

MongoDB要点
MongoDB
一、介绍
MongoDB是用C++语言编写的非关系型数据库。特点是高性能、易部署、易使用,存储数据十分方便,主要特性有:
- 面向集合存储,易于存储对象类型的数据
- 模式自由
- 支持动态查询
- 支持完全索引,包含内部对象
- 支持复制和故障恢复
- 使用高效的二进制数据存储,包括大型对象
- 文件存储格式为BSON(一种JSON的扩展)
MongoDB基本概念
- 文档(document)是MongoDB中数据的基本单元,非常类似于关系型数据库系统中的行(但是比行要复杂的多)。
- 集合(collection)就是一组文档,如果说MongoDB中的文档类似于关系型数据库中的行,那么集合就如同表。
- MongoDB的单个计算机可以容纳多个独立的数据库,每一个数据库都有自己的集合和权限。
- MongoDB自带简洁但功能强大的JavaScript shell,这个工具对于管理MongoDB实例和操作数据作用非常大。
- 每一个文档都有一个特殊的键”_id”,它在文档所处的集合中是唯一的,相当于关系数据库中的表的主键。
二、安装
1、系统准备
(1)redhat或cnetos6.2以上系统
(2)系统开发包完整
(3)ip地址和hosts文件解析正常
(4)iptables防火墙&SElinux关闭
(5)关闭大页内存机制
# 2.关闭大页内存机制
root用户下
# 追加到配置文件,每次开机自启动
cat >>/etc/rc.local <<EOF
if test -f /sys/kernel/mm/transparent_hugepage/enabled; then
echo never > /sys/kernel/mm/transparent_hugepage/enabled
fi
if test -f /sys/kernel/mm/transparent_hugepage/defrag; then
echo never > /sys/kernel/mm/transparent_hugepage/defrag
fi
EOF
# 或者在命令行直接运行,但是开机不会自启动
echo never > /sys/kernel/mm/transparent_hugepage/enabled
echo never > /sys/kernel/mm/transparent_hugepage/defrag
# 为什么要关闭
透明大页面(THP)是一个Linux内存管理系统
这样就减少了转换后备缓冲区(TLB)的开销。
通过使用更大的内存页查找具有大量内存的计算机。
但是,数据库工作负载在THP中通常表现不佳,
因为它们往往具有稀疏而不是连续的内存访问模式。
您应该在Linux机器上禁用THP,以确保MongoDB的最佳性能。
2.mongodb安装
# 1.创建所需用户和组 最好不用root用户操作
groupadd -g 800 mongod
useradd -u 801 -g mongod mongod
passwd mongod
# 2.创建mongodb所需目录结构
mkdir -p /mongodb/bin
mkdir -p /mongodb/conf
mkdir -p /mongodb/log
mkdir -p /mongodb/data
# 3.上传并解压软件到指定位置
# 上传到:
cd /opt/
# 解压:
tar xf mongodb-linux-x86_64-rhel70-3.4.16.tgz
# 拷贝目录下bin程序到/mongodb/bin
cp -a /opt/mongodb-linux-x86_64-rhel70-3.4.16/bin/* /mongodb/bin
# 4.设置目录结构权限
chown -R mongod:mongod /mongodb
# 5.设置用户环境变量
# 切换到mongod用户
su - mongod
cat >> .bash_profile << EOF
export PATH=/mongodb/bin:$PATH
EOF
source .bash_profile
# 6.启动mongodb
mongod --dbpath=/mongodb/data --logpath=/mongodb/log/mongodb.log --port=27017 --logappend --fork
# 7.登录mongodb
[mongod@server2 ~]$ mongo
# 8.使用配置文件登录
vim /mongodb/conf/mongodb.conf
logpath=/mongodb/log/mongodb.log
dbpath=/mongodb/data
port=27017
fork=true
# 9.关闭mongodb
mongod -f /mongodb/conf/mongodb.conf --shutdown
# 10.使用配置文件启动mongodb
mongod -f /mongodb/conf/mongodb.conf
3.mongodb配置YAML模式
# 在以后,向这样的xxx=xxx的形式可能要淘汰了
logpath=/mongodb/log/mongodb.log
dbpath=/mongodb/data
port=27017
fork=true
# 推荐使用YAML模式
# YAML模式里不允许使用tab健
# 系统日志有关
systemLog:
destination: file
path: "/mongodb/log/mongodb.log" # 日志位置
logAppend: true # 日志以追加模式记录
# 数据存储有关
storage:
journal:
enabled: true
dbPath: "/mongodb/data" # 数据路径的位置
# 进程控制
processManagement:
fork: true # 后台守护进程
