Redis
一、什么是Redis,为什么要使用Redis
用户的个人信息,社交网络,地理位置。用户自己产生的数据,用户日志等等爆发式增长!这时候我们就需要使用NoSQL数据库的,Nosql可以很好的处理以上的情况!
1、什么是Redis?
Redis( Remote Dictionary Server )远程字典服务,也叫结构化数据库。是nosql(Not Only Sql)非关系型数据库。
有问题:mysql等关系型数据库RDBMS很难对付web2.0时代,尤其是超大规模高并发的网站!暴露出很多难以克服的问题!
数量大,变化快!mysql存一些比较大的文件,博客,图片!数据量大,效率低!
2、传统的RDBMS与Nosql对比
传统的RDBMS
结构化组织
sql
数据和关系都存在单独的表中 row col
操作,数据定义语言
严格的一致性
基础的事务
Nosql
不仅仅是数据
没有固定的查询语言
键值对存储,列存储,文档存储,图形数据库(社交关系)
最终一致性
CAP定立和BASE理论(异地多活!)--初级架构师!(只要学不死,就往死里学!!!)
高性能、高可用、高可扩展
3.Nosql四大分类
k-v键值对
新浪:【Redis】
美团:Redis+Tair
阿里、百度:Redis+Memecache
文档型数据库(bson格式和json一样)
【MongoDB】(一般必须要掌握)
基于分布式文件存储的数据库,C++编写,主要用来处理大量的文档!
MongoDB是一个介于关系型数据库和非关系型数据库的交集
非关系型数据库功能最丰富的且最像关系型数据库
ConthDB
列存储数据库
【HBase】
分布式文件系统
图关系数据库--存的不是图形,是关系!如:朋友圈社交网络,广告推荐!
【Neo4j】、InfoGrid
二、Redis安装与使用
1.Windows安装
下载地址: https://github.com/MicrosoftArchive/redis/releases
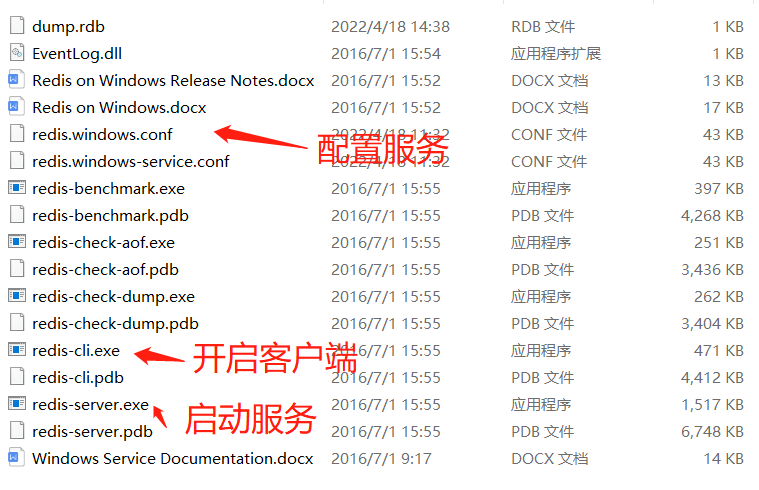
2.linux安装:
下载安装包!redis-5.0.8.tar.gz
解压Redis的安装包!程序一般放在 /opt 目录下

基本环境安装
yum install gcc-c++
# 然后进入redis目录下执行
make
# 然后执行
make install
redis默认安装路径 /usr/local/bin

将redis的配置文件复制到 程序安装目录 /usr/local/bin/kconfig下
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-hxvGQ47d-1597890996509)(狂神说 Redis.assets/image-20200813114000868.png)]](https://img-blog.csdnimg.cn/20200820104157817.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L0RERERlbmdf,size_16,color_FFFFFF,t_70#pic_center)
redis默认不是后台启动的,需要修改配置文件!

通过制定的配置文件启动redis服务
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-jOypL57Z-1597890996511)(狂神说 Redis.assets/image-20200813114030597.png)]](https://img-blog.csdnimg.cn/20200820104228556.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L0RERERlbmdf,size_16,color_FFFFFF,t_70#pic_center)
使用redis-cli连接指定的端口号测试,Redis的默认端口6379
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-LnDaISQ4-1597890996512)(狂神说 Redis.assets/image-20200813114045299.png)]](https://img-blog.csdnimg.cn/20200820104243223.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L0RERERlbmdf,size_16,color_FFFFFF,t_70#pic_center)
查看redis进程是否开启
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-9PhN1jC1-1597890996513)(狂神说 Redis.assets/image-20200813114103769.png)]](https://img-blog.csdnimg.cn/20200820104300532.png#pic_center)
关闭Redis服务 shutdown
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Y54EuOYm-1597890996514)(狂神说 Redis.assets/image-20200813114116691.png)]](https://img-blog.csdnimg.cn/20200820104314297.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L0RERERlbmdf,size_16,color_FFFFFF,t_70#pic_center)
再次查看进程是否存在
三.Redis常用命令
redis默认16个,默认使用第0个,通过select 3来切换其他数据库
ping #测试是否连接成功
redis-server kconfig/redis.conf #启动redis
redis-cli -p 6379 #客户端连接
dbsize #数据个数
select 15 #选择15号数据库
keys * #查看所有key
# 测试:100个并发连接 100000请求
redis-benchmark -h localhost -p 6379 -c 100 -n 100000
flushdb #清空当前数据库
flushall #清空所有数据库
1、String类型
查看代码
get name
#######字符串常规使用#######
set name zs
get name
exists name
append name zs1 #追加不存在时==set name zs1
keys
#######自增、自减#######
incr 自增
decr 自减
set i 0
incr i #i++
incr i 10 #i+=10
decr i #i--
decr i 10 #i-=10
#######字符串截取、替换#######
getrange #截取字符串
setrange #替换字符串
set key1 "hello,world"
getrange key1 0 3 #截取[0,3]
setrange key1 1 xx #替换指定位置开始的字符串 hxxlo,world
#######设置过期,不存在添加#######
setex #设置过期时间
setnx #不存在在设置(分布式锁常常使用)
setex key3 30 "hello"
ttl keys
get key3
setnx mykey "redis"
setnx mykey "MongoDB" #设置成功返回1,失败返回0
#######存取多值#######
mset
mget
mset k1 v1 k2 v2 k3 v3
msetnx k1 v1 k4 v4 #msetnx原子性操作,全成功或全失败
##对象##
set user:1{name:zhangsan,age:2}
mset user:1:name zs user:1:age 2
#######先取后存#######
getset
getset db redis #如果不存在,返回nil
get db
getset db mondodb #如果存在返回原来的值,并设置新的值
2、List类型(集合:有序可重复。栈、队列、阻塞队列[双向])
查看命令
所有的list命令都是以l开头(默认左边插入)
lrange list22 0 -1 #获取全部list
#######左边插入、右边插入#######
lpush
rpush
lpush list one #将一个值或多个放入集合头部(左)
lpush list two
lpush list three
lrange list 0 -1 #获取全部list
lrange list 0 1 #区间获取值(出栈操作) three two
rpush list zero #将一个值或多个放入集合尾部(右)
#######左边移除、右边移除#######
lpop
rpop
lpop list #左边移除list第1个元素
rpop list #右边移除list第1个元素
lindex list 1 #索引获取第2个值
llen list #返回列表的长度
#######移除指定个数的值 #######
lrem
lrem list 1 one # 移除list中1个one
lrem list 2 one # 移除list中2个one
lrange list 0 -1 #获取全部list
#######截取指定区间的值#######
ltrim
rpush list2 "hello1"
rpush list2 "hello2"
rpush list2 "hello3"
rpush list2 "hello4"
ltrim list2 1 2 #截取[1,2]的值
lrange list 0 -1 #获取全部list
#######截取指定区间的值#######
rpoplpush
rpush list2 "hello1"
rpush list2 "hello2"
rpush list2 "hello3"
rpoplpush list2 list22 #移除最后一个元素移入新列表中("hello3"移入到list22)
lrange list2 0 -1 #获取全部list
lrange list22 0 -1 #获取全部list
#######修改指定位置的值#######
lset
exists list
lpush list "item"
lset list 0 "hello"
lrange list22 0 0 #获取list 0位置的数据
#######某一值的之前或之后插入#######
linsert list3 before
linsert list3 after
lpush list3 "hello"
lpush list3 "world"
linsert list3 before "world" "other"
lrange list22 0 -1 #获取全部list
linsert list3 after "world" "new"
lrange list22 0 -1 #获取全部list
##总结:
1.list实际是一个链表,left、right都可以插入值
2.key不存在,则会创建新的链表
3.key存在,新增内容
4.移除list所有值,list=空链表=不存在!
