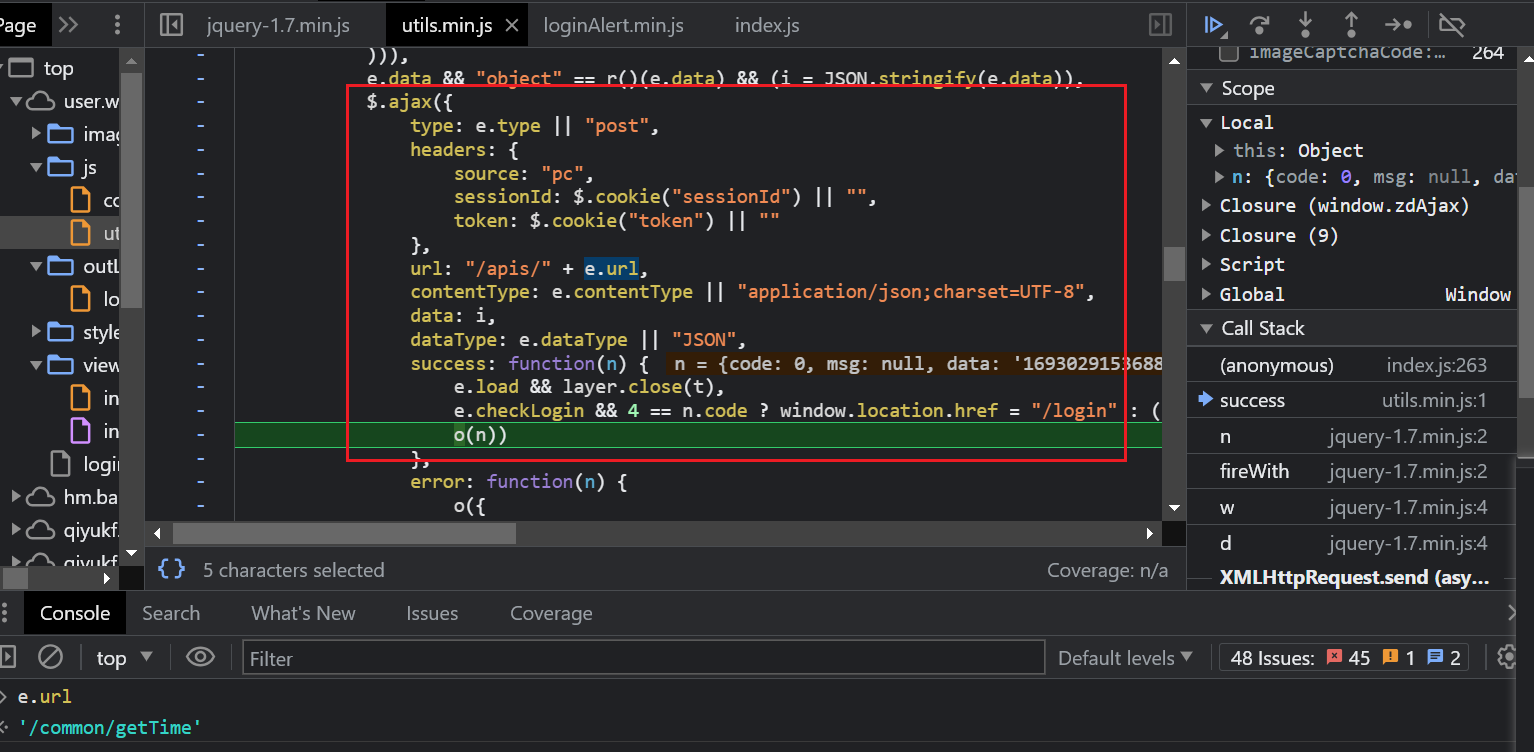
- 查找ress.data,注意:这里不一定是时间戳,不能简单暴力的使用data.now()代替;根据call stack往回找
- 发现此处的data是ajax请求,成功返回的数据,url就是gettime
![]()
- 所以此处的ress.data必须通过请求获取
![]()
- 验证码识别使用ddddocr获取其它三方平台,都可以正常破解
- 到目前为止,登录接口需要的参数已经全部准备好
登录不成功
- 根据获取到的参数及加密后,我们发现还是不能成功登录
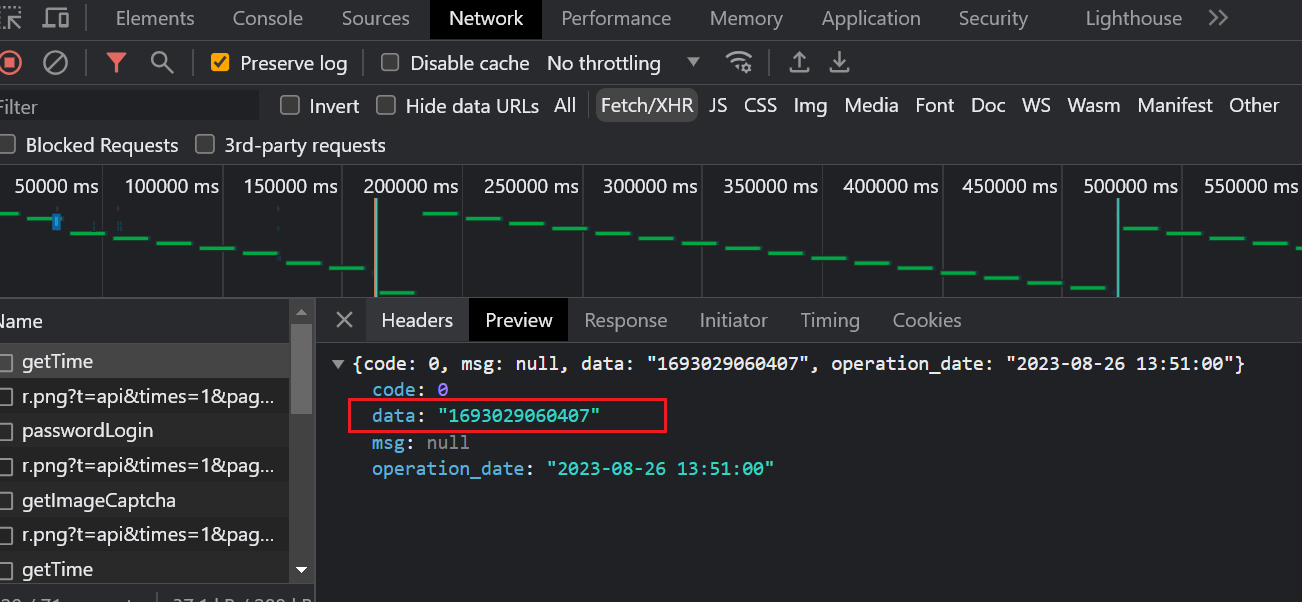
- 这里通过阅读代码,发现在登录成功后,还操作了cookies
- 注意点:这里是ajax操作的cookie,我们使用python中requests的保持session是无法实现的,必须手动处理
- 这里是网站封装了ajax
![]()
![]()
完整代码
import subprocess
from functools import partial
subprocess.Popen = partial(subprocess.Popen, encoding='utf-8')
import execjs
import requests
# pip install -i https://pypi.tuna.tsinghua.edu.cn/simple ddddocr
import ddddocr # 免费. 应对一些简单的验题.证码没问 包括滑块
import base64
import json
def login():
f = open("某网校登陆.js", mode="r", encoding="utf-8")
js = execjs.compile(f.read())
f.close()
session = requests.session()
session.headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36"
}
login_page_url = "https://user.XXXX.cn/login?url=http%3A%2F%2Fks.wangxiao.cn%2F"
session.get(login_page_url) # 走全流程. 防止遗漏cookie
# 怼请求头
session.headers['Content-Type'] = "application/json;charset=UTF-8"
# 获取验证码
img_url = "https://user.XXXX.cn/apis//common/getImageCaptcha"
img_resp = session.post(img_url)
img_dict = img_resp.json()
img_b64 = img_dict.get("data").replace("data:image/png;base64,", "")
img = base64.b64decode(img_b64)
with open("tu.png", mode="wb") as f:
f.write(img)
# 识别验证码 (图鉴, 超级鹰)
dddd = ddddocr.DdddOcr(show_ad=False)
result = dddd.classification(img)
print(result)
# 加密
# getTime
getTime_url = "https://user.XXXX.cn/apis//common/getTime"
getTime_resp = session.post(getTime_url)
getTime_data = getTime_resp.json().get("data")
print(getTime_data)
data = {
"imageCaptchaCode": result,
"password": js.call("encryptFn", "密码" + str(getTime_data)),
"userName": "用户名手机号",
}
login_url = "https://user.XXX.cn/apis//login/passwordLogin"