pidFilePath: <string> # pid文件的位置,一般不用配置,可以去掉这行,自动生成到data中
# 网络配置有关
net:
bindIp: <ip> # 监听地址,如果不配置这行是监听在0.0.0.0
port: <port> # 端口号,默认不配置端口号,是27017
# 安全验证有关配置
security:
authorization: enabled # 是否打开用户名密码验证
------------------以下是复制集与分片集群有关---------------------
replication:
oplogSizeMB: <NUM>
replSetName: "<REPSETNAME>"
secondaryIndexPrefetch: "all"
sharding:
clusterRole: <string>
archiveMovedChunks: <boolean>
---for mongos only
replication:
localPingThresholdMs: <int>
sharding:
configDB: <string>
# 实例
# mongodb基础配置YAML模式
cat >> /mongodb/conf/mongo.conf << EOF
systemLog:
destination: file
path: "/mongodb/log/mongodb.log"
logAppend: true
storage:
journal:
enabled: true
dbPath: "/mongodb/data/"
processManagement:
fork: true
net:
port: 27017
EOF
# 关闭并以配置启动
mongod -f /mongodb/conf/mongo.conf --shutdown
mongod -f /mongodb/conf/mongo.conf
三、mongodb常用基本操作
1.mongodb 默认存在的库
test:登录时默认存在的库
admin库:系统预留库,mongodb系统管理库
local库:本地预留库,存储关键日志
2.mongodb对象操作
mongo mysql
库 -----> 库
集合 -----> 表
文档 -----> 数据行
3.命令分类
# 库(database)
# 创建数据库:
当use的时候,系统就会自动创建一个数据库。
如果use之后没有创建任何集合。
系统就会删除这个数据库。
# 删除数据库
如果没有选择任何数据库,会删除默认的test数据库
# 显示所有库
show databases
show dbs
# 切换库
use oldguo
-------------------------------
# 表(collection集合)
# 查看当前数据下的所有集合
show tables
show collections
db.getCollectionNames()
# 创建集合
# 方法一
db.createCollection('a')
# 方法2:当插入一个文档的时候,一个集合就会自动创建。
use oldguo
# 在oldguo库下创建表(集合)并插入{id:101,name:"zhangsan",age:20,gender:"m"}
db.stu.insert({id:101,name:"zhangsan",age:20,gender:"m"})
# 删除集合
use oldguo
db.log.drop()
# 重命名集合
# 把log改名为log1
db.log.renameCollection("log1")
----------------------------------------------
# 数据行(document)
# 查询数据:
# 整行显示
db.stu.find({})
# 格式显示
db.stu.find({}).pretty()
# 指定查找
db.stu.find({id:101}).pretty();
# 注:默认每页显示20条记录,当显示不下的的情况下,可以用it迭代命令查询下一页数据。
# 设置每页显示数据的大小:
DBQuery.shellBatchSize=50; //每页显示50条记录
# 查看第1条记录
db.log.findOne()
# 查询总的记录数
db.log.count()
# 删除集合中的记录数
app> db.log.remove({}) //删除集合中所有记录
> db.log.distinct("name") //查询去掉当前集合中某列的重复数据
# 查看集合存储信息
app> db.log.stats()
app> db.log.dataSize() //集合中数据的原始大小
app> db.log.totalIndexSize() //集合中索引数据的原始大小
app> db.log.totalSize() //集合中索引+数据压缩存储之后的大小
app> db.log.storageSize() //集合中数据压缩存储的大小
-------------------------------------------
# db.命令:
# 类似于linux中的tab功能
db.[TAB]
# db级别的命令使用帮助
db.help()
# 查看当前db版本
db.version()
# 显示当前数据库
db
# 或
db.getName()
# 显示当前数据库状态
db.stats()
# 查看当前数据库的连接机器地址
db.getMongo()
四、用户管理
1.语法格式
# 注意:
# 验证库,建立用户时use到的库,在使用用户时,要加上验证库才能登陆。
# 对于管理员用户,必须在admin下创建.
# 基本语法
db.createUser(
{
user: "<name>",
pwd: "<cleartext password>",
roles: [
{
role: "<role>",
db: "<database>"
},
...