5.两边插入或改动值,效率最高!中间元素,相对效率低
3、Set类型(集合:不能重复)
查看命令
smembers myset #查看myset所有值
#######set常规操作#######
sadd #set添加
smembers #查看所有
sismember #是否存在值
scard
sadd myset "hello"
sadd myset "world"
smembers myset #查看myset所有值
sismember myset hello #判断hello是不是myset的值?1:0
scard myset #获取值的个数
srem myset hello #移除set集合中指定元素
#######随机抽取、随机删除#######
srandmember myset #随机抽选出1个元素
srandmember myset 2#随机抽选出2个元素
spop myset #随机移除一些set集合中元素
smembers myset #查看myset所有值
flushdb #清空当前数据库
#######跨集合移动元素#######
sadd keyset1 a
sadd keyset1 b
sadd keyset1 c
sadd keyset2 d
smove keyset1 keyset2 c #把keyset1的c移动到keyset2
smembers myset #查看myset所有值
########微博、b战:共同关注、可能认识的朋友(交集)########
sadd keyset1 a
sadd keyset1 b
sadd keyset1 c
sadd keyset2 c
sadd keyset2 d
sdiff keyset1 keyset2 #差集,以keyset1为基准,除去交集
sinter keyset1 keyset2 #交集
sunion keyset1 keyset2 #并集
4、Hash(value等于Map集合) key-Map(k-v)
本质:和String类型没太大区别,还是简单key-value
查看命令
hgetall myhash #获取全部hash的k-v
hkeys myhash #获取hash的所有key
hkeys myhash #获取hash的所有value
#常规使用#
hset myhash k1 v1 #单值存
hget myhash #单值取
hmset myhash k2 v2 k3 v3 #多值存
hmget myhash k2 k3 #多值取
hgetall myhash #获取全部hash的k-v
hlen myhash #获取hash的长度
hexists myhash k1 #判断hash指定字段是否存在?1:0
hkeys myhash #获取hash的所有key
hkeys myhash #获取hash的所有value
########自增、自减########
hset myhash k5 5
hincrby myhash k5 1
hdecrby myhash k5 1
hsetnx myhash k5 hello #k5是否存在?1:0(不存在就新增)
########hash应用########
1.user对象
hset user:1 name zs5、Zset(有序集合)
查看命令
zrange salary 0 -1 #查询所有值
#常规操作#
zadd myzset 1 one #添加单值
zadd myzset 2 two 3 three #添加多值
zrangebyscore myset -inf +inf #升序
zrevrange myset 0 -1 #降序
zrangebyscore myset -inf +inf withscores#附带分数
zrangebyscore myset -inf 2500 #score<2500从小到大排序
zrange salary 0 -1 #查询所有值
zrem salary one #移除one
zrange salary 0 -1 #查询所有值
zcard salary #获取有序集合中个数
zcount myset 1 3 #获取指定区间的成员数量
6、三种特殊数据类型
a.geospatial
查看命令
#规则:两极无法直接添加,一般下载城市数据,通过java程序一次性导入
#参数:key value(维度 经度 名称)
#有效的经度(-180,180);有效的纬度(-85,85)
#geoadd 添加地址位置
geoadd china:city 116.40 39.90 beijing
geoadd ching:city 121.47 31.23 shanghai
geoadd ching:city 106.50 29.53 chongqing 144.05 22.52 shenzhen
geoadd ching:city 120.16 30.24 hangzhou 108.96 34.26 xian
geoadd ching:city
#geoadd 获取城市坐标
geopos china:city beijing chongqing #获取指定城市的经度、纬度
#geodist 定位距离(2者)
#km mi(英里) ft(英尺)
geodist china:city beijing shanghai km
#georadius范围查找附近的人
georadius china:cith 110 30 500km #以当前坐标为原点,500km为半径查找范围城市
georadius china:cith 110 30 500km withdist #直线距离
georadius china:cith 110 30 500km withcoord #经纬度
georadiusbymember china:cith beijing 1000km #找出北京1000km的其他城市
#将二维的经纬度转换为一维的字符串(字符串越接近,城市距离越近)
geohash china:city beijing chongqing
##geo底层的实现原理其实就是Zset,可以使用zset命令操作geo
zrange china:city 0 -1
zrem china:city beijing
b.Hyperloglog
Redis HyperLogLog 是用来做基数统计的算法,HyperLogLog 的优点是,在输入元素的数量或者体积非常非常大时,计算基数所需的空间总是固定的、并且是很小的。
花费 12 KB 内存,就可以计算接近 2^64 个不同元素的基数。
因为 HyperLogLog 只会根据输入元素来计算基数,而不会储存输入元素本身,所以 HyperLogLog 不能像集合那样,返回输入的各个元素。
其底层使用string数据类型
什么是基数?
