
request高级之防盗链
-
现在很多网站启用了防盗链反爬,防止服务器上的资源被人恶意盗取。什么是防盗链呢?
- 以图片为例,访问图片要从他的网站访问才可以,否则直接访问图片地址得不到图片
-
练习,抓取微博图片,url: http://blog.sina.com.cn/lm/pic/ ,将页面中某一组系列详情页的图片进行抓取保存,比如三里屯时尚女郎:http://blog.sina.com.cn/s/blog_01ebcb8a0102zi2o.html?tj=1
-
1.在解析图片地址的时候,定位src的属性值,返回的内容和开发工具Element中看到的不一样,通过network查看网页源码发现需要解析real_src的值。
-
2.批量获取图片下载地址,请求下载地址保存图片
- 通过抓包分析,页面数据不是动态加载
- 代码实现:
import requests,os
from lxml import etree
dirName = '三里屯'
if not os.path.exists(dirName):
os.mkdir(dirName)
headers = {
'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.71 Safari/537.36'
}
url = 'http://blog.sina.com.cn/s/blog_01ebcb8a0102zi2o.html?tj=1'
page_text = requests.get(url=url,headers=headers).text
tree = etree.HTML(page_text)
#获取图片地址
img_list = tree.xpath('//*[@id="sina_keyword_ad_area2"]/div/a/img/@real_src')
for img in img_list:
img_name = img.split('/')[-1]+'.jpg'
img_data = requests.get(url =img,headers = headers).content
img_path = dirName + '/' + img_name
with open(img_path,'wb') as fp:
fp.write(img_data)
- 3.此时,我们发现直接请求real_src请求到的图片不显示
- 加上Refere请求头即可
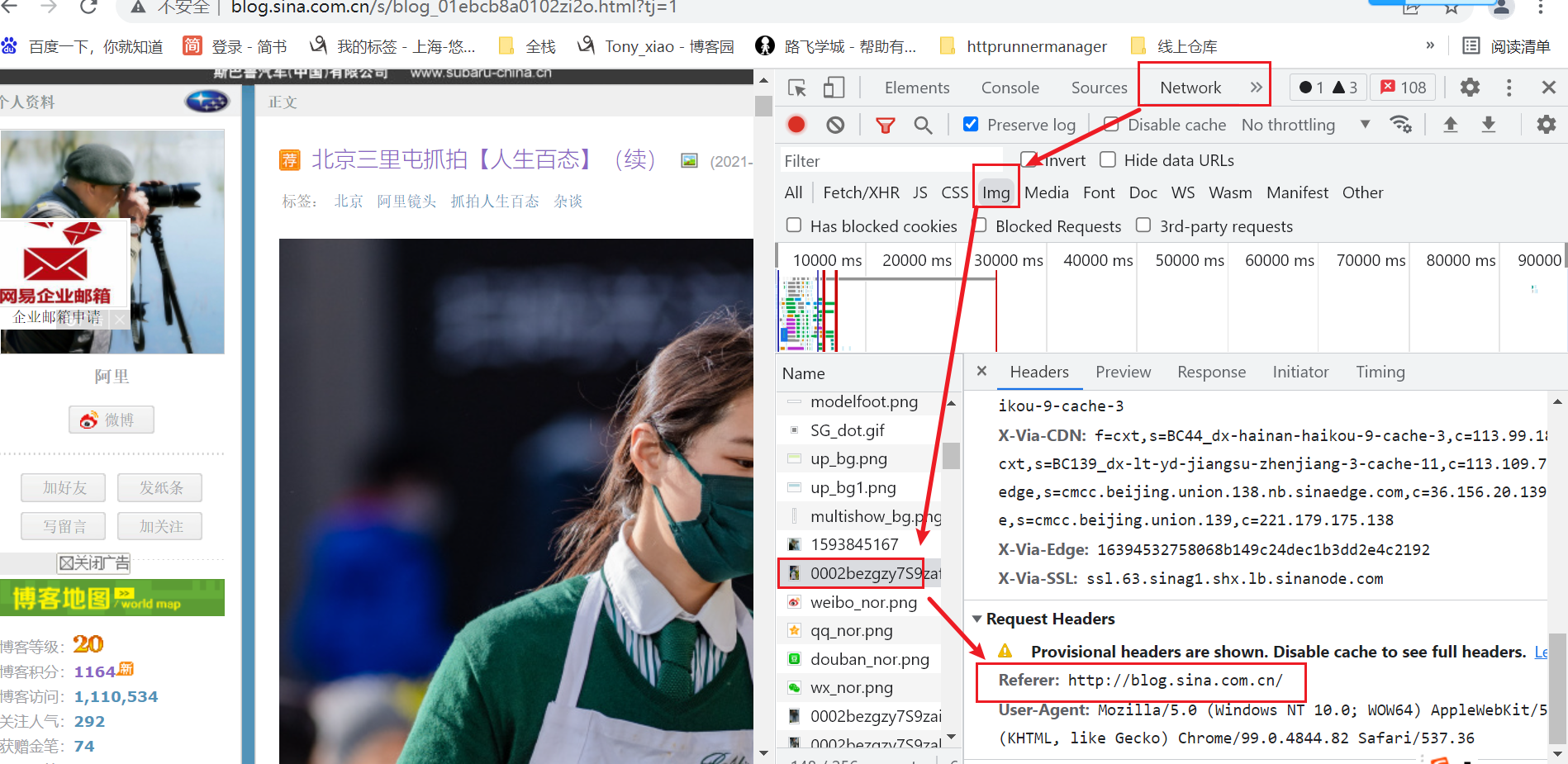
- 如何查找到Refere头信息勒
- 抓包工具中,Network--->找到img--->找到界面上任意一张图片的数据包,request headers中找到Refere信息
![]()
- 将Refere信息添加到headers中即可
- 抓包工具中,Network--->找到img--->找到界面上任意一张图片的数据包,request headers中找到Refere信息
import requests,os
from lxml import etree
dirName = '三里屯'
if not os.path.exists(dirName):
os.mkdir(dirName)
headers = {
'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.71 Safari/537.36',
#添加Refere头信息
'Referer': 'http://blog.sina.com.cn/'
}
url = 'http://blog.sina.com.cn/s/blog_01ebcb8a0102zi2o.html?tj=1'
page_text = requests.get(url=url,headers=headers).text
tree = etree.HTML(page_text)
#获取图片地址
img_list = tree.xpath('//*[@id="sina_keyword_ad_area2"]/div/a/img/@real_src')
for img in img_list:
img_name = img.split('/')[-1]+'.jpg'
img_data = requests.get(url =img,headers = headers).content
img_path = dirName + '/' + img_name
with open(img_path,'wb') as fp:
fp.write(img_data)
- 4.再次打开下载的图片,正常显示

 浙公网安备 33010602011771号
浙公网安备 33010602011771号