消息中间件相关面试题
1、什么是消息中间件?
是利用高效可靠的消息传递机制进行异步的数据传输,并基于数据通信进行分布式系统的集成。通过提供消息队列模型和消息传递机制,可以在分布式环境下扩展进程间的通信。
2、为什么要使用消息中间件?
系统解耦:使用消息队列来作为两个系统的通讯方式。两个系统不需要相互依赖,实现解耦。
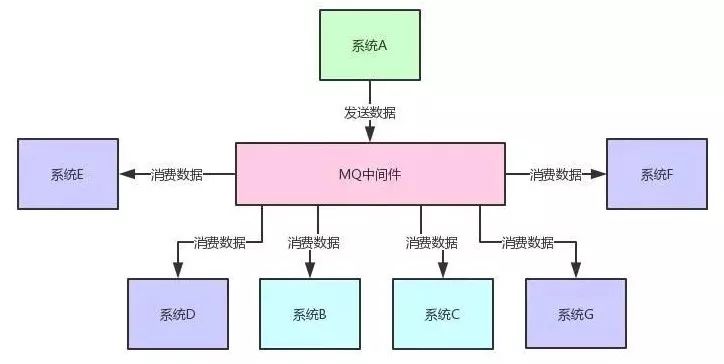
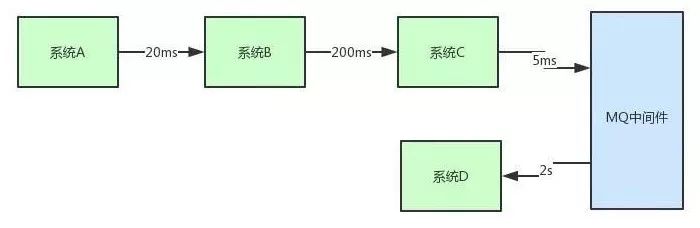
异步调用:系统C给消息队列发送消息后,可以非阻塞执行其他任务。

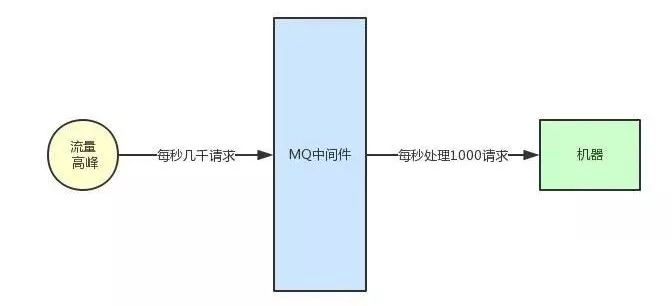
流量削峰:高峰期积压一些请求在MQ里,然后高峰期过了,由消费者自己控制消费速度,在一定时间内消费完毕
3、消息中间件有哪些传递模式?
消息中间件一般有两种传递模式:
点对点模式:一对一,消息生产者将消息发送到消息队列中,消息消费者从队列中接收消息。消息可以在消息队列中进行异步传输。
发布/订阅模式:一对多,通过一个内容节点(主题topic)来发布和订阅消息,消息发布者将消息发布到某个主题,消息订阅者订阅这个主题的消息。消息的发布与订阅相互独立。
4、如何保证消息不被重复消费?
Kafka内部:在每个 MQ 写入队列时,会给这条数据分配一个序号 offset,消费者在消费数据时,会把消费过的 offset序号 提交,下次从大于提交序号的最小数据开始消费。
5、Kafka的rebalance机制是什么?
消费者分区分配策略:轮询分区、Sticky策略、Range范围分区(默认)
什么时候会触发?
只要数据量发生变化的时候,就会触发rebalance机制。组员个数发生变化、订阅topic个数发生变化、订阅topic分区数发生变化
Kafka是pull?push?以及优劣势分析
Kafka遵循传统设计:producer将消息推送到broker,consumer从broker拉取消息
kafka选取传统pull模式,push模式下当producer推送的速率远大于consumer消费的速率时,consumer可能崩溃且pull模式下如果broker没有可供消息的信息,导致consumer不断在循环中轮询,直到消息到达。其次,pull模式下的consumer可以自主决定是否批量从broker拉取数据。
Kafka消息丢失的场景有哪些?