数据集中不重复的元素的个数。
应用场景:
网页的访问量(UV):一个用户多次访问,也只能算作一个人。
传统实现,存储用户的id,然后每次进行比较。当用户变多之后这种方式及其浪费空间,而我们的目的只是计数,Hyperloglog就能帮助我们利用最小的空间完成。

查看命令
----------PFADD--PFCOUNT---------------------
127.0.0.1:6379> PFADD myelemx a b c d e f g h i j k # 添加元素
(integer) 1
127.0.0.1:6379> type myelemx # hyperloglog底层使用String
string
127.0.0.1:6379> PFCOUNT myelemx # 估算myelemx的基数
(integer) 11
127.0.0.1:6379> PFADD myelemy i j k z m c b v p q s
(integer) 1
127.0.0.1:6379> PFCOUNT myelemy
(integer) 11
----------------PFMERGE-----------------------
127.0.0.1:6379> PFMERGE myelemz myelemx myelemy # 合并myelemx和myelemy 成为myelemz
OK
127.0.0.1:6379> PFCOUNT myelemz # 估算基数
(integer) 17如果允许容错,那么一定可以使用Hyperloglog !
如果不允许容错,就使用set或者自己的数据类型即可 !
c.Bitmap
使用位存储,信息状态只有 0 和 1
Bitmap是一串连续的2进制数字(0或1),每一位所在的位置为偏移(offset),在bitmap上可执行AND,OR,XOR,NOT以及其它位操作。
应用场景
签到统计、状态统计

查看命令
------------setbit--getbit--------------
127.0.0.1:6379> setbit sign 0 1 # 设置sign的第0位为 1
(integer) 0
127.0.0.1:6379> setbit sign 2 1 # 设置sign的第2位为 1 不设置默认 是0
(integer) 0
127.0.0.1:6379> setbit sign 3 1
(integer) 0
127.0.0.1:6379> setbit sign 5 1
(integer) 0
127.0.0.1:6379> type sign
string
127.0.0.1:6379> getbit sign 2 # 获取第2位的数值
(integer) 1
127.0.0.1:6379> getbit sign 3
(integer) 1
127.0.0.1:6379> getbit sign 4 # 未设置默认是0
(integer) 0
-----------bitcount----------------------------
127.0.0.1:6379> BITCOUNT sign # 统计sign中为1的位数
(integer) 4[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-9PlszjhS-1597890996519)(D:\我\MyBlog\狂神说 Redis.assets\image-20200803234336175.png)]
这样设置以后你能get到的值是:\xA2\x80,所以bitmaps是一串从左到右的二进制串
四、Redis基本的事务操作
Redis单条命令是保证原子性的,但是事务不保证原子性!
Redis事务本质:一组命令的集合!
1、Redis的事务:
- 开启事务(
multi) - 命令入队
- 执行事务(
exec)
所以事务中的命令在加入时都没有被执行,直到提交时才会开始执行(Exec)一次性完成。
multi #开启事务
#命令入队
set k1 v1
set k2 v2
get k2
set k3 v3
exec | discard #执行命令 |#取消事务 注意:2种异常(1.运行失败,语法错误 2.运行中异常,异常报错,后面依然会正常执行)
2、Redis监控->watch
悲观锁:什么时候都会出问题,做什么都会加锁!
乐观锁:什么时候都不会出问题,不会上锁。更新数据的时候判断一下,在此期间是否有人修改这个额数据(Redis可以当乐观锁)
#声明参数
set money 100 #余额
set out 0 #消费
#监视money
watch money
#Redis事务三部曲
multi #1.开启事务
#2.命令入队
decrby money 20 #余额-20
incrby out 20 #消费+20
#3.执行命令
exec #执行之前,另一个线程修改了money的值,导致事务失败
unwatch #解锁
watch money #获取最新的值 == select version
exec五、Jedis工具封装及整合SpringBoot
1.导入依赖
https://mvnrepository.com/
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>3.2.0</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.62</version>
</dependency>2.测试
查看代码
Jedis jedis = new Jedis("192.168.30.120",6379);
jedis.auth("a@1nercita");//指定密码
jedis.ping();
// test1(jedis);
JSONObject jsonObject = new JSONObject();
jsonObject.put("hello","world");
jsonObject.put("name","wu");
//开启事务
Transaction multi = jedis.multi();
String res = jsonObject.toJSONString();
//开启乐观锁
jedis.watch(res);
try {
multi.set("user1",res);
multi.set("user2",res);
int i = 1/0;//抛异常执行失败
multi.exec();//执行事务
} catch (Exception e) {
multi.discard();//放弃事务
e.printStackTrace();
} finally {
jedis.get("user1");
jedis.get("user2");
jedis.close();
}3.整合SpringBoot
1.导入依赖 #底层连接jedis->lettuce
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>#jedis:采用的直连,多个线程操作不安全
#lettuce:采用netty,实例可以在多个线程中进行共享,不存在线程不安全的情况
2.配置文件
定义了一个RedisTemplate存储对象
@Configuration
public class RedisConfig {
/*
自己定义了一个RedisTemplate
<bean id="redisTemplate" class="RedisTemplate">
*/
@Bean
public RedisTemplate<String, Object> redisTemplate(RedisConnectionFactory factory) throws UnknownHostException {
//为了自己开发方便,一般使用<String, Object>
RedisTemplate<String, Object> template = new RedisTemplate();
template.setConnectionFactory(factory);
//序列化配置
Jackson2JsonRedisSerializer jackson2JsonRedisSerializer = new Jackson2JsonRedisSerializer(Object.class);
ObjectMapper om = new ObjectMapper(); //转义
om.setVisibility(PropertyAccessor.ALL, JsonAutoDetect.Visibility.ANY);
om.enableDefaultTyping(ObjectMapper.DefaultTyping.NON_FINAL);
om.activateDefaultTyping(LaissezFaireSubTypeValidator.instance,ObjectMapper.DefaultTyping.NON_FINAL, JsonTypeInfo.As.PROPERTY);
jackson2JsonRedisSerializer.setObjectMapper(om);
//String 序列化
StringRedisSerializer stringRedisSerializer = new StringRedisSerializer();
//key采用string的序列化
template.setKeySerializer(stringRedisSerializer);
//hash的key采用string序列化
template.setHashKeySerializer(stringRedisSerializer);
//value序列化方式采用jackson
template.setValueSerializer(jackson2JsonRedisSerializer);
//hash的value序列化采用
template.setHashKeySerializer(jackson2JsonRedisSerializer);
template.afterPropertiesSet();
return template;
}
}3.工具类包装
RedisUtil
@Component
public final class RedisUtil {
@Autowired
private RedisTemplate<String, Object> redisTemplate;
// =============================common============================
/**
* 指定缓存失效时间
* @param key 键
* @param time 时间(秒)
*/
public boolean expire(String key, long time) {
try {
if (time > 0) {
redisTemplate.expire(key, time, TimeUnit.SECONDS);
}
return true;
} catch (Exception e) {
e.printStackTrace();
return false;
}
}
/**
* 根据key 获取过期时间
* @param key 键 不能为null
* @return 时间(秒) 返回0代表为永久有效