login_resp = session.post(login_url, data=json.dumps(data, separators=(',', ':')))
# 登陆成功后需要拿到登陆信息. 并保存到cookie
print(login_resp.json())
login_success_data = login_resp.json()['data']
session.cookies['autoLogin'] = "null"
session.cookies['userInfo'] = json.dumps(login_success_data, separators=(',', ':'))
session.cookies['token'] = login_success_data.get("token")
session.cookies["UserCookieName"] = login_success_data.get("userName")
session.cookies["OldUsername2"] = login_success_data.get("userNameCookies")
session.cookies["OldUsername"] = login_success_data.get("userNameCookies")
session.cookies["OldPassword"] = login_success_data.get("passwordCookies")
session.cookies["UserCookieName_"] = login_success_data.get("userName")
session.cookies["OldUsername2_"] = login_success_data.get("userNameCookies")
session.cookies["OldUsername_"] = login_success_data.get("userNameCookies")
session.cookies["OldPassword_"] = login_success_data.get("passwordCookies")
return session
# 只负责登陆
sess = login()
for i in range(1): # 如果需要反复请求获取数据
# 检测是否真的可以拿到数据了
question_url = "http://ks.XXXX.cn/practice/listQuestions"
data = {
"practiceType": "2",
"sign": "jz1",
"subsign": "8cc80ffb9a4a5c114953",
"examPointType": "",
"questionType": "",
"top": "30"
}
resp = sess.post(question_url, data=json.dumps(data, separators=(',', ':')))
if resp.text.startswith("<"): # 登陆失效了, 这个判断只针对该案例.
sess = login() # 重新登陆即可
print(resp.text)
// npm install node-jsencrypt
var JSEncrypt = require("node-jsencrypt");
function encryptFn (e) {
var o = new JSEncrypt;
return o.setPublicKey("MIGfMA0GCSqGSIb3DQEBAQUAA4GNADCBiQKBgQDA5Zq6ZdH/RMSvC8WKhp5gj6Ue4Lqjo0Q2PnyGbSkTlYku0HtVzbh3S9F9oHbxeO55E8tEEQ5wj/+52VMLavcuwkDypG66N6c1z0Fo2HgxV3e0tqt1wyNtmbwg7ruIYmFM+dErIpTiLRDvOy+0vgPcBVDfSUHwUSgUtIkyC47UNQIDAQAB"),
o.encrypt(e)
}





 浙公网安备 33010602011771号
浙公网安备 33010602011771号