]
})
# 基本语法说明:
user:用户名
pwd:密码
roles:
role:角色名
db:作用对象
role:root, readWrite,read
# 验证数据库:
# mongo -u oldguo -p 123 10.0.0.200/验证库名
# 总结:
1、在创建普通用户时,一般事先use 到想要设置权限的库下;或者所有普通用户使用同一个验证库,比如test
2、root角色的创建,要在admin下进行创建
3、创建用户时你use到的库,在将来登录时候,使用以下方式登录,否则是登录不了的
# 查询mongodb中的用户信息
mongo -uroot -proot123 10.0.0.200/admin
db.system.users.find().pretty()
# 删除用户(root身份登录,use到验证库)
# 删除用户
mongo -uroot -proot123 10.0.0.200/admin
use app
db.dropUser("app01")
2.实例
# 1.创建超级管理员:管理所有数据库(必须use admin再去创建)
use admin
db.createUser(
{
user: "root",
pwd: "root123",
roles: [ { role: "root", db: "admin" } ]
}
)
# 2.验证用户
db.auth('root','root123')
# 3.配置文件中,追加以下配置,开启验证功能
cat >> /mongodb/conf/mongo.conf << EOF
security:
authorization: enabled
EOF
# 4.重启mongodb
mongod -f /mongodb/conf/mongo.conf --shutdown
mongod -f /mongodb/conf/mongo.conf
# 5.登录验证,进入的默认是验证库
mongo -uroot -proot123 admin
mongo -uroot -proot123 10.0.0.200/admin
# 或者
mongo
use admin
db.auth('root','root123')
# 查看用户:
use admin
db.system.users.find().pretty()
---------------------------------------------------------
# 1.创建app数据库读写权限的用户并对test数据库具有读权限:
mongo -uroot -proot123 10.0.0.200/admin
use app
db.createUser(
{
user: "app03",
pwd: "app03",
roles: [ { role: "readWrite", db: "app" },
{ role: "read", db: "test" }
]
}
)
# 测试
mongo -uapp03 -papp03 10.0.0.200/app
五、mongodb复制集(Replcation Set)
1.基本原理
基本构成是1主2从的结构,自带互相监控投票机制(Raft(MongoDB) Paxos(mysql MGR 用的是变种))
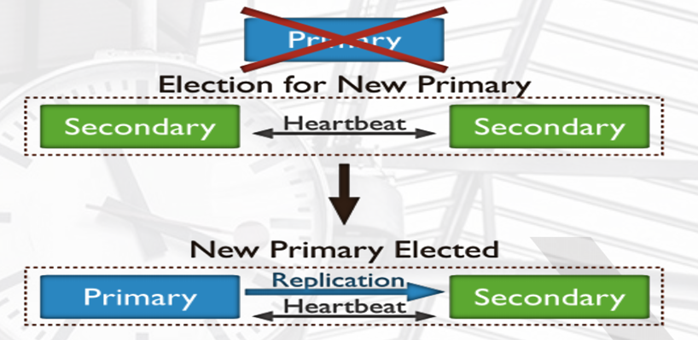
如果发生主库宕机,复制集内部会进行投票选举,选择一个新的主库替代原有主库对外提供服务。同时复制集会自动通知客户端程序,主库已经发生切换了。应用就会连接到新的主库。
2.复制的基本架构
一个包含3个mongod的复制集架构如下所示
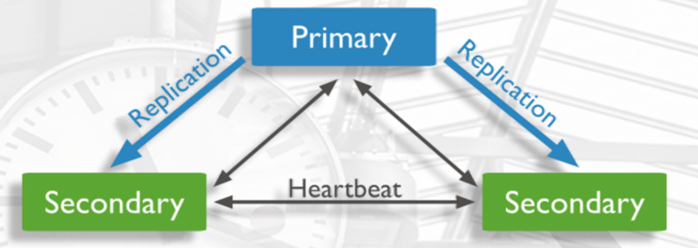
如果主服务器失效,会变成:
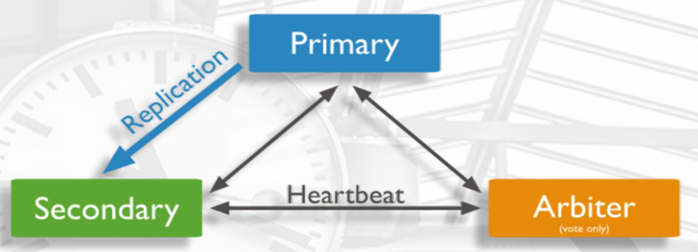
如果加上可选的仲裁者:
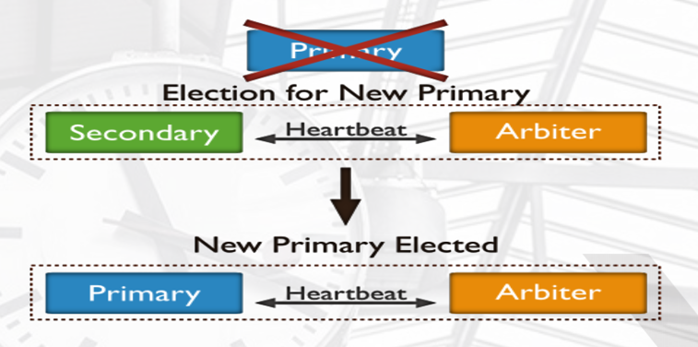
如果主服务器失效:
3.配置