*/
public long getExpire(String key) {
return redisTemplate.getExpire(key, TimeUnit.SECONDS);
}
/**
* 判断key是否存在
* @param key 键
* @return true 存在 false不存在
*/
public boolean hasKey(String key) {
try {
return redisTemplate.hasKey(key);
} catch (Exception e) {
e.printStackTrace();
return false;
}
}
/**
* 删除缓存
* @param key 可以传一个值 或多个
*/
@SuppressWarnings("unchecked")
public void del(String... key) {
if (key != null && key.length > 0) {
if (key.length == 1) {
redisTemplate.delete(key[0]);
} else {
redisTemplate.delete((Collection<String>) CollectionUtils.arrayToList(key));
}
}
}
// ============================String=============================
/**
* 普通缓存获取
* @param key 键
* @return 值
*/
public Object get(String key) {
return key == null ? null : redisTemplate.opsForValue().get(key);
}
/**
* 普通缓存放入
* @param key 键
* @param value 值
* @return true成功 false失败
*/
public boolean set(String key, Object value) {
try {
redisTemplate.opsForValue().set(key, value);
return true;
} catch (Exception e) {
e.printStackTrace();
return false;
}
}
/**
* 普通缓存放入并设置时间
* @param key 键
* @param value 值
* @param time 时间(秒) time要大于0 如果time小于等于0 将设置无限期
* @return true成功 false 失败
*/
public boolean set(String key, Object value, long time) {
try {
if (time > 0) {
redisTemplate.opsForValue().set(key, value, time, TimeUnit.SECONDS);
} else {
set(key, value);
}
return true;
} catch (Exception e) {
e.printStackTrace();
return false;
}
}
/**
* 递增
* @param key 键
* @param delta 要增加几(大于0)
*/
public long incr(String key, long delta) {
if (delta < 0) {
throw new RuntimeException("递增因子必须大于0");
}
return redisTemplate.opsForValue().increment(key, delta);
}
/**
* 递减
* @param key 键
* @param delta 要减少几(小于0)
*/
public long decr(String key, long delta) {
if (delta < 0) {
throw new RuntimeException("递减因子必须大于0");
}
return redisTemplate.opsForValue().increment(key, -delta);
}
// ================================Map=================================
/**
* HashGet
* @param key 键 不能为null
* @param item 项 不能为null
*/
public Object hget(String key, String item) {
return redisTemplate.opsForHash().get(key, item);
}
/**
* 获取hashKey对应的所有键值
* @param key 键
* @return 对应的多个键值
*/
public Map<Object, Object> hmget(String key) {
return redisTemplate.opsForHash().entries(key);
}
/**
* HashSet
* @param key 键
* @param map 对应多个键值
*/
public boolean hmset(String key, Map<String, Object> map) {
try {
redisTemplate.opsForHash().putAll(key, map);
return true;
} catch (Exception e) {
e.printStackTrace();
return false;
}
}
/**
* HashSet 并设置时间
* @param key 键
* @param map 对应多个键值
* @param time 时间(秒)
* @return true成功 false失败
*/
public boolean hmset(String key, Map<String, Object> map, long time) {
try {
redisTemplate.opsForHash().putAll(key, map);
if (time > 0) {
expire(key, time);
}
return true;
} catch (Exception e) {
e.printStackTrace();
return false;
}
}
/**
* 向一张hash表中放入数据,如果不存在将创建
*
* @param key 键
* @param item 项
* @param value 值
* @return true 成功 false失败
*/
public boolean hset(String key, String item, Object value) {
try {
redisTemplate.opsForHash().put(key, item, value);
return true;
} catch (Exception e) {
e.printStackTrace();
return false;
}
}
/**
* 向一张hash表中放入数据,如果不存在将创建
*
* @param key 键
* @param item 项
* @param value 值
* @param time 时间(秒) 注意:如果已存在的hash表有时间,这里将会替换原有的时间
* @return true 成功 false失败
*/
public boolean hset(String key, String item, Object value, long time) {
try {
redisTemplate.opsForHash().put(key, item, value);
if (time > 0) {
expire(key, time);
}
return true;
} catch (Exception e) {
e.printStackTrace();
return false;
}
}
/**
* 删除hash表中的值
*
* @param key 键 不能为null
* @param item 项 可以使多个 不能为null
*/
public void hdel(String key, Object... item) {
redisTemplate.opsForHash().delete(key, item);
}
/**
* 判断hash表中是否有该项的值
*
* @param key 键 不能为null
* @param item 项 不能为null
* @return true 存在 false不存在
*/
public boolean hHasKey(String key, String item) {
return redisTemplate.opsForHash().hasKey(key, item);
}
/**
* hash递增 如果不存在,就会创建一个 并把新增后的值返回
*
* @param key 键
* @param item 项
* @param by 要增加几(大于0)
*/
public double hincr(String key, String item, double by) {
return redisTemplate.opsForHash().increment(key, item, by);
}
/**
* hash递减
*
* @param key 键
* @param item 项
* @param by 要减少记(小于0)
*/
public double hdecr(String key, String item, double by) {
return redisTemplate.opsForHash().increment(key, item, -by);
}
// ============================set=============================
/**
* 根据key获取Set中的所有值
* @param key 键
*/
public Set<Object> sGet(String key) {
try {
return redisTemplate.opsForSet().members(key);
} catch (Exception e) {
e.printStackTrace();
return null;
}
}
/**
* 根据value从一个set中查询,是否存在
*
* @param key 键
* @param value 值
* @return true 存在 false不存在
*/
public boolean sHasKey(String key, Object value) {
try {
return redisTemplate.opsForSet().isMember(key, value);
} catch (Exception e) {
e.printStackTrace();
return false;
}
}
/**
* 将数据放入set缓存
*
* @param key 键
* @param values 值 可以是多个
* @return 成功个数
*/
