函数简化代码和常见的内置函数
注:常见代码简化是可以通过别的形式来执行对代码的一些精简写法'个人认为要通过言简意赅的形式来表达自己的代码写的内容方便其他人去观看达到一目了然的地步'

一.三元表达式
三元表达式通常采用在,二选一的情况下
比大小
def index(a, b):
if a > b:
return a
else:
return b
res = index(5, 10)
print(res)
条件不成立范围值为10
三元表达式
def index(a, b):
res = a if a > b else b
print(res)
index(5,10)
条件不成立范围值为10条件成立就是5
二.各种生成式
1.生成列表
name_list = ['jason', 'tony', 'kevin']
"""要求列表后边加上good"""
new_list = [] # 生成一个空列表
for name in name_list: # for循环获取每个人的名字
res = name + 'good' # 拼接
new_list.append(res) # 放进去空字典中
print(new_list) # 读取字典内的数据
打印结果
['jasongood', 'tonygood', 'kevingood']
其实是产生了一个新的列表来包含那些需求
简写筛选功能
res = [name + 'good' for name in name_list if name == 'jason']
print(res)
结果是['jasongood'] 判断成立for循环自动停止
res = [name + 'good' for name in name_list if name != 'jason']
print(res)
结果是['tonygood', 'kevingood']不成立则跳过并不打印jason结果
"""列表式只允许出现for和if"""
2.字典生成式
l1 = ['name', 'age', 'salary']
l2 = ['thn', 18, 5000]
"""要求组成对应字典"""
new_dict = {} # 定义一个空字典
for i in range(len(l1)): # for循环拿到两个列表中对应的值(因为他们的索引值相等)
new_dict[l1[i]] = l2[i] # 所引取值对比
print(new_dict) # 打印
结果:
{'name': 'thn', 'age': 18, 'salary': 5000}
print要跟在for循环下边不然会跟着for循序的顺序走
生成字典
res = {l1[i]: l2[i] for i in range(len(l1))}
print(res)
结果:
{'name': 'thn', 'age': 18, 'salary': 5000}
同理
res = {l1[i]: l2[i] for i in range(len(l1)) if i == 1}
print(res)
结果:{'age': 18}
索引取值1
3.集合生成式
res = {i for i in range(10)}
print(res, type(res))
结果:{0, 1, 2, 3, 4, 5, 6, 7, 8, 9} <class 'set'>
res = {i for i in range(10) if i != 2}
print(res, type(res))
结果:{0, 1, 3, 4, 5, 6, 7, 8, 9} <class 'set'>
"""
生成式其实都大不差均为简写代码
"""
三.匿名函数
匿名函数意思就是没有名字的函数,需要结合其他函数一起使用:
匿名函数的定义:lambda 形参:返回值
info = {
'Aason': 5000,
'Jacob': 123,
'zark': 1000,
'berk': 200
}
# 求:薪资最高的人的姓名
'''
max底层可以看成是for循环依次比较 针对字典默认只能获取到k
获取到k之后如果是字符串的英文字母 则会按照ASCII码表转成数字比较
A~Z:65-90
a~z:97-122
'''
def index(k):
