


接口自动化之数据解析
-
一:平常我们做接口自动化时,需要将响应中的数据提取出来,主要有两个目的:
- 1、提取参数,作为下一个接口的入参
- 2、断言接口是否成功
-
二:Response返回的数据三种格式:
- 1、.content # 字节输出 byte
- 这种二进制数据,我们一般保存为本地文件即可,示例如下:
- 1、.content # 字节输出 byte
import requests
headers = {
'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.71 Safari/537.36X-Requested-With: XMLHttpRequest'
}
#获取图片地址:通常为img标签的src属性值
img_src = 'http://img.itlun.cn/uploads/allimg/180506/1-1P5061TS6-lp.jpg'
#对图片发起请求
response = requests.get(url=img_src,headers=headers)
#获取图片数据:content返回的是二进制形式的响应数据
img_data = response.content
#持久化存储
with open('./123.jpg','wb') as fp:
fp.write(img_data)
-
2、.text # str输出
- 方法1:使用正则提取(万能),这种后面详聊
- 方法2:如果返回的数据为html文件,此时我们可以使用xpath或者bs4等模块提取数据,详情参考小编爬虫的文章:
-
3、.json() # json格式数据,转为字典格式输出
#示例响应体
result ={
"code":200,
"message":"success",
"store": {
"book": [
{
"category": "reference",
"author": "Nigel Rees",
"title": "Sayings of the Century",
"price": 8.95
},
{
"category": "fiction",
"author": "Evelyn Waugh",
"title": "Sword of Honour",
"price": 12.99
},
{
"category": "fiction",
"author": "Herman Melville",
"title": "Moby Dick",
"isbn": "0-553-21311-3",
"price": 8.99
},
{
"category": "fiction",
"author": "J. R. R. Tolkien",
"title": "The Lord of the Rings",
"isbn": "0-395-19395-8",
"price": 22.99
}
],
"bicycle": {
"color": "red",
"price": 19.95
}
},
"expensive": 10
}
- 方法1:字典取值,此方法需要逐层往下取,如果路径较深而且需要判断的时候就不太方便了
print(result["code"])
print(result["expensive"])
print(result["store"]["book"][0]["title"])
#200
#10
#Sayings of the Century
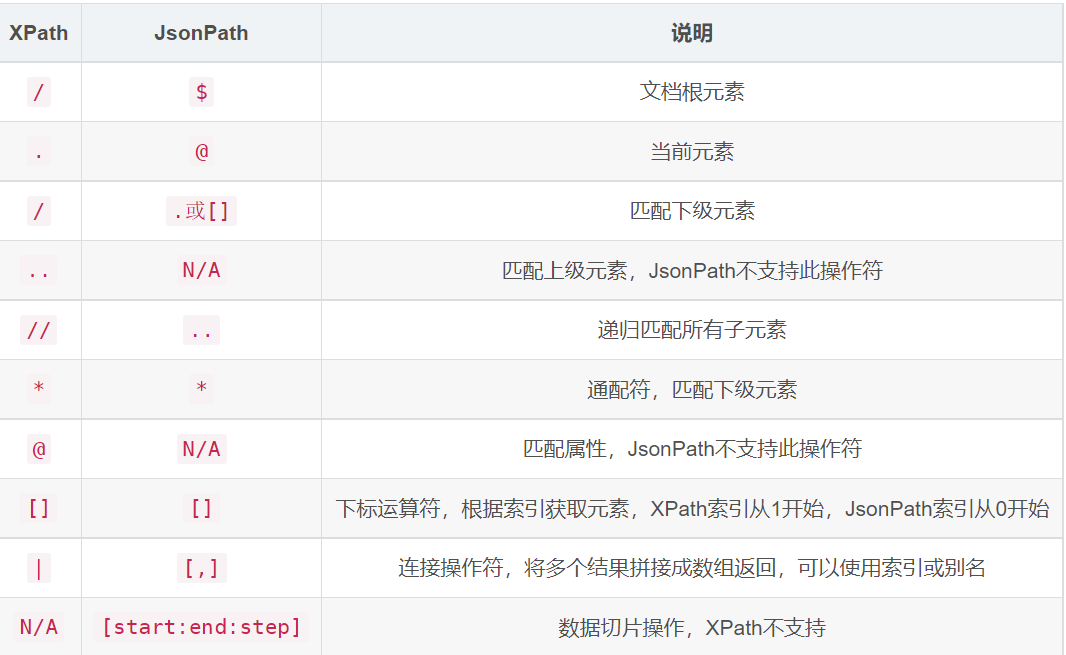
- 方法2:jsonpath取值,是一个非常强大并且方便的jsonpath专门用于json解析,解决路径深的老大难问题!
- 需要安装依赖包,pip install jsonpath
- 基本语法
import jsonpath
#提取所有book的作者
author_list = jsonpath.jsonpath(result,'$..author')
print(author_list)
#匹配第一个book节点
book_three = jsonpath.jsonpath(result,'$..book[0]')
print(book_three)
#匹配倒数第一个book节点
# book_last = jsonpath.jsonpath(result,'$..book[-1:]')
book_last = jsonpath.jsonpath(result,'$..book[(@.length-1)]')
print(book_last)
#过滤包含isbn的节点
isbn_list = jsonpath.jsonpath(result,'$..book[?(@.isbn)]')
print(isbn_list)
#过滤price<10的节点
price = jsonpath.jsonpath(result,'$..book[?(@.price<10)]')
print(price)