public long sSet(String key, Object... values) {
try {
return redisTemplate.opsForSet().add(key, values);
} catch (Exception e) {
e.printStackTrace();
return 0;
}
}
/**
* 将set数据放入缓存
*
* @param key 键
* @param time 时间(秒)
* @param values 值 可以是多个
* @return 成功个数
*/
public long sSetAndTime(String key, long time, Object... values) {
try {
Long count = redisTemplate.opsForSet().add(key, values);
if (time > 0)
expire(key, time);
return count;
} catch (Exception e) {
e.printStackTrace();
return 0;
}
}
/**
* 获取set缓存的长度
*
* @param key 键
*/
public long sGetSetSize(String key) {
try {
return redisTemplate.opsForSet().size(key);
} catch (Exception e) {
e.printStackTrace();
return 0;
}
}
/**
* 移除值为value的
*
* @param key 键
* @param values 值 可以是多个
* @return 移除的个数
*/
public long setRemove(String key, Object... values) {
try {
Long count = redisTemplate.opsForSet().remove(key, values);
return count;
} catch (Exception e) {
e.printStackTrace();
return 0;
}
}
// ===============================list=================================
/**
* 获取list缓存的内容
*
* @param key 键
* @param start 开始
* @param end 结束 0 到 -1代表所有值
*/
public List<Object> lGet(String key, long start, long end) {
try {
return redisTemplate.opsForList().range(key, start, end);
} catch (Exception e) {
e.printStackTrace();
return null;
}
}
/**
* 获取list缓存的长度
*
* @param key 键
*/
public long lGetListSize(String key) {
try {
return redisTemplate.opsForList().size(key);
} catch (Exception e) {
e.printStackTrace();
return 0;
}
}
/**
* 通过索引 获取list中的值
*
* @param key 键
* @param index 索引 index>=0时, 0 表头,1 第二个元素,依次类推;index<0时,-1,表尾,-2倒数第二个元素,依次类推
*/
public Object lGetIndex(String key, long index) {
try {
return redisTemplate.opsForList().index(key, index);
} catch (Exception e) {
e.printStackTrace();
return null;
}
}
/**
* 将list放入缓存
*
* @param key 键
* @param value 值
*/
public boolean lSet(String key, Object value) {
try {
redisTemplate.opsForList().rightPush(key, value);
return true;
} catch (Exception e) {
e.printStackTrace();
return false;
}
}
/**
* 将list放入缓存
* @param key 键
* @param value 值
* @param time 时间(秒)
*/
public boolean lSet(String key, Object value, long time) {
try {
redisTemplate.opsForList().rightPush(key, value);
if (time > 0)
expire(key, time);
return true;
} catch (Exception e) {
e.printStackTrace();
return false;
}
}
/**
* 将list放入缓存
*
* @param key 键
* @param value 值
* @return
*/
public boolean lSet(String key, List<Object> value) {
try {
redisTemplate.opsForList().rightPushAll(key, value);
return true;
} catch (Exception e) {
e.printStackTrace();
return false;
}
}
/**
* 将list放入缓存
*
* @param key 键
* @param value 值
* @param time 时间(秒)
* @return
*/
public boolean lSet(String key, List<Object> value, long time) {
try {
redisTemplate.opsForList().rightPushAll(key, value);
if (time > 0)
expire(key, time);
return true;
} catch (Exception e) {
e.printStackTrace();
return false;
}
}
/**
* 根据索引修改list中的某条数据
*
* @param key 键
* @param index 索引
* @param value 值
* @return
*/
public boolean lUpdateIndex(String key, long index, Object value) {
try {
redisTemplate.opsForList().set(key, index, value);
return true;
} catch (Exception e) {
e.printStackTrace();
return false;
}
}
/**
* 移除N个值为value
*
* @param key 键
* @param count 移除多少个
* @param value 值
* @return 移除的个数
*/
public long lRemove(String key, long count, Object value) {
try {
Long remove = redisTemplate.opsForList().remove(key, count, value);
return remove;
} catch (Exception e) {
e.printStackTrace();
return 0;
}
}
}4.测试
传递带汉字的对象
//真实的开发都适用json来传递对象
User user = new User("吴中生", 3);
// String jsonUser = new ObjectMapper().writeValueAsString(user);
redisTemplate.opsForValue().set("user",user);
System.out.println(redisTemplate.opsForValue().get("user"));五、Redis Config配置
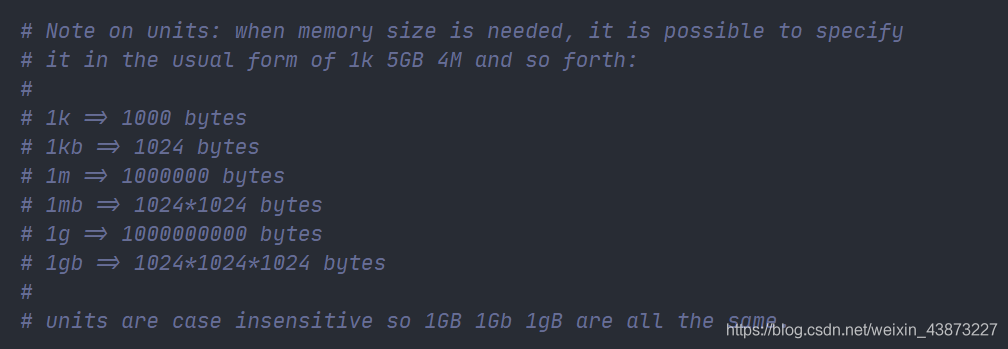
1.配置文件的容量单位不区分大小写
![img]()
2.包含,其他conf配置文件
# include .\path\to\local.conf
# include c:\path\to\other.conf
3.网络配置
bind 127.0.0.1
protected-mode yes #保护模式
port 6379 #端口设置
4.General 通用配置
daemonize yes #以守护进程的方式运行,默认no,我们需要自己开启为yes!
pidfile /var/run/redis_6379.pid #如果以后台的方试运行,我们就需要指定一个pid文件!
loglevel notice
logfile "" #日志的文件位置名
databases 16 #数据库的数量,默认16个
always-show-logo yes #是否总是显示LOGO
5-1.SNAPSHOTTING 快照 -->rdb(Redis DataBase)
持久化,在规定时间内,执行了多少次操作, 则会持久化到文件 rdb.aof
redis是内存数据库,如果没有持久化,那么数据断电及失!
## 若900s(15min)内,如果至少有1个key进行了修改,则进行持久化操作
save 900 1
## 若300s(5min)内,如果至少有10个key进行了修改,则进行持久化操作
save 300 10
## 若60s(1min)内,如果至少有10000个key进行了修改,则进行持久化操作
save 60 10000
stop-writes-on-bgsave-error yes #持久化如果出错,是否需要继续工作
rdbcompression yes #是否压缩rdb文件,需要消耗一些cpu资源
rdbchecksum yes #保存rdb文件时,进行错误的检查校验
dir ./ #rdn文件保存的目录
dbfilename dump.rdb #rdb文件的名字
5-2.append only File模式--> aof配置
appendonly no #默认不开启aof,默认采用rdb方式持久化,大部分情况下rdb管够
appendfilename "appendonly.aof" #持久化文件名字
appendfsync everysec #每秒执行一次,可能会丢失1s数据! 默认
appendfsync no #不执行sync,速度最快,操作系统自己同步数据
appendfsync always #每次执行命令都会修改sync,消耗性能
6.Replication 复制(主从复制)
slaveof 127.0.0.1 6379 #从机认主机
masterauth 123456 #主机密码
主机:可以写,主机所有信息和数据都会自动被从机保存!