# 三个以上的mongodb节点(或多实例)
# 多个端口:28017、28018、28019、28020
# 1.创建节点多套目录:
mkdir -p /mongodb/28017/conf /mongodb/28017/data /mongodb/28017/log
mkdir -p /mongodb/28018/conf /mongodb/28018/data /mongodb/28018/log
mkdir -p /mongodb/28019/conf /mongodb/28019/data /mongodb/28019/log
mkdir -p /mongodb/28020/conf /mongodb/28020/data /mongodb/28020/log
# 2.配置多套配置文件
# 配置文件内容:
cat >>/mongodb/28017/conf/mongod.conf << EOF
systemLog:
destination: file
path: /mongodb/28017/log/mongodb.log
logAppend: true
storage:
journal:
enabled: true
dbPath: /mongodb/28017/data
directoryPerDB: true
#engine: wiredTiger
wiredTiger:
engineConfig:
cacheSizeGB: 1
directoryForIndexes: true
collectionConfig:
blockCompressor: zlib
indexConfig:
prefixCompression: true
processManagement:
fork: true
net:
port: 28017
replication:
oplogSizeMB: 2048
replSetName: my_repl
EOF
cp /mongodb/28017/conf/mongod.conf /mongodb/28018/conf/
cp /mongodb/28017/conf/mongod.conf /mongodb/28019/conf/
cp /mongodb/28017/conf/mongod.conf /mongodb/28020/conf/
sed 's#28017#28018#g' /mongodb/28018/conf/mongod.conf -i
sed 's#28017#28019#g' /mongodb/28019/conf/mongod.conf -i
sed 's#28017#28020#g' /mongodb/28020/conf/mongod.conf -i
# 3.启动多个实例备用
mongod -f /mongodb/28017/conf/mongod.conf
mongod -f /mongodb/28018/conf/mongod.conf
mongod -f /mongodb/28019/conf/mongod.conf
mongod -f /mongodb/28020/conf/mongod.conf
# 4.端口检测
netstat -lnp|grep 280
# 5.配置复制集
# 1主2从,从库普通从库
# 连接随便一个节点
mongo --port 28017 admin
# 配置主从信息
config = {_id: 'my_repl', members: [
{_id: 0, host: '10.0.0.200:28017'},
{_id: 1, host: '10.0.0.200:28018'},
{_id: 2, host: '10.0.0.200:28019'}]
}
# 使用配置
rs.initiate(config)
# 查询复制集状态
rs.status();
# 主节点可读可写,从节点只读
# 1主1从1个arbiter
mongo -port 28017 admin
config = {_id: 'my_repl', members: [
{_id: 0, host: '10.0.0.200:28017'},
{_id: 1, host: '10.0.0.200:28018'},