return info[k]
print(max(info,key=index)) # key对应的函数返回什么 max就以什么做比较的依据
# 比较的是v 返回的是k key相当于是可以更改比较规则的参数
# 上述代码可以简写 因为函数功能很单一
# print(max(info, key=lambda key: info[key]))
四.常见重要内置函数
1.内置函数,map(映射)
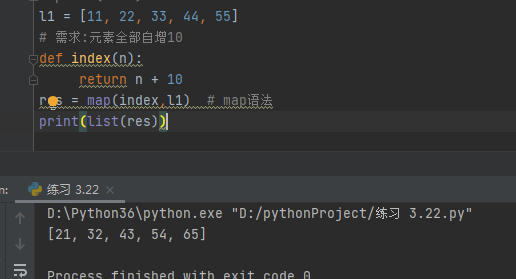
l1 = [11, 22, 33, 44, 55]
# 需求:元素全部自增10
def index(n):
return n + 10
res = map(index,l1) # map语法
print(res)
"""map()语法 map(function, iterable, ...) function -- 函数 iterable -- 一个或多个序列
对l1里的每一个元素执行匿名函数的操作"""
res = map(lambda x: x + 10, l1)
结果:
[21, 32, 43, 54, 65]
2.内置函数,zip(拉链)
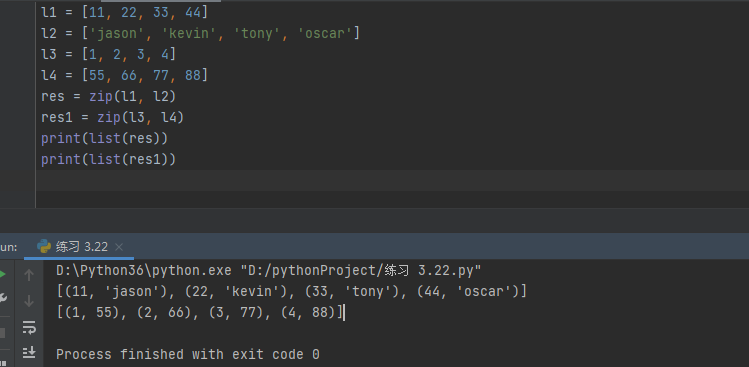
l1 = [11, 22, 33, 44]
l2 = ['jason', 'kevin', 'tony', 'oscar']
# 需求:将两个列表中的元素一一对应成对即可
"""zip() 将2或多个可迭代的对象里的参数按照相同的索引组成元组,在把每个元组组成列表返回"""
res = zip(l1, l2) # 结果是一个迭代器
print(res) # 目前想看里面的数据 用list转换一下即可
print(list(res)) # [(11, 'jason'), (22, 'kevin'), (33, 'tony'), (44, 'oscar')]
'''zip可以整合多个数据集'''
l1 = [11, 22, 33, 44]
l2 = ['jason', 'kevin', 'tony', 'oscar']
l3 = [1, 2, 3, 4]
l4 = [55, 66, 77, 88]
res = zip(l1, l2, l3, l4)
print(list(res))
# 不使用zip也可以
res1 = [(l1[i], l2[i], l3[i], l4[i]) for i in range(len(l1))]
print(res1)
# '''zip可以整合多个数据集 如果数据集之间个数不一致 那么依据短的'''
l1 = [11, 22, 33, 44, 55]
l2 = ['jason', 'kevin']
res = zip(l1, l2)
print(list(res))
3.内置函数 filter (过滤)
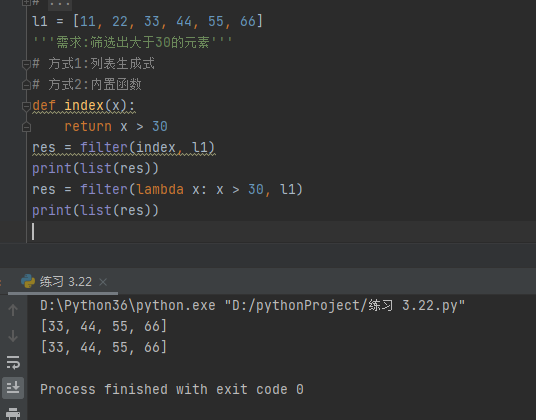
l1 = [11, 22, 33, 44, 55, 66]
'''需求:筛选出大于30的元素'''
方式1:列表生成式
def index(x):
return x > 30
res = filter(index, l1)
print(list(res))
方式2:内置函数
filter() 函数用于过滤序列,过滤掉不符合条件的元素,返回由符合条件元素组成的新列表。
该接收两个参数,第一个为函数,第二个为序列,序列的每个元素作为参数传递给函数进行判断,
然后返回 True 或 False,最后将返回 True 的元素放到新列表中。
res = filter(lambda x: x > 30, l1)
print(list(res))
4.内置函数 reduce(归总)
"""在python2.x版本中 reduce是内置函数,python3.x中需要加入模块"""
from functools import reduce
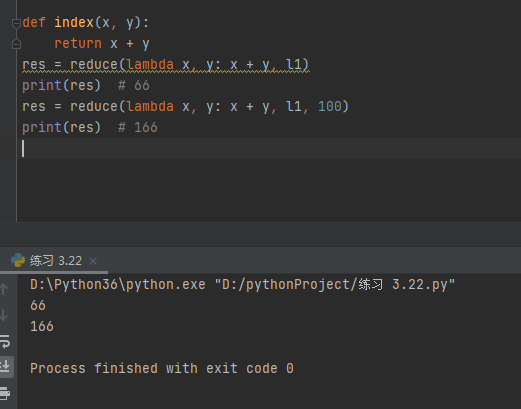
l1 = [11, 22, 33]
'''需求:讲列表中所有的元素相加'''
def index(x,y):
return x + y
reduce() 函数会对参数序列中元素进行累积。
