No.2 dotnetcore&docker--数据库等在Docker上的配置
docker里面的网络是一个局域网,如果在同一个局域网里面的容器,可以通过host主机名互相访问。也就是说,如果跟nginx在同一个局域网内的容器,nginx配置转发的时候,就可以用主机名,否则,就要用公网ip+容器对应的公网端口。
在实际的项目上,gitlab和harbor仓位尽量分布在不通的服务器,另外一个服务器可以重新加一个nginx容器,组合在新的应用服务器,一下按照新的一个服务器安装,这个服务器只需要安装docker环境就好了。
harbor是可用可不用的,因为可以不通过harbor来存储,直接在portainer上将镜像仓库上传上去,后续再说。
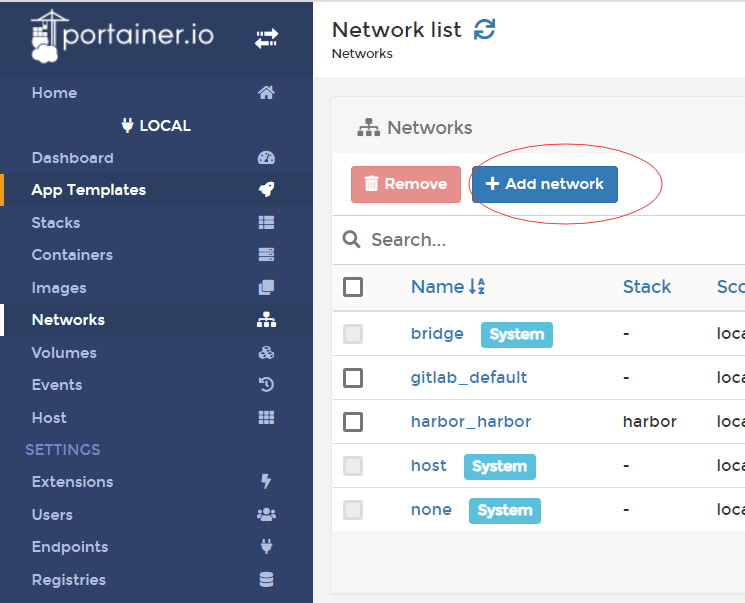
一、搭建新的网络
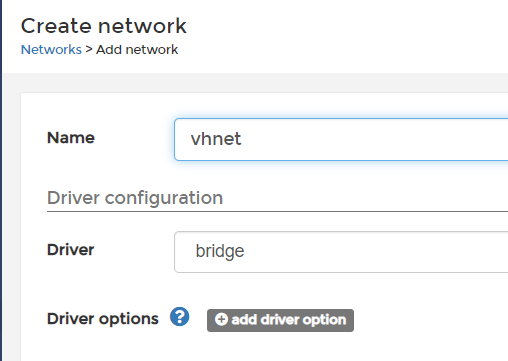
填写一个名字就好了。vhnet,后续的同一个项目的容器都建立在这个局域网内。
一、Nginx 容器
搭建容器,有语法要求:
1、每一个容器的环境变量,都要加上时区,避免一些容器的时区问题;
2、每一个应用的端口,都不要用原生端口号,更换一个新的映射,nginx除外;
全部语法,全部通过 stacks 来建设,这样可以方便修改,更新版本这些。
version: '2'
services:
nginx:
image: nginx:latest
container_name: nginx
hostname: nginx
ports:
- '80:80'
- '443:443'
network_mode: vhnet
restart: always
volumes:
- vm-rc-niginx:/etc/nginx
- vm-rc-nginxshare:/usr/share/nginx/html
environment:
- TZ=Asia/Shanghai
#command: ['nginx','-g','daemon off;']
二、数据库
version: '2'
services:
vhmysql:
image: mysql:5.7
container_name: vhmysql
hostname: vhmsql
ports:
- '13661:3306'
network_mode: vhnet
restart: always
volumes:
- /data/volumns/vhmysql:/var/lib/mysql
- /data/volumns/vhmysqlconf:/etc/mysql/mysql.conf.d
environment:
- TZ=Asia/Shanghai
- MYSQL_ROOT_PASSWORD=abc@@##123
#command: ['nginx','-g','daemon off;']
上面,通过容器券,将数据库文件地址映射到 /data/volumns/vhmysql文件夹下,将数据库的配置文件,放在/data/volumns/vhmysqlconf文件夹下。
接下来在服务器上新增一个配置文件
cd /data/volumns/vhmysqlconf
vim mysql.cnf
[client] port = 3306 socket = /var/run/mysqld/mysqld.sock [mysql] no-auto-rehash [mysqld] port = 3306 datadir = /var/lib/mysql lower_case_table_names = 1 max_connections = 3000 max_user_connections=2980 max_connect_errors=1000000 max_allowed_packet = 1073741824 event_scheduler = 1 sql_mode = "STRICT_TRANS_TABLES,NO_ENGINE_SUBSTITUTION,NO_ZERO_DATE,NO_ZERO_IN_DATE,ERROR_FOR_DIVISION_BY_ZERO,NO_AUTO_CREATE_USER" interactive_timeout = 1800 wait_timeout = 1800 connect_timeout=10 net_read_timeout=30 net_write_timeout=60 net_retry_count=10 lower_case_table_names = 1 table_open_cache = 8192 table_definition_cache = 8192 table_open_cache_instances = 16
访问数据库的模式是 服务器IP,端口号13661,root的密码上面写了。配置已经将mysql全部转成小写了。
三、redis
version: '2'
services:
vhredismaster:
image: redis:latest
container_name: vhredismaster
hostname: vhredismaster
ports:
- '26167:6379'
network_mode: vhnet
restart: always
volumes:
- vm-redis-data:/data
- /data/volumns/redisconf:/etc/config/redis
environment:
- TZ=Asia/Shanghai
command: ['redis-server', '/etc/config/redis/redis.conf']
增加redis配置文件 ,要给redis加上密码