{_id: 2, host: '10.0.0.200:28019',"arbiterOnly":true}]
}
rs.initiate(config)
4.复制集管理操作
# 1.查看复制集状态:
rs.status(); //查看整体复制集状态
rs.isMaster(); // 查看当前是否是主节点
# 2.添加删除节点
rs.remove("ip:port"); // 删除一个节点
rs.add("ip:port"); // 新增从节点
rs.addArb("ip:port"); // 新增仲裁节点
# 注:
添加特殊节点时,
1.可以在搭建过程中设置特殊节点
2.可以通过修改配置的方式将普通从节点设置为特殊节点
5.特殊节点
# 特殊节点:
arbiter节点:主要负责选主过程中的投票,但是不存储任何数据,也不提供任何服务
hidden节点:隐藏节点,不参与选主,也不对外提供服务。
delay节点:延时节点,数据落后于主库一段时间,因为数据是延时的,也不应该提供服务或参与选主,所以通常会配合hidden(隐藏)
# 注:一般情况下会将delay+hidden一起配置使用
# 1.添加 arbiter节点
# 连接到主节点
[mongod@db03 ~]$ mongo --port 28018 admin
# 添加仲裁节点
my_repl:PRIMARY> rs.addArb("10.0.0.200:28020")
# 查看节点状态
my_repl:PRIMARY> rs.isMaster()
{
"hosts" : [
"10.0.0.200:28017",
"10.0.0.200:28018",
"10.0.0.200:28019"
],
"arbiters" : [
"10.0.0.200:28020"
],
}
6.其他操作命令
# 查看副本集的配置信息
admin> rs.config()
# 或者
admin> rs.conf()
# 查看副本集各成员的状态
admin> rs.status()
# 副本集角色切换(不要人为随便操作)
admin> rs.stepDown()
# 注:
admin> rs.freeze(300) # 锁定从,使其不会转变成主库
# freeze()和stepDown单位都是秒。
# 设置副本节点可读:在副本节点执行
admin> rs.slaveOk()
eg:
admin> use app
switched to db app
app> db.createCollection('a')
{ "ok" : 0, "errmsg" : "not master", "code" : 10107 }
# 查看副本节点(监控主从延时)
admin> rs.printSlaveReplicationInfo()
source: 192.168.1.22:27017
syncedTo: Thu May 26 2016 10:28:56 GMT+0800 (CST)
0 secs (0 hrs) behind the primary
六、MongoDB Sharding Cluster 分片集群
分片(sharding)是MongoDB用来将大型集合分割到不同服务器(或者说一个集群)上所采用的方法。尽管分片起源于关系型数据库分区,但MongoDB分片完全又是另一回事。
和MySQL分区方案相比,MongoDB的最大区别在于它几乎能自动完成所有事情,只要告诉MongoDB要分配数据,它就能自动维护数据在不同服务器之间的均衡。
1.MongoDB分片介绍
1.1 分片的目的
高数据量和吞吐量的数据库应用会对单机的性能造成较大压力,大的查询量会将单机的CPU耗尽,大的数据量对单机的存储压力较大,最终会耗尽系统的内存而将压力转移到磁盘IO上。
为了解决这些问题,有两个基本的方法: 垂直扩展和水平扩展。
垂直扩展:增加更多的CPU和存储资源来扩展容量。
水平扩展:将数据集分布在多个服务器上。水平扩展即分片。
1.2 分片设计思想
分片为应对高吞吐量与大数据量提供了方法。使用分片减少了每个分片需要处理的请求数,因此,通过水平扩展,集群可以提高自己的存储容量和吞吐量。举例来说,当插入一条数据时,应用只需要访问存储这条数据的分片.