从机:可以读,不能写
7.SECURITY 安全
config set requirepass "123456" #设置密码(命令)
config set requirepass "" #不设置密码(命令)
auth 123456 #使用密码进行登录
config get requirepass #获取密码
requirepass 123456 #设置密码(配置文件配置)#默认没有密码
8.LIMITS 限制(不需配置,了解即可)
maxclients 10000 #设置最大连接的客户端
maxmemory <bytes> #redis 配置最大的内存容量
maxmemory-policy noeviction #内存达到上限之后的处理策略
1.volatile-lru #删除lru算法设置了过期时间的的key
2.allkeys-lru #删除lru算法的所有keys
3.volatile-random #随机删除即将过期的key
4.allkeys-random #随机删除所有keys
5.volatile-ttl #删除即将过期的key
6.noeviction #永远不过期,直接报错
六、Redis 持久化
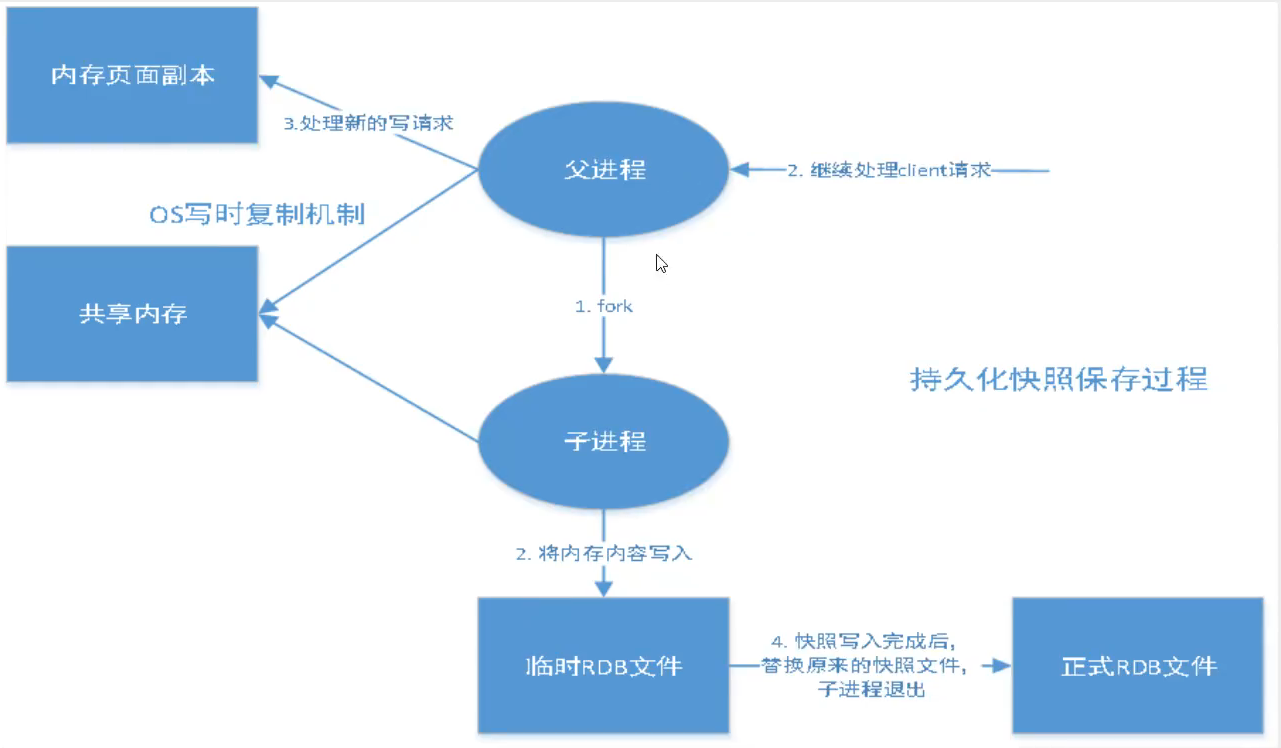
1.rdb
(内存数据库一定要有持久化)--默认:rdb
reids-sever kconfig/redis.conf #启动redis
redis-cli -p 6379 #连接redis
rm -rf dump.rdb 触发机制:自动生成dump.rdb文件
1、save的规则满足的情况下,会自动触发rdb规则
2、执行flushall命令 #默认产生rdb
3、退出redis,也会产生rdb文件!
恢复机制:
1.只需要将rdb放在redis启动目录,redis启动时自动检查dum.rdb恢复其中数据
2.查看需要存在的位置
config get dir -- dir:/usr/local/bin
/usr/local/bin #如果在这个目录下存在dump.rdb文件,启动则会自动恢复其中数据
优缺点:
1.适合大规模的数据恢复!
2.对数据的完整性要求不高!
-3.需要一定的时间间隔进程操作!如果redis意外宕机,这个最后一次修改的数据就丢失了。
-4.fork进程的时候,会占用一定的内存空间
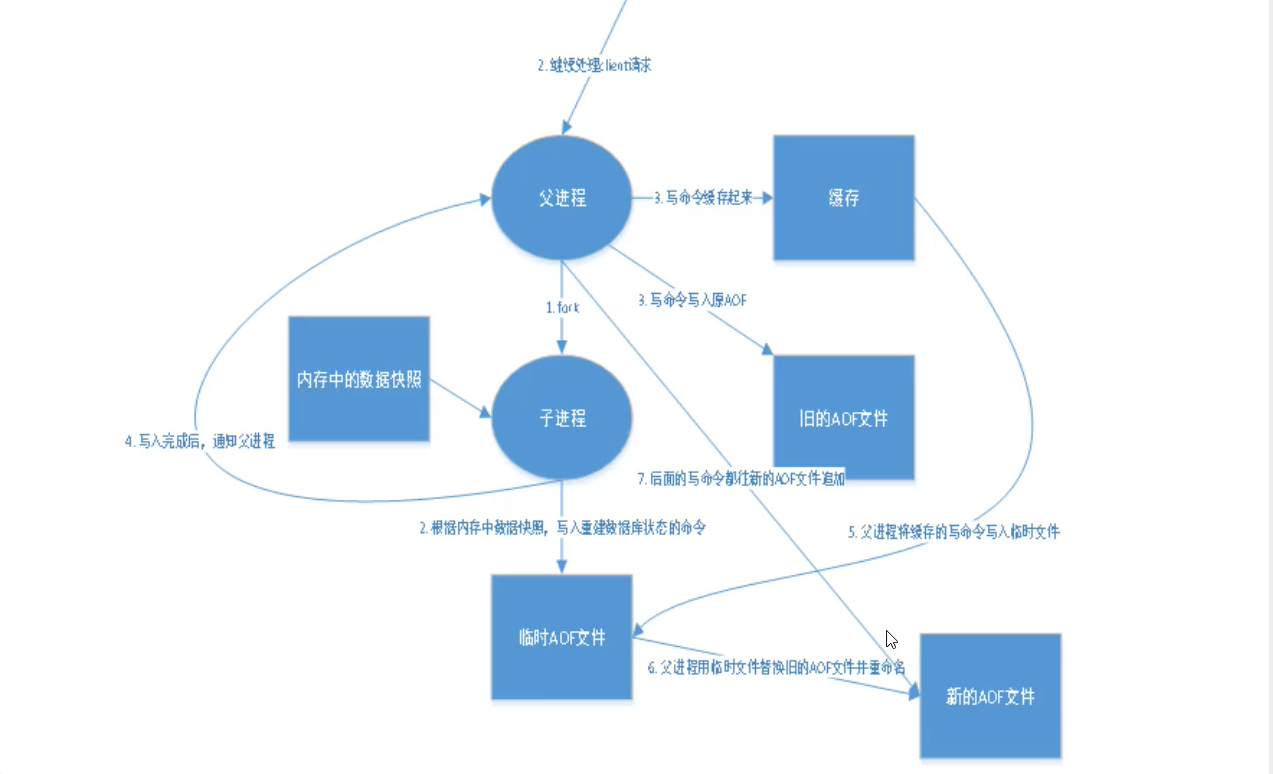
2.aof
appendonly yes #默认不开启,yes开启,其余默认。
appendfilename "appendonly.aof" #持久化文件名字,默认即可
日志级别记录写操作!!!
appendfsync everysec #每秒执行一次,可能会丢失1s数据! 默认
no-appendfsync-on-rewrite no #默认重写规则
重启redis即生效生成 appendonly.aof 文件
vi appendonly.aof #恶意修改,会导致redis服务起不来
redis提供工具 redis-check-aof 修改aof文件
redis-check-aof --fix appendonly.aof
#aof文件上限,一旦超过64M,会fork一个新的进程将文件重写
#aof默认就是文件的无限追加,文件会越来越大
auto-aof-rewrite-percentage 100
auto-aof-rewrite-min-size 64mb
优缺点:
1.没一次修改都东部,文件的完整性会更好!