cd /data/volumns/redisconf
vim redis.conf
# Redis 配置文件示例 # 注意单位: 当需要配置内存大小时, 可能需要指定像1k,5GB,4M等常见格式 # # 1k => 1000 bytes # 1kb => 1024 bytes # 1m => 1000000 bytes # 1mb => 1024*1024 bytes # 1g => 1000000000 bytes # 1gb => 1024*1024*1024 bytes # # 单位是对大小写不敏感的 1GB 1Gb 1gB 是相同的。 ################################## INCLUDES ################################### # 可以在这里包含一个或多个其他的配置文件。如果你有一个适用于所有Redis服务器的标准配置模板 # 但也需要一些每个服务器自定义的设置,这个功能将很有用。被包含的配置文件也可以包含其他配置文件, # 所以需要谨慎的使用这个功能。 # # 注意“inclue”选项不能被admin或Redis哨兵的"CONFIG REWRITE"命令重写。 # 因为Redis总是使用最后解析的配置行最为配置指令的值, 你最好在这个文件的开头配置includes来 # 避免它在运行时重写配置。 # 如果相反你想用includes的配置覆盖原来的配置,你最好在该文件的最后使用include # # include /path/to/local.conf # include /path/to/other.conf ################################ GENERAL ##################################### # 默认Rdis不会作为守护进程运行。如果需要的话配置成'yes' # 注意配置成守护进程后Redis会将进程号写入文件/var/run/redis.pid daemonize no # 当以守护进程方式运行时,默认Redis会把进程ID写到 /var/run/redis.pid。你可以在这里修改路径。 pidfile /var/run/redis.pid # 接受连接的特定端口,默认是6379 # 如果端口设置为0,Redis就不会监听TCP套接字。 port 6379 # TCP listen() backlog. # # 在高并发环境下你需要一个高backlog值来避免慢客户端连接问题。注意Linux内核默默地将这个值减小 # 到/proc/sys/net/core/somaxconn的值,所以需要确认增大somaxconn和tcp_max_syn_backlog # 两个值来达到想要的效果。 tcp-backlog 511 # 默认Redis监听服务器上所有可用网络接口的连接。可以用"bind"配置指令跟一个或多个ip地址来实现 # 监听一个或多个网络接口 # # 示例: # # bind 192.168.1.100 10.0.0.1 # bind 127.0.0.1 # 指定用来监听Unix套套接字的路径。没有默认值, 所以在没有指定的情况下Redis不会监听Unix套接字 # # unixsocket /tmp/redis.sock # unixsocketperm 755 # 一个客户端空闲多少秒后关闭连接。(0代表禁用,永不关闭) timeout 0 # TCP keepalive. # # 如果非零,则设置SO_KEEPALIVE选项来向空闲连接的客户端发送ACK,由于以下两个原因这是很有用的: # # 1)能够检测无响应的对端 # 2)让该连接中间的网络设备知道这个连接还存活 # # 在Linux上,这个指定的值(单位:秒)就是发送ACK的时间间隔。 # 注意:要关闭这个连接需要两倍的这个时间值。 # 在其他内核上这个时间间隔由内核配置决定 # # 这个选项的一个合理值是60秒 tcp-keepalive 0 # 指定服务器调试等级 # 可能值: # debug (大量信息,对开发/测试有用) # verbose (很多精简的有用信息,但是不像debug等级那么多) # notice (适量的信息,基本上是你生产环境中需要的) # warning (只有很重要/严重的信息会记录下来) loglevel notice # 指明日志文件名。也可以使用"stdout"来强制让Redis把日志信息写到标准输出上。 # 注意:如果Redis以守护进程方式运行,而设置日志显示到标准输出的话,日志会发送到/dev/null logfile "" # 要使用系统日志记录器,只要设置 "syslog-enabled" 为 "yes" 就可以了。 # 然后根据需要设置其他一些syslog参数就可以了。 # syslog-enabled no # 指明syslog身份 # syslog-ident redis # 指明syslog的设备。必须是user或LOCAL0 ~ LOCAL7之一。 # syslog-facility local0 # 设置数据库个数。默认数据库是 DB 0, # 可以通过select <dbid> (0 <= dbid <= 'databases' - 1 )来为每个连接使用不同的数据库。 databases 16 ################################ SNAPSHOTTING ################################ # # 把数据库存到磁盘上: # # save <seconds> <changes> # # 会在指定秒数和数据变化次数之后把数据库写到磁盘上。 # # 下面的例子将会进行把数据写入磁盘的操作: # 900秒(15分钟)之后,且至少1次变更 # 300秒(5分钟)之后,且至少10次变更 # 60秒之后,且至少10000次变更 # # 注意:你要想不写磁盘的话就把所有 "save" 设置注释掉就行了。 # # 通过添加一条带空字符串参数的save指令也能移除之前所有配置的save指令 # 像下面的例子: # save "" save 900 1 save 300 10 save 60 10000 # 默认如果开启RDB快照(至少一条save指令)并且最新的后台保存失败,Redis将会停止接受写操作 # 这将使用户知道数据没有正确的持久化到硬盘,否则可能没人注意到并且造成一些灾难。 # # 如果后台保存进程能重新开始工作,Redis将自动允许写操作 # # 然而如果你已经部署了适当的Redis服务器和持久化的监控,你可能想关掉这个功能以便于即使是 # 硬盘,权限等出问题了Redis也能够像平时一样正常工作, stop-writes-on-bgsave-error yes # 当导出到 .rdb 数据库时是否用LZF压缩字符串对象? # 默认设置为 "yes",因为几乎在任何情况下它都是不错的。 # 如果你想节省CPU的话你可以把这个设置为 "no",但是如果你有可压缩的key和value的话, # 那数据文件就会更大了。 rdbcompression yes # 因为版本5的RDB有一个CRC64算法的校验和放在了文件的最后。这将使文件格式更加可靠但在 # 生产和加载RDB文件时,这有一个性能消耗(大约10%),所以你可以关掉它来获取最好的性能。 # # 生成的关闭校验的RDB文件有一个0的校验和,它将告诉加载代码跳过检查 rdbchecksum yes # 持久化数据库的文件名 dbfilename dump.rdb # 工作目录 # # 数据库会写到这个目录下,文件名就是上面的 "dbfilename" 的值。 # # 累加文件也放这里。 # # 注意你这里指定的必须是目录,不是文件名。 dir /data/ ################################# REPLICATION ################################# # 主从同步。通过 slaveof 指令来实现Redis实例的备份。 # 注意,这里是本地从远端复制数据。也就是说,本地可以有不同的数据库文件、绑定不同的IP、监听 # 不同的端口。 # # slaveof <masterip> <masterport> # 如果master设置了密码保护(通过 "requirepass" 选项来配置),那么slave在开始同步之前必须 # 进行身份验证,否则它的同步请求会被拒绝。 # # masterauth <master-password> # 当一个slave失去和master的连接,或者同步正在进行中,slave的行为有两种可能: # # 1) 如果 slave-serve-stale-data 设置为 "yes" (默认值),slave会继续响应客户端请求, # 可能是正常数据,也可能是还没获得值的空数据。 # 2) 如果 slave-serve-stale-data 设置为 "no",slave会回复"正在从master同步 # (SYNC with master in progress)"来处理各种请求,除了 INFO 和 SLAVEOF 命令。 # slave-serve-stale-data yes # 你可以配置salve实例是否接受写操作。可写的slave实例可能对存储临时数据比较有用(因为写入salve # 的数据在同master同步之后将很容被删除),但是如果客户端由于配置错误在写入时也可能产生一些问题。 # # 从Redis2.6默认所有的slave为只读 # # 注意:只读的slave不是为了暴露给互联网上不可信的客户端而设计的。它只是一个防止实例误用的保护层。 # 一个只读的slave支持所有的管理命令比如config,debug等。为了限制你可以用'rename-command'来 # 隐藏所有的管理和危险命令来增强只读slave的安全性 slave-read-only yes # slave根据指定的时间间隔向master发送ping请求。 # 时间间隔可以通过 repl_ping_slave_period 来设置。 # 默认10秒。 # # repl-ping-slave-period 10 # 以下选项设置同步的超时时间 # # 1)slave在与master SYNC期间有大量数据传输,造成超时 # 2)在slave角度,master超时,包括数据、ping等 # 3)在master角度,slave超时,当master发送REPLCONF ACK pings # # 确保这个值大于指定的repl-ping-slave-period,否则在主从间流量不高时每次都会检测到超时 # # repl-timeout 60 # 是否在slave套接字发送SYNC之后禁用 TCP_NODELAY ? # # 如果你选择“yes”Redis将使用更少的TCP包和带宽来向slaves发送数据。但是这将使数据传输到slave # 上有延迟,Linux内核的默认配置会达到40毫秒 # # 如果你选择了 "no" 数据传输到salve的延迟将会减少但要使用更多的带宽 # # 默认我们会为低延迟做优化,但高流量情况或主从之间的跳数过多时,把这个选项设置为“yes” # 是个不错的选择。 repl-disable-tcp-nodelay no # 设置数据备份的backlog大小。backlog是一个slave在一段时间内断开连接时记录salve数据的缓冲, # 所以一个slave在重新连接时,不必要全量的同步,而是一个增量同步就足够了,将在断开连接的这段 # 时间内slave丢失的部分数据传送给它。 # # 同步的backlog越大,slave能够进行增量同步并且允许断开连接的时间就越长。 # # backlog只分配一次并且至少需要一个slave连接 # # repl-backlog-size 1mb # 当master在一段时间内不再与任何slave连接,backlog将会释放。以下选项配置了从最后一个 # slave断开开始计时多少秒后,backlog缓冲将会释放。 # # 0表示永不释放backlog # # repl-backlog-ttl 3600 # slave的优先级是一个整数展示在Redis的Info输出中。如果master不再正常工作了,哨兵将用它来 # 选择一个slave提升=升为master。 # # 优先级数字小的salve会优先考虑提升为master,所以例如有三个slave优先级分别为10,100,25, # 哨兵将挑选优先级最小数字为10的slave。 # # 0作为一个特殊的优先级,标识这个slave不能作为master,所以一个优先级为0的slave永远不会被 # 哨兵挑选提升为master # # 默认优先级为100 slave-priority 100 # 如果master少于N个延时小于等于M秒的已连接slave,就可以停止接收写操作。 # # N个slave需要是“oneline”状态 # # 延时是以秒为单位,并且必须小于等于指定值,是从最后一个从slave接收到的ping(通常每秒发送) # 开始计数。 # # This option does not GUARANTEES that N replicas will accept the write, but # will limit the window of exposure for lost writes in case not enough slaves # are available, to the specified number of seconds. # # 例如至少需要3个延时小于等于10秒的slave用下面的指令: # # min-slaves-to-write 3 # min-slaves-max-lag 10 # # 两者之一设置为0将禁用这个功能。 # # 默认 min-slaves-to-write 值是0(该功能禁用)并且 min-slaves-max-lag 值是10。 ################################## SECURITY ################################### # 要求客户端在处理任何命令时都要验证身份和密码。 # 这个功能在有你不信任的其它客户端能够访问redis服务器的环境里非常有用。 # # 为了向后兼容的话这段应该注释掉。而且大多数人不需要身份验证(例如:它们运行在自己的服务器上) # # 警告:因为Redis太快了,所以外面的人可以尝试每秒150k的密码来试图破解密码。这意味着你需要 # 一个高强度的密码,否则破解太容易了。 # requirepass abbbbdddd # 命令重命名 # # 在共享环境下,可以为危险命令改变名字。比如,你可以为 CONFIG 改个其他不太容易猜到的名字, # 这样内部的工具仍然可以使用,而普通的客户端将不行。 # # 例如: # # rename-command CONFIG b840fc02d524045429941cc15f59e41cb7be6c52 # # 也可以通过改名为空字符串来完全禁用一个命令 # # rename-command CONFIG "" # # 请注意:改变命令名字被记录到AOF文件或被传送到从服务器可能产生问题。 ################################### LIMITS #################################### # 设置最多同时连接的客户端数量。默认这个限制是10000个客户端,然而如果Redis服务器不能配置 # 处理文件的限制数来满足指定的值,那么最大的客户端连接数就被设置成当前文件限制数减32(因 # 为Redis服务器保留了一些文件描述符作为内部使用) # # 一旦达到这个限制,Redis会关闭所有新连接并发送错误'max number of clients reached' # maxclients 30000 # 不要用比设置的上限更多的内存。一旦内存使用达到上限,Redis会根据选定的回收策略(参见: # maxmemmory-policy)删除key # # 如果因为删除策略Redis无法删除key,或者策略设置为 "noeviction",Redis会回复需要更 # 多内存的错误信息给命令。例如,SET,LPUSH等等,但是会继续响应像Get这样的只读命令。 # # 在使用Redis作为LRU缓存,或者为实例设置了硬性内存限制的时候(使用 "noeviction" 策略) # 的时候,这个选项通常事很有用的。 # # 警告:当有多个slave连上达到内存上限的实例时,master为同步slave的输出缓冲区所需 # 内存不计算在使用内存中。这样当驱逐key时,就不会因网络问题 / 重新同步事件触发驱逐key # 的循环,反过来slaves的输出缓冲区充满了key被驱逐的DEL命令,这将触发删除更多的key, # 直到这个数据库完全被清空为止 # # 总之...如果你需要附加多个slave,建议你设置一个稍小maxmemory限制,这样系统就会有空闲 # 的内存作为slave的输出缓存区(但是如果最大内存策略设置为"noeviction"的话就没必要了) # # maxmemory <bytes> # 最大内存策略:如果达到内存限制了,Redis如何选择删除key。