使用分片减少了每个分片存储的数据。
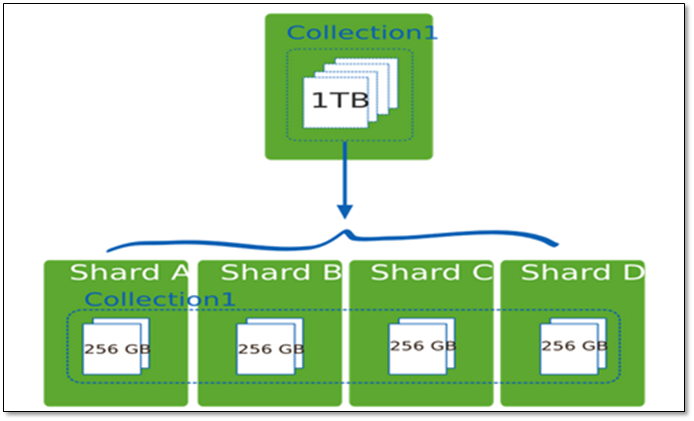
例如,如果数据库1tb的数据集,并有4个分片,然后每个分片可能仅持有256 GB的数据。如果有40个分片,那么每个切分可能只有25GB的数据。
1.3 分片机制提供了如下三种优势
-
对集群进行抽象,让集群“不可见”
MongoDB自带了一个叫做mongos的专有路由进程。mongos就是掌握统一路口的路由器,其会将客户端发来的请求准确无误的路由到集群中的一个或者一组服务器上,同时会把接收到的响应拼装起来发回到客户端。
-
保证集群总是可读写
MongoDB通过多种途径来确保集群的可用性和可靠性。将MongoDB的分片和复制功能结合使用,在确保数据分片到多台服务器的同时,也确保了每分数据都有相应的备份,这样就可以确保有服务器换掉时,其他的从库可以立即接替坏掉的部分继续工作。
-
使集群易于扩展
当系统需要更多的空间和资源的时候,MongoDB使我们可以按需方便的扩充系统容量。
1.4 分片集群架构
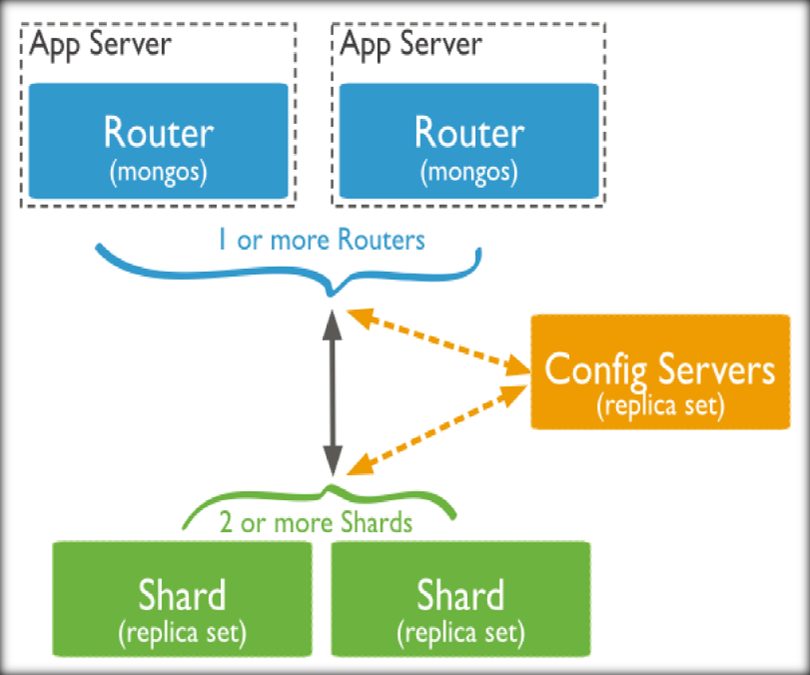
| 组件 | 说明 |
|---|---|
| Config Server | 存储集群所有节点、分片数据路由信息。默认需要配置3个Config Server节点。 |
| Mongos | 提供对外应用访问,所有操作均通过mongos执行。一般有多个mongos节点。数据迁移和数据自动平衡。mongos本身没有任何数据,他也不知道该怎么处理这数据,去找config server |
| Mongod | 存储应用数据记录。一般有多个Mongod节点,达到数据分片目的。真正的数据存储位置,以chunk为单位存数据。 |
Mongos本身并不持久化数据,Sharded cluster所有的元数据都会存储到Config Server,而用户的数据会议分散存储到各个shard。Mongos启动后,会从配置服务器加载元数据,开始提供服务,将用户的请求正确路由到对应的碎片。
2 集群中数据分布
2.1 Chunk是什么
在一个shard server内部,MongoDB还是会把数据分为chunks,每个chunk代表这个shard server内部一部分数据。chunk的产生,会有以下两个用途:
Splitting****:当一个chunk的大小超过配置中的chunk size时,MongoDB的后台进程会把这个chunk切分成更小的chunk,从而避免chunk过大的情况