reduce(function, sequence, initial=None) 函数 可迭代对象 初始值默认问none
res = reduce(index,l1)
print(res) # 66
res = reduce(lambda x, y: x + y, l1)
print(res) # 66
res = reduce(lambda x, y: x + y, l1, 100)
print(res) # 166

五.常见的内置函数
1.abs() (获取绝对值)
print(abs(-12)) 不考虑正值
print(abs(13)) 不考虑负值
2.all()与any() (判断全部元素的布尔值和true的关系)
l1 = [0, 0, 1, 0, True]
print(all(l1)) # False 数据集中必须所有的元素对应的布尔值为True返回的结果才是True
print(any(l1)) # True 数据集中只要所有的元素对应的布尔值有一个为True 返回的结果就是True
3.bin() oct() hex() 产生对应的进制数
print(bin(100)) # 输出0b1100100 二进制
print(oct(100)) # 输出0o144 十进制
print(hex(100)) # 0x64 十六进制
4.bytes() 类型转换
s = '你好啊 hello world!'
print(s.encode('utf8')) # b'\xe4\xbd\xa0\xe5\xa5\xbd\xe5\x95\x8a hello world!'
print(bytes(s, 'utf8')) # b'\xe4\xbd\xa0\xe5\xa5\xbd\xe5\x95\x8a hello world!'
'''针对编码解码 可以使用关键字encode与decode 也可以使用bytes和str'''
s1 = '天黑了 抓紧进屋吧!!!'
res = bytes(s1, 'utf8') # 编码
res1 = str(res, 'utf8') # 解码
5.callable() 判断当前对象是否可以加括号调用
name = 'jason'
def index():pass
print(callable(name)) # False 变量名不能加括号调用
print(callable(index)) # True 函数名可以加括号调用
6.chr()、ord() 字符与数字的对应转换
print(chr(65)) # A 根据数字转字符 依据ASCII码
print(ord('A')) # 65 根据字符转数字 依据ASCII码
7.dir() 返回数据类型可以调用的内置方法(查看对象内部可调用的属性)
print(dir(123))
print(dir('jason'))
8..divmod() 函数把除数和余数运算结果结合起来,返回一个包含商和余数的元组(a // b, a % b)。
divmod(7, 2)
(3, 1) # 整除为3 余数为1
divmod(8, 2)
(4, 0) # 整除为4 余数为0
9.enumerate() 枚举
seasons = ['Spring', 'Summer', 'Fall', 'Winter']
list(enumerate(seasons)) # 把seasons里的元素和其索引值组成一个元组,以列表的形式传出
[(0, 'Spring'), (1, 'Summer'), (2, 'Fall'), (3, 'Winter')]
list(enumerate(seasons, start=1)) # 下标从 1 开始
[(1, 'Spring'), (2, 'Summer'), (3, 'Fall'), (4, 'Winter')]
10.eval() exec() 识别字符串中的python代码
print('print("有点饿了")') # print("有点饿了")
eval('print("有点饿了111")') # 有点饿了111 只能识别简单逻辑的python代码
exec('print("有点饿了222")') # 有点饿了222 能够识别具有与一定逻辑的python代码