生产者在生产过程中的消息丢失。ACK=0,producer发送一次就不发送了,不管是否发送成功。
broker在故障后的消息丢失。ACK=1(默认),吞吐量与可靠性的一个折中方案。
消费者在消费过程中的消息丢失。ACK=-1,生产和存储不会丢失数据,(消费丢失)
ACK机制为1、0、-1
OFFset机制:kafka消费者的三种消费语义
at-most-once:最多一次(可能丢数据?)
at-least-once:最少一次(可能重复消费数据+)
exact-once message:精确一次 1
kafka中zookeeper的作用是什么?
zookeeper是分布式协调,不是数据库。
kafka使用zookeeper的分布式锁和分布式配置及统一命名的分布式协调解决方案
kafka的broker集群中的controller的选择,是通过zookeeper的临时节点争抢获得的。
kafka中broker中的状态数据存储在zookeeper中,zookeeper不是数据库,存储的属于元数据。
kafka中高性能如何保障?
性能的最大瓶颈是IO,broker持久化数据时使用磁盘顺序读写,再进一步优化就是0拷贝的使用(从磁盘日志到消费者客户端的数据传递),分布式系统做tradeoff,速度与可用性/可靠性
6、RabbitMq的架构设计?
是单机的mq组件。是AMQP的实现。
Broker:提供一种传输服务,角色就是维护生产者到消费者的路线,保证数据能安装指定的方式进行传输。
Exchange:消息交换机,指定消息按什么规则,路由到那个队列。
Queue:消息载体,每个消息都会被偷到一个或多个队列
Bindind:绑定,吧exchange和queue按照路由规则绑定起来
RoutingKey:路由关键字,exchange根据关键字消息投递
vhost:虚拟主机,一个broker里有多个vhost,用于不同用户权限分离
Producer:消息生产者,投递消息的程序
Consomer:消息消费者,接受消息的程序
Channel:消息通道,在客户端的每个连接里,可建立多个channel
核心:在mq领域中,producer将msg发送queue,consumer消费queue完成pc接口
kafka由producer决定msg发送到那个queue
rabbitmq由exchange决定msg怎样发送到目标queue,这就是bingding及对应的策略。
7、RabbitMq的事务消息原理?
有事务、确认。确认是对一件事的确认,事务是对批量的确认。增删改查中,事务是对于增删改的保证。
发送方事务:开启事务,发送多条数据,事务提交|回滚是原子性的,要么都提交,要么都回滚
消费方事务:消费方是读取行为,ACK是要手动提交,最终确定以事务的提交|回滚决定。
8、RabbitMq的如何保证消息发送和消息接收?
消息发送确认:ConfirmCallback方法,消息发送到broker后回调,确认消息是否到达broker服务器(确认是否到达exchange)
returnCallBack方法,失败返回,路由不到队列时回调(可以不用,交换机和队列在代码里绑定)
消息确认模式:自动确认、根据情况确认、手动确认
消息接收确认:消息确认机制(ACK)默认自动确认,发送给消费者后立即确认,但存在丢失消息的可能,若消费端抛异常,回滚只保证数据的一致性,消息还是丢失。即没有成功处理就丢失。
消息确认模式:确认当前信息、否定当前信息、拒绝当前信息
9、RabbitMq的死信队列、延时队列是如何实现的?
DLX,死信交换机。
死信队列:当队列中消息被拒绝、过期会变成死信,死信可以被重新发布到另一个交换机,这个交换机就是死信队列。
原因:信息被拒接、过期、超时、超过子队列的最大长度
死信队列中,可以为普通交换器绑定多个消息队列,假设绑定过期时间为5分钟、10分钟和30分钟,3个消息队列,每个队列设置DLX,并关联一个死信队列。过期后的消息转存死信队列,投递指定消费者消费。
设置过期消息的两种方式:①x-message-ttl,所有消息相同过期时间;②expiration属性,每条消息过期时间不同,以过期时间小的为准。
消息到达过期时间没有被消费,消息就变成死信消息。
延迟队列:存储延迟消息。消息发布后,指定时间之后再投递消费者。如订单30s内付款,超时后偷掉消费者处理超时订单。
rabbitMQ没有直接支持延迟队列,可以通过死信队列实现。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号