Balancing****:在MongoDB中,balancer是一个后台进程,负责chunk的迁移,从而均衡各个shard server的负载,系统初始1个chunk,chunk size默认值64M,生产库上选择适合业务的chunk size是最好的。ongoDB会自动拆分和迁移chunks。
分片集群的数据分布(shard****节点)
(1)使用chunk来存储数据
(2)进群搭建完成之后,默认开启一个chunk,大小是64M,
(3)存储需求超过64M,chunk会进行分裂,如果单位时间存储需求很大,设置更大的chunk
(4)chunk会被自动均衡迁移。
2.2 chunksize的选择
适合业务的chunksize是最好的。
chunk的分裂和迁移非常消耗IO资源;chunk分裂的时机:在插入和更新,读数据不会分裂。
chunksize****的选择:
小的chunksize:数据均衡是迁移速度快,数据分布更均匀。数据分裂频繁,路由节点消耗更多资源。大的chunksize:数据分裂少。数据块移动集中消耗IO资源。通常100-200M
2.3 chunk分裂及迁移
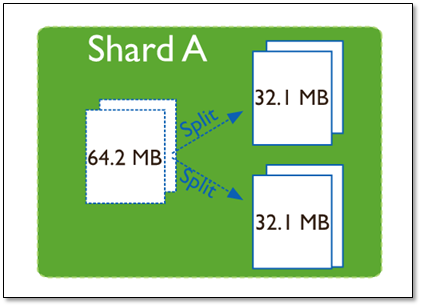
随着数据的增长,其中的数据大小超过了配置的chunk size,默认是64M,则这个chunk就会分裂成两个。数据的增长会让chunk分裂得越来越多。
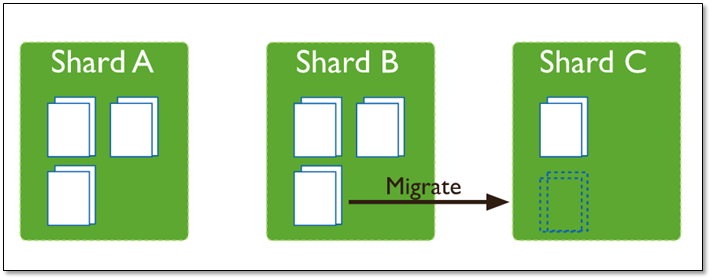
这时候,各个shard 上的chunk数量就会不平衡。这时候,mongos中的一个组件balancer 就会执行自动平衡。把chunk从chunk数量最多的shard节点挪动到数量最少的节点。
chunkSize 对分裂及迁移的影响
MongoDB 默认的 chunkSize 为64MB,如无特殊需求,建议保持默认值;chunkSize 会直接影响到 chunk 分裂、迁移的行为。
chunkSize 越小,chunk 分裂及迁移越多,数据分布越均衡;反之,chunkSize 越大,chunk 分裂及迁移会更少,但可能导致数据分布不均。
chunkSize 太小,容易出现 jumbo chunk(即shardKey 的某个取值出现频率很高,这些文档只能放到一个 chunk 里,无法再分裂)而无法迁移;chunkSize 越大,则可能出现 chunk 内文档数太多(chunk 内文档数不能超过 250000 )而无法迁移。
chunk 自动分裂只会在数据写入时触发,所以如果将 chunkSize 改小,系统需要一定的时间来将 chunk 分裂到指定的大小。
chunk 只会分裂,不会合并,所以即使将 chunkSize 改大,现有的 chunk 数量不会减少,但 chunk 大小会随着写入不断增长,直到达到目标大小。