你可以在下面五个行为里选: # # volatile-lru -> 根据LRU算法生成的过期时间来删除。 # allkeys-lru -> 根据LRU算法删除任何key。 # volatile-random -> 根据过期设置来随机删除key。 # allkeys->random -> 无差别随机删。 # volatile-ttl -> 根据最近过期时间来删除(辅以TTL) # noeviction -> 谁也不删,直接在写操作时返回错误。 # # 注意:对所有策略来说,如果Redis找不到合适的可以删除的key都会在写操作时返回一个错误。 # # 目前为止涉及的命令:set setnx setex append # incr decr rpush lpush rpushx lpushx linsert lset rpoplpush sadd # sinter sinterstore sunion sunionstore sdiff sdiffstore zadd zincrby # zunionstore zinterstore hset hsetnx hmset hincrby incrby decrby # getset mset msetnx exec sort # # 默认值如下: # # maxmemory-policy volatile-lru # LRU和最小TTL算法的实现都不是很精确,但是很接近(为了省内存),所以你可以用样本量做检测。 # 例如:默认Redis会检查3个key然后取最旧的那个,你可以通过下面的配置指令来设置样本的个数。 # # maxmemory-samples 3 ############################## APPEND ONLY MODE ############################### # 默认情况下,Redis是异步的把数据导出到磁盘上。这种模式在很多应用里已经足够好,但Redis进程 # 出问题或断电时可能造成一段时间的写操作丢失(这取决于配置的save指令)。 # # AOF是一种提供了更可靠的替代持久化模式,例如使用默认的数据写入文件策略(参见后面的配置) # 在遇到像服务器断电或单写情况下Redis自身进程出问题但操作系统仍正常运行等突发事件时,Redis # 能只丢失1秒的写操作。 # # AOF和RDB持久化能同时启动并且不会有问题。 # 如果AOF开启,那么在启动时Redis将加载AOF文件,它更能保证数据的可靠性。 # # 请查看 http://redis.io/topics/persistence 来获取更多信息. appendonly no # 纯累加文件名字(默认:"appendonly.aof") appendfilename "appendonly.aof" # fsync() 系统调用告诉操作系统把数据写到磁盘上,而不是等更多的数据进入输出缓冲区。 # 有些操作系统会真的把数据马上刷到磁盘上;有些则会尽快去尝试这么做。 # # Redis支持三种不同的模式: # # no:不要立刻刷,只有在操作系统需要刷的时候再刷。比较快。 # always:每次写操作都立刻写入到aof文件。慢,但是最安全。 # everysec:每秒写一次。折中方案。 # # 默认的 "everysec" 通常来说能在速度和数据安全性之间取得比较好的平衡。根据你的理解来 # 决定,如果你能放宽该配置为"no" 来获取更好的性能(但如果你能忍受一些数据丢失,可以考虑使用 # 默认的快照持久化模式),或者相反,用“always”会比较慢但比everysec要更安全。 # # 请查看下面的文章来获取更多的细节 # http://antirez.com/post/redis-persistence-demystified.html # # 如果不能确定,就用 "everysec" # appendfsync always appendfsync everysec # appendfsync no # 如果AOF的同步策略设置成 "always" 或者 "everysec",并且后台的存储进程(后台存储或写入AOF # 日志)会产生很多磁盘I/O开销。某些Linux的配置下会使Redis因为 fsync()系统调用而阻塞很久。 # 注意,目前对这个情况还没有完美修正,甚至不同线程的 fsync() 会阻塞我们同步的write(2)调用。 # # 为了缓解这个问题,可以用下面这个选项。它可以在 BGSAVE 或 BGREWRITEAOF 处理时阻止fsync()。 # # 这就意味着如果有子进程在进行保存操作,那么Redis就处于"不可同步"的状态。 # 这实际上是说,在最差的情况下可能会丢掉30秒钟的日志数据。(默认Linux设定) # # 如果把这个设置成"yes"带来了延迟问题,就保持"no",这是保存持久数据的最安全的方式。 no-appendfsync-on-rewrite no # 自动重写AOF文件 # 如果AOF日志文件增大到指定百分比,Redis能够通过 BGREWRITEAOF 自动重写AOF日志文件。 # # 工作原理:Redis记住上次重写时AOF文件的大小(如果重启后还没有写操作,就直接用启动时的AOF大小) # # 这个基准大小和当前大小做比较。如果当前大小超过指定比例,就会触发重写操作。你还需要指定被重写 # 日志的最小尺寸,这样避免了达到指定百分比但尺寸仍然很小的情况还要重写。 # # 指定百分比为0会禁用AOF自动重写特性。 