2.每秒同步一次,可能会丢失1s的数据
3.从不同步,效率最高!
4.相对于数据文件,aof远远大于rdb,修复速度也比rdb慢
5.aof运行效率比rdb慢,所以redis默认就是rdb持久化
3.扩展:
1.只作缓存,如果你只是希望你的数据在服务器运行的时候存在,可以不适用任何持久化
2.性能建议:
rdb用作后背用途,在Slave(从机)上持久化rdb文件,900s备份一次足够
开启aof,最坏的情况只会丢失不超过2s数据,aof重写的基础大小默认64M太小,建议设5G以上
如果不开启aof,仅靠主从复制实现高可用性也可以,省掉大量IO
代价是如果Master/Slave同时倒掉,会丢失十几分钟的数据,启动脚本也要比较两个rdb文件,载入最新
七、Redis发布订阅pub/sub
消息发送者
频道
消息订阅者
查看命令
------------订阅端----------------------
127.0.0.1:6379> SUBSCRIBE sakura # 订阅sakura频道
Reading messages... (press Ctrl-C to quit) # 等待接收消息
1) "subscribe" # 订阅成功的消息
2) "sakura"
3) (integer) 1
1) "message" # 接收到来自sakura频道的消息 "hello world"
2) "sakura"
3) "hello world"
1) "message" # 接收到来自sakura频道的消息 "hello i am sakura"
2) "sakura"
3) "hello i am sakura"
--------------消息发布端-------------------
127.0.0.1:6379> PUBLISH sakura "hello world" # 发布消息到sakura频道
(integer) 1
127.0.0.1:6379> PUBLISH sakura "hello i am sakura" # 发布消息
(integer) 1
-----------------查看活跃的频道------------
127.0.0.1:6379> PUBSUB channels
1) "sakura"原理:每个 Redis 服务器进程都维持着一个表示服务器状态的 redis.h/redisServer 结构, 结构的 pubsub_channels 属性是一个字典, 这个字典就用于保存订阅频道的信息,其中,字典的键为正在被订阅的频道, 而字典的值则是一个链表, 链表中保存了所有订阅这个频道的客户端。
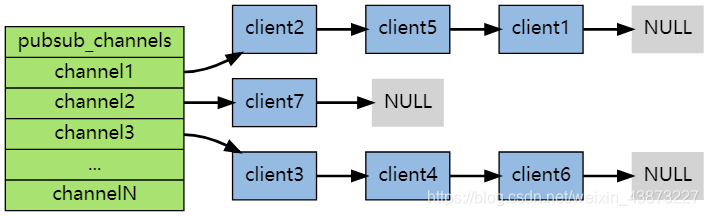
客户端订阅,就被链接到对应频道的链表的尾部,退订则就是将客户端节点从链表中移除。
缺点:
- 如果一个客户端订阅了频道,但自己读取消息的速度却不够快的话,那么不断积压的消息会使redis输出缓冲区的体积变得越来越大,这可能使得redis本身的速度变慢,甚至直接崩溃。
- 这和数据传输可靠性有关,如果在订阅方断线,那么他将会丢失所有在短线期间发布者发布的消息。
应用:
- 消息订阅:公众号订阅,微博关注等等(起始更多是使用消息队列来进行实现)
- 多人在线聊天室。
八、Redis主从复制 --> Redis集群环境搭建
1.什么是主从复制?【必会】
主从复制,是指将一台Redis服务器的数据,复制到其他的Redis服务器。前者称为主节点(Master/Leader),后者称为从节点(Slave/Follower), 数据的复制是单向的!只能由主节点复制到从节点(主节点以写为主、从节点以读为主)。
默认情况下,每台Redis服务器都是主节点,一个主节点可以有0个或者多个从节点,但每个从节点只能由一个主节点。
通过主从复制实现读写分离。主机负责写,从机负责读(不能写)!
Master #默认就是主节点
Slave1
Slave2
Slave3
注意:1.默认就是主节点;
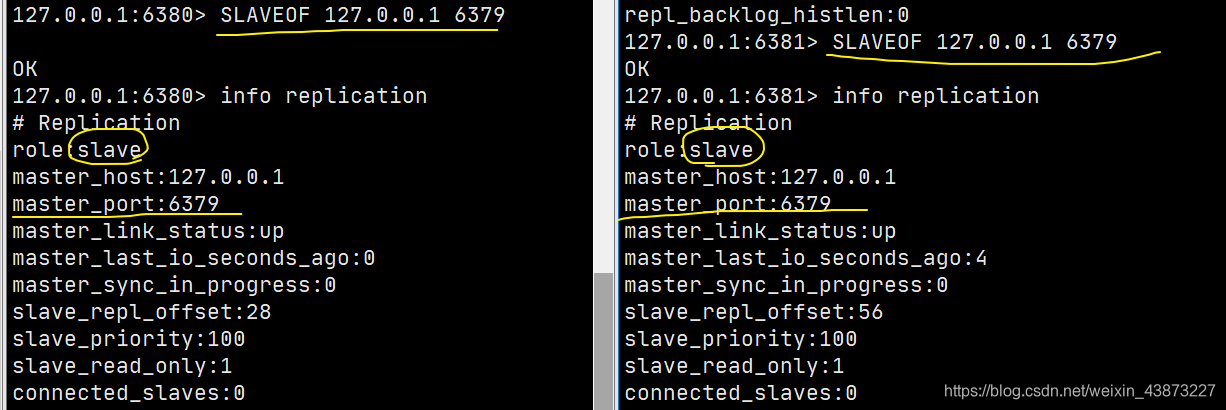
2.需要通过命令才给从机配置主机,1个从机只能有一个主机。【主机有且只能有一个!】
slaveof 127.0.0.1 6379 #从节点配置主节点的ip port
主从复制原理:
【主机有且只能有一个!】
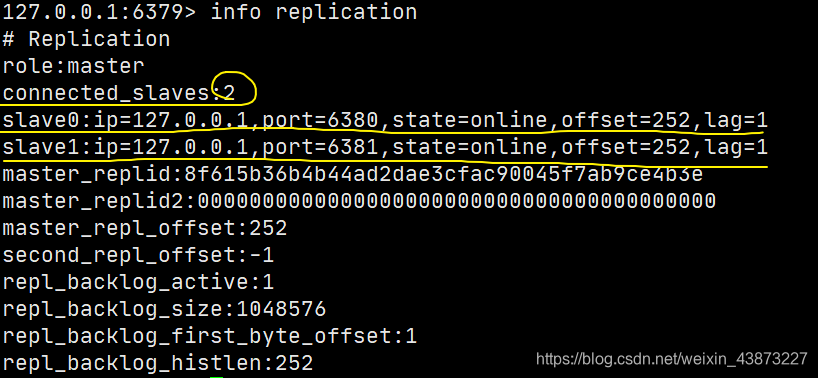
从机Slave启动成功连接到master后会发送一个sync同步命令
主机master收到后,启动后台存盘进程,同时收集所有接收到的用于修改数据集命令,在后台进程执行完毕之后,
master将传送整个数据文件到slave从机,并完成一次完全同步。
全量复制(重新连接主机,一定会全量复制):slave服务在接收到数据库文件数据后,将其存盘并加载到内存中。
增量复制:master继续降新的所有收集到的修改命令依次传给slave,完成同步。
2.有什么作用?
