一.字符编码表的简单介绍
1.字符编码只针对文本文件
二.字符编码发展史介绍
1.一家独大:
首先计算机是美国人发明的,所以一开始就只考虑到了英文字符和数字所对应.
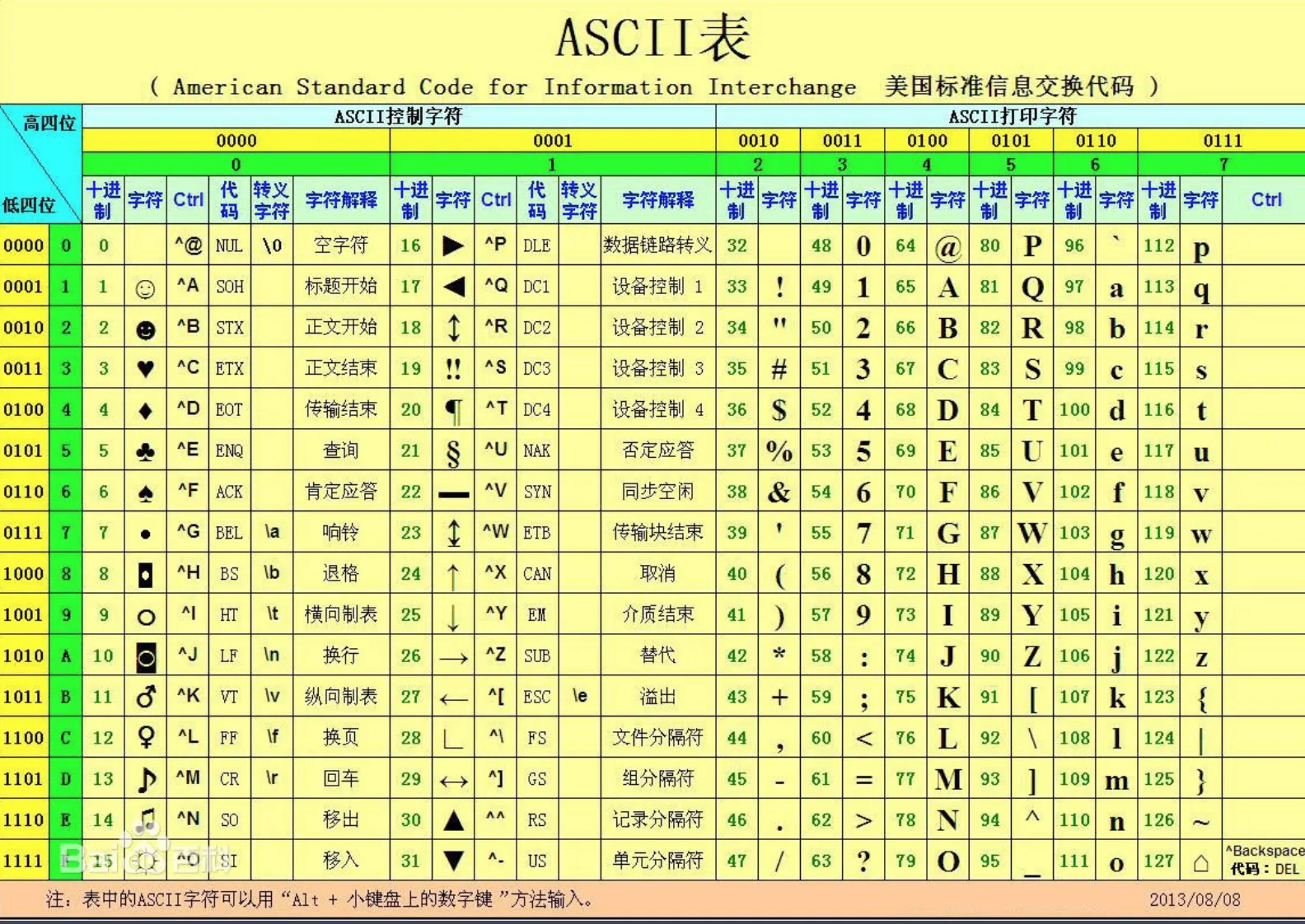
最开始是ASCII码表:用来记录英文和数字所对应关系
1bytes(8beit)来表示英文
A-Z:65-90
a-z:97-122
2.群雄割据:
当计算机风靡其他很多国家的时候,面对了同样的问题因为,因为只有英文和数字所对应的关系所以各个国家都开始编写字符编码表
中国:GBK
日本:shift_Jis
韩国:Euc_kr
"""所有不同国家或者类型编码表他跨国翻译只能编程乱码形式"""
3.天下统一
慢慢随着科技的发展所以计算机也跟着发展跨国贸易等交易开始陆续进行但是因为编码表的不同往往会出现乱码形式,这时候出现了统一形式的编码表:
uniccode:称为:万国码
同时还修改了字符储存空间
utf8:转换版本:万国码
同样也修改了字符储存空间
"""我们使用的计算机内存用的通常是unicode通用的万国码
但是我们的硬盘使用的是utf8转换版"""

三.字符编码应用
1.编码:将人类能读懂的字符编码编译成计算机可以直接读懂的字符编码
2.解码:将计算机能够直接读懂的字符编码解释成人类可以读懂的字符编码
"""我们输入的是字符计算机眼里其实就都是二进制的数字通过组合拼接才能显示, 同样的道理计算机把一串二进制的数字组合拼接然后翻译成人类可以看懂的字符"""
3.乱码:在正常显示和非正常显示的数据,你用的是编码就要用对应的解码即可
"""
--python解释器层面:
1.在python2中:解释器默认的编码是ASCII码因为那时候还没有万国码.所以要在他文件的最上方标注# coding:utf8来进行一个编码的转换
2.在python3中:解释器不用编码转换因为默认为:utf8
"""
四.文件操作简单介绍
1.文件的概念:
什么是文件:其实就是操作系统暴漏给用户可以直接操作硬盘的快捷方式
2.操作流程:
2.1打开.创建 2.2编辑文件的内容 2.3保存文件 2.4关闭文件
3.文件的基本语法结构:
结构1. f1 = open()
f1.close()
结构2. wist open() as f:
...{...和pass语法结构是相同的可以运行但是内部什么都没有}