auto-aof-rewrite-percentage 100 auto-aof-rewrite-min-size 64mb ################################ LUA SCRIPTING ############################### # Lua 脚本的最大执行时间,毫秒为单位 # # 如果达到了最大的执行时间,Redis将要记录在达到最大允许时间之后一个脚本仍然在执行,并且将 # 开始对查询进行错误响应。 # # 当一个长时间运行的脚本超过了最大执行时间,只有 SCRIPT KILL 和 SHUTDOWN NOSAVE 两个 # 命令可用。第一个可以用于停止一个还没有调用写命名的脚本。第二个是关闭服务器唯一方式,当 # 写命令已经通过脚本开始执行,并且用户不想等到脚本的自然终止。 # # 设置成0或者负值表示不限制执行时间并且没有任何警告 lua-time-limit 5000 ################################## SLOW LOG ################################### # Redis慢查询日志可以记录超过指定时间的查询。运行时间不包括各种I/O时间,例如:连接客户端, # 发送响应数据等,而只计算命令执行的实际时间(这只是线程阻塞而无法同时为其他请求服务的命令执 # 行阶段) # # 你可以为慢查询日志配置两个参数:一个指明Redis的超时时间(单位为微秒)来记录超过这个时间的命令 # 另一个是慢查询日志长度。当一个新的命令被写进日志的时候,最老的那个记录从队列中移除。 # # 下面的时间单位是微秒,所以1000000就是1秒。注意,负数时间会禁用慢查询日志,而0则会强制记录 # 所有命令。 slowlog-log-slower-than 10000 # 这个长度没有限制。只是要主要会消耗内存。你可以通过 SLOWLOG RESET 来回收内存。 slowlog-max-len 128 ############################# Event notification ############################## # Redis 能通知 Pub/Sub 客户端关于键空间发生的事件 # 这个功能文档位于http://redis.io/topics/keyspace-events # # 例如:如果键空间事件通知被开启,并且客户端对 0 号数据库的键 foo 执行 DEL 命令时,将通过 # Pub/Sub发布两条消息: # PUBLISH __keyspace@0__:foo del # PUBLISH __keyevent@0__:del foo # # 可以在下表中选择Redis要通知的事件类型。事件类型由单个字符来标识: # # K 键空间通知,以__keyspace@<db>__为前缀 # E 键事件通知,以__keysevent@<db>__为前缀 # g DEL , EXPIRE , RENAME 等类型无关的通用命令的通知, ... # $ String命令 # l List命令 # s Set命令 # h Hash命令 # z 有序集合命令 # x 过期事件(每次key过期时生成) # e 驱逐事件(当key在内存满了被清除时生成) # A g$lshzxe的别名,因此”AKE”意味着所有的事件 # # notify-keyspace-events 带一个由0到多个字符组成的字符串参数。空字符串意思是通知被禁用。 # # 例子:启用List和通用事件通知: # notify-keyspace-events Elg # # 例子2:为了获取过期key的通知订阅名字为 __keyevent@__:expired 的频道,用以下配置 # notify-keyspace-events Ex # # 默认所用的通知被禁用,因为用户通常不需要该特性,并且该特性会有性能损耗。 # 注意如果你不指定至少K或E之一,不会发送任何事件。 notify-keyspace-events "" ############################### ADVANCED CONFIG ############################### # 当hash只有少量的entry时,并且最大的entry所占空间没有超过指定的限制时,会用一种节省内存的 # 数据结构来编码。可以通过下面的指令来设定限制 hash-max-ziplist-entries 512 hash-max-ziplist-value 64 # 与hash似,数据元素较少的list,可以用另一种方式来编码从而节省大量空间。 # 这种特殊的方式只有在符合下面限制时才可以用: list-max-ziplist-entries 512 list-max-ziplist-value 64 # set有一种特殊编码的情况:当set数据全是十进制64位有符号整型数字构成的字符串时。 # 下面这个配置项就是用来设置set使用这种编码来节省内存的最大长度。 set-max-intset-entries 512 # 与hash和list相似,有序集合也可以用一种特别的编码方式来节省大量空间。 # 这种编码只适合长度和元素都小于下面限制的有序集合: zset-max-ziplist-entries 128 zset-max-ziplist-value 64 # HyperLogLog sparse representation bytes limit. The limit includes the # 16 bytes header. When an HyperLogLog using the sparse representation crosses # this limit, it is converted into the dense representation. # # A value greater than 16000 is totally useless, since at that point the # dense representation is more memory efficient. # # The suggested value is ~ 3000 in order to have the benefits of # the space efficient encoding without slowing down too much PFADD, # which is O(N) with the sparse encoding. The value can be raised to # ~ 10000 when CPU is not a concern, but space is, and the data set is # composed of many HyperLogLogs with cardinality in the 0 - 15000 range. hll-sparse-max-bytes 3000 # 启用哈希刷新,每100个CPU毫秒会拿出1个毫秒来刷新Redis的主哈希表(顶级键值映射表)。 # redis所用的哈希表实现(见dict.c)采用延迟哈希刷新机制:你对一个哈希表操作越多,哈希刷新 # 操作就越频繁;反之,如果服务器是空闲的,那么哈希刷新就不会完成,哈希表就会占用更多的一些 # 内存而已。 # # 默认是每秒钟进行10次哈希表刷新,用来刷新字典,然后尽快释放内存。 # # 建议: # 如果你对延迟比较在意,不能够接受Redis时不时的对请求有2毫秒的延迟的话,就用 # "activerehashing no",如果不太在意延迟而希望尽快释放内存就设置"activerehashing yes" activerehashing yes # 客户端的输出缓冲区的限制,可用于强制断开那些因为某种原因从服务器读取数据的速度不够快的客户端, # (一个常见的原因是一个发布/订阅客户端消费消息的速度无法赶上生产它们的速度) # # 可以对三种不同的客户端设置不同的限制: # normal -> 正常客户端 # slave -> slave和 MONITOR 客户端 # pubsub -> 至少订阅了一个pubsub channel或pattern的客户端 # # 下面是每个client-output-buffer-limit语法: # client-output-buffer-limit <class><hard limit> <soft limit> <soft seconds> # 一旦达到硬限制客户端会立即被断开,或者达到软限制并持续达到指定的秒数(连续的)。 # 例如,如果硬限制为32兆字节和软限制为16兆字节/10秒,客户端将会立即断开 # 如果输出缓冲区的大小达到32兆字节,或客户端达到16兆字节并连续超过了限制10秒,就将断开连接。 # # 默认normal客户端不做限制,因为他们在不主动请求时不接收数据(以推的方式),只有异步客户端 # 可能会出现请求数据的速度比它可以读取的速度快的场景。 # # pubsub和slave客户端会有一个默认值,因为订阅者和slaves以推的方式来接收数据 # # 把硬限制和软限制都设置为0来禁用该功能 client-output-buffer-limit normal 0 0 0 client-output-buffer-limit slave 256mb 64mb 60 client-output-buffer-limit pubsub 32mb 8mb 60 # Redis调用内部函数来执行许多后台任务,如关闭客户端超时的连接,清除未被请求过的过期Key等等。 # # 不是所有的任务都以相同的频率执行,但Redis依照指定的“hz”值来执行检查任务。 # # 默认情况下,“hz”的被设定为10。提高该值将在Redis空闲时使用更多的CPU时,但同时当有多个key # 同时到期会使Redis的反应更灵敏,以及超时可以更精确地处理。 # # 范围是1到500之间,但是值超过100通常不是一个好主意。 # 大多数用户应该使用10这个默认值,只有在非常低的延迟要求时有必要提高到100。 hz 10 # 当一个子进程重写AOF文件时,如果启用下面的选项,则文件每生成32M数据会被同步。为了增量式的 # 写入硬盘并且避免大的延迟高峰这个指令是非常有用的 aof-rewrite-incremental-fsync yes
由于我这里需要两个Redis,另外一个专门存储系统的配置信息用来代替.json的配置文件以及代替携程apollo配置中心,只需要修改上面的主机名,端口和磁盘映射就可以了,配置可以共用一个,所以配置文件的磁盘卷可以一样。
四、mongodb
version: '2'
services:
vhmongodb:
image: mongo:4.0
container_name: vhmongodb
hostname: vhmongodb
#networks:
# vhnet:
# - ipv4_address: 172.22.0.2
ports:
- '17170:27017'
network_mode: vhnet
restart: always
volumes:
- vm-mongo-data-db:/data/db
- vm-mongo-config-db:/data/configdb
- vm-mongo-log:/logs
- /data/volumns/vhmongoconf:/etc/config/mongo
environment:
- TZ=Asia/Shanghai
command: ['mongod','-f','/etc/config/mongo/mongod.conf']