数据冗余:主从复制实现了数据的热备份,是持久化之外的一种数据冗余的方式。
故障恢复:当主节点故障时,从节点可以暂时替代主节点提供服务,是一种服务冗余的方式
负载均衡:在主从复制的基础上,配合读写分离,由主节点进行写操作,从节点进行读操作,分担服务器的负载;尤其是在多读少写的场景下,通过多个从节点分担负载,提高并发量。
高可用基石:主从复制还是哨兵和集群能够实施的基础。
3.集群搭建
环境配置,复制三个配置文件,然后修改对应的信息
1.端口
port 6370
2.pid名字
pidfile /var/run/redis_6379.pid #如果以后台的方试运行,我们就需要指定一个pid文件!
3.log文件名字
logfile "79.log"
4.dump.rdb
redis-server kconfig/redis79.conf
reids-sever kconfig/redis81.conf #启动redis
reids-sever kconfig/redis82.conf #启动redis
reids-sever kconfig/redis83.conf #启动redis
redis-cli -p 6379 #连接redis
redis-cli -p 6381 #连接redis
redis-cli -p 6382 #连接redis
redis-cli -p 6383 #连接redis
slaveof 127.0.0.1 6379 #认老大,配置文件中配置是永久的,命令配置不是
(1)当主机断电宕机后,默认情况下从机的角色不会发生变化 ,集群中只是失去了写操作,当主机恢复以后,又会连接上从机恢复原状。
(2)当从机断电宕机后,若不是使用配置文件配置的从机,再次启动后作为主机是无法获取之前主机的数据的,若此时重新配置称为从机,又可以获取到主机的所有数据。即配置从机的redis服务重启后,自己就是单独的主机。只要变为从机,立马就会从主机中获取值。
默认情况下,主机故障后,不会出现新的主机,有两种方式可以产生新的主机:
1、从机手动执行命令slaveof no one,这样执行以后从机会独立出来成为一个主机
2、使用哨兵模式(自动选举)
4、哨兵模式 --> 主机宕机后自动选主机
哨兵进程是一个独立进程
目前:1主2从
vim sentinel.conf #编辑哨兵的配置文件
#监控的主机名称 ip 端口号 投票数
sentinel monitor myredis 127.0.0.1 6379 1 #最后的1是投票机制
redis-sentinel kconfig/sentinel.conf #启动哨兵服务
master宕机,81slave当master,当master上线后是81的从机
优缺点:
1.哨兵集群(互相监督),基于主从复制模式,所有的主从配置有点,全有
2.主从可以切换,故障可以转移,系统可用性会更好
3.哨兵模式就是主从模式的升级,手动到自动,更加健壮!
-4.Redis不好在线扩容,集群容量一旦上线,在线扩容十分麻烦
-5.实现哨兵模式的配置很麻烦,里面有很多选择!
哨兵模式的全部配置:
port 26379 #哨兵sentinel实例运行的端口,默认26379
dir /tmp #默认的工作目录
sentinel monitor mymaster 127.0.0.1 6379 2
#挡在Redis实例中开启了requirepass foobared授权密码 这样所有连接Redis实例的客户端都要提供密码
#设置哨兵sentinel 连接主从的密码,注意必须为主从设置一样的验证密码
sentinel auth-pass mymaster MySUPER--secret-0123password
#指定多少毫秒之后,主节点没有回应哨兵sentinel,此时哨兵主观认为主节点下线,默认30s
sentinel down-after-milliseconds mymaster 30000
#发生failover主从切换时组多可以有多少个slave同时对新的master进行同步
#数字越小,完成failover所需的时间就越长
#可以通过将这个值设为1来保证每次只有一个slave处于不能处理命令请求的状态。
sentinel parallel syncs mymaster 1
#故障转移的超时时间:failover-timeout 可以用一下这些方面:
#1.同一个sentinel对同一个master两次failover之间的间隔时间
#2、当1个slave从一个错误的master哪里同步数据开始计算时间,直到slave被纠正为向正确的master哪里同步数据时。
#3、当想要取消一个正在进行的failover所需要的时间
#4、当进行failover时,配置所有slaves指向新的master所需的最大时间。不过,即使过了这个超时,slaves依然会被正确配置为指向master,但是就不按parallel-syncs所配置的规则来
#默认3分钟
sentinel failover-timeout mymaster 180000 #单位ms
#通知脚本
sentinel notification-script mymaster /var/redis/notify.sh
#客户端重新配置主节点参数脚本,可多次调用
sentinel client-reconfig-script mymaster /var/redis/reconfig.sh
5.Redis缓存
(1)缓存穿透
问题表现:redis没有->数据库查询也没有
解决方案:
1.请求过滤->布隆过滤器(校验,不符合丢弃)
一种数据结构,对所有可能查询的参数以hash形式存储,在控制层先进行校验,不符合则丢弃,从而避免对底层存储系统的查询压力
2.数据库为空也存起来
新问题:浪费存储空间存空值,
设过期时间,会对缓存层和存储层有一段时间的窗口不一致,对业务一致性会有影响。
(2)缓存击穿
问题表现:热点数据并发突破缓存,直击数据库
解决方案:
1.设置热点数据永不过期(因为满了会默认随机清理设置时间的缓存数据)
2.加互斥锁
*分布式锁:每个key同时只有一个线程去查询后端服务
(3)缓存雪崩
问题表现:一个时间段,缓存集中过期
解决方案:
1.数据预热:部署前把常访问的数据加载到缓存中,将发生大并发前手动出发加载缓存不同的key,设置不同的过期时间,让缓存失效的时间点均匀分布。
2.增设redis服务器,搭建集群
3.限流降级
在缓存失效后,通过加锁或者队列来控制读数据库写缓存的线程数量。比如对某个key只允许一个线程查询数据和写缓存,其他线程等待。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号