# open(r'a.txt') 相对路径[根据地址来找数据] (r.去除特殊所包含的含义)
# open(r'D:\pathon\a.txt') 绝对路径[不用根据地址可以直接找到数据]
# l1 = open(r'a,txt''r',encoding='utf8')
open:(文件的路径)
r:(文件的操作模式)
encoding:(编码的形式)
utf8:(转化版本的万国码)
因为close是结束所以在python中可以:
# With open(r'a,txt''r',encoding='utf8')as:f
data = f.rean
print(data)
五.文件的读写功能
r = read :只能模式:只读不能写
w = write :只能写模式:只写不能读
a = append :只追加模式:在文件末尾追加新的内容
r模式结构:
路径不存在:直接报错
路径存在:正常打开后读取相应的内容
w模式结构:
路径不存在:自动创建新的文件
路径存在:会清空文件内所有内容然后从新写入
a模式结构:
路径不存在:自动创建新的文件
路径存在:他就不会清空文件内容只能在末尾追加你写的新内容
六.文件操作模式
文本模式是默认模式
r rt
w wt
a at
t模式:
1.该模式只能操作文本文件
2.该模式必须有encoding(编码)参数
3.该模式读写都是以字符串为最小单位
b模式:
默认为二进制模式
r rb
w wb
a ab
B模式:
1.该模式可以操作任何数据类型文件(任何)
2.该模式不需要encoding(编码)为参数
3.该模式读写都以bytes(比特位也就是而二进制0101)类型为最小单位
七.文件的内置方法
1.read() # 一次性读取完内容
2.readline() # 一次只读取一行内容
3.readlines() # 判断当前文件是否可读
"""注:read缺点如果一次性读取完毕那么如果数据较多那么可以会对内存产生影响但是一次一行又显的太慢所以支持用for循环来读取内容:for循环:for 变量名 in 数据 分别提出文件里的元素一行一行显示并且能一次性读完还不出现溢出等问题"""
4.write() # 写入文件内容
5.writelines() # 可以将列表中的多个元素写入文件内
6.writable() # 判断文件是否可以写入
7.flush() # 保存