cd /data/volumns/vhmongoconf
vim mongod.conf
dbpath = /data/db/ #logpath = /logs/mongodb.log port = 27017 fork = false bind_ip=0.0.0.0 auth = true
五、号外
新增一个sqlserver的容器以及一个携程apollo的容器搭建代码。


version: '2' services: vhsqlserver: image: registry.docker-cn.com/microsoft/mssql-server-linux:2017-GA container_name: vhsqlser hostname: vhSqlServer ports: - '3421:1433' network_mode: vhnet restart: always volumes: - vm-vh-sqlserver-mssql:/opt/mssql - vm-vh-sqlserver-data:/var/opt/mssql - vm-vh-sqlserver-system:/lib/systemd/system environment: - TZ=Asia/Shanghai - ACCEPT_EULA=Y - SA_PASSWORD=ABC#@123abc #command: ['nginx','-g','daemon off;'] SA_PASSWORD
version: '2' services: vhApolloAdmin: image: idoop/docker-apollo:latest container_name: vhApolloAdmin hostname: vhApolloAdmin ports: - '14590:14590' - '14580:14580' network_mode: vhnet restart: always volumes: - /data/apollo/admin/opt/logs:/opt/logs - /data/apollo/admin/logs:/logs - /etc/localtime:/etc/localtime # 启动前,确认对应环境的数据库已经建立,否则apollo无法启动. # 默认端口:portal:8070; dev:8080,8090; fat:8081,8091; uat:8082,8092; pro:8083,8093 environment: DEV_DB: jdbc:mysql://vhmysql:3306/ApolloConfigDB?characterEncoding=utf8 DEV_DB_USER: apollo DEV_DB_PWD: vhABS321#@a TZ: Asia/Shanghai #PRO_URL: http://116.196.117.188:8080 #DEV_URL: http://116.196.117.188:8080 #DEV_ADMIN_PORT: 8090 #CONFIG_DEV_PORT: 8080 #ADMIN_DEV_PORT: 8090 #DEV_CONFIG_PORT: 8080 DEV_CONFIG_PORT: 14580 DEV_ADMIN_PORT: 14590 #JAVA_OPTS: "-Ddev_meta=http://116.196.117.188:8091 -Deureka.instance.homePageUrl=http://116.196.117.188:8091 -Deureka.instance.ip-address=116.196.117.188 -Dapollo.configService=http://116.196.117.188:8091" JAVA_OPTS: "-Deureka.instance.ip-address=116.196.117.188" vhApolloPortal: image: idoop/docker-apollo:latest container_name: vhApolloPortal hostname: vhApolloPortal ports: - '14570:14570' network_mode: vhnet restart: always volumes: - /data/apollo/portal/opt/logs:/opt/logs - /data/apollo/portal/logs:/logs - /etc/localtime:/etc/localtime # 启动前,确认对应环境的数据库已经建立,否则apollo无法启动. # 默认端口:portal:8070; dev:8080,8090; fat:8081,8091; uat:8082,8092; pro:8083,8093 80开头变成145开头 environment: TZ: Asia/Shanghai PORTAL_DB: jdbc:mysql://vhmysql:3306/ApolloPortalDB?characterEncoding=utf8 PORTAL_DB_USER: apollo PORTAL_DB_PWD: vhABS321#@a PORTAL_PORT: 14570 DEV_URL: http://vhApolloAdmin:14580 DEV_CONFIG_PORT: 14580 DEV_ADMIN_PORT: 14590 depends_on: - vhApolloAdmin



 浙公网安备 33010602011771号
浙公网安备 33010602011771号