3 数据区分
3.1 分片键shard key
MongoDB中数据的分片是、以集合为基本单位的,集合中的数据通过片键(Shard key)被分成多部分。其实片键就是在集合中选一个键,用该键的值作为数据拆分的依据。
所以一个好的片键对分片至关重要。片键必须是一个索引,通过sh.shardCollection加会自动创建索引(前提是此集合不存在的情况下)。一个自增的片键对写入和数据均匀分布就不是很好,因为自增的片键总会在一个分片上写入,后续达到某个阀值可能会写到别的分片。但是按照片键查询会非常高效。
随机片键对数据的均匀分布效果很好。注意尽量避免在多个分片上进行查询。在所有分片上查询,mongos会对结果进行归并排序。
对集合进行分片时,你需要选择一个片键,片键是每条记录都必须包含的,且建立了索引的单个字段或复合字段,MongoDB按照片键将数据划分到不同的数据块中,并将数据块均衡地分布到所有分片中。
为了按照片键划分数据块,MongoDB使用基于范围的分片方式或者 基于哈希的分片方式。
注意:
分片键是不可变。
分片键必须有索引。
分片键大小限制512bytes。
分片键用于路由查询。
MongoDB不接受已进行collection级分片的collection上插入无分片
键的文档(也不支持空值插入)
3.2 以范围为基础的分片Sharded Cluster
Sharded Cluster支持将单个集合的数据分散存储在多shard上,用户可以指定根据集合内文档的某个字段即shard key来进行范围分片(range sharding)。
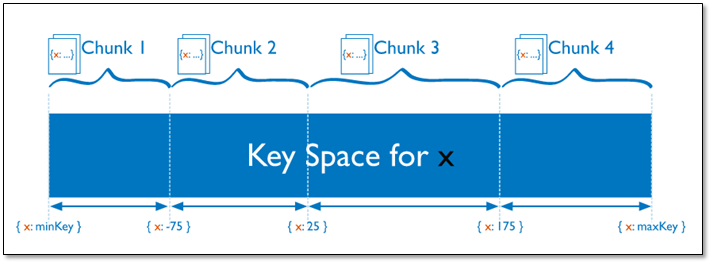
对于基于范围的分片,MongoDB按照片键的范围把数据分成不同部分。
假设有一个数字的片键:想象一个从负无穷到正无穷的直线,每一个片键的值都在直线上画了一个点。MongoDB把这条直线划分为更短的不重叠的片段,并称之为数据块,每个数据块包含了片键在一定范围内的数据。在使用片键做范围划分的系统中,拥有”相近”片键的文档很可能存储在同一个数据块中,因此也会存储在同一个分片中。
3.3 基于哈希的分片
分片过程中利用哈希索引作为分片的单个键,且哈希分片的片键只能使用一个字段,而基于哈希片键最大的好处就是保证数据在各个节点分布基本均匀。
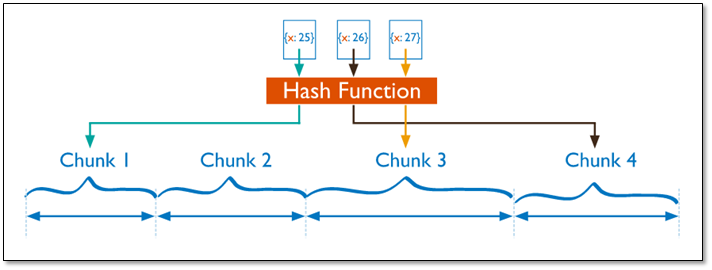
对于基于哈希的分片,MongoDB计算一个字段的哈希值,并用这个哈希值来创建数据块。在使用基于哈希分片的系统中,拥有”相近”片键的文档很可能不会存储在同一个数据块中,因此数据的分离性更好一些。
Hash分片与范围分片互补,能将文档随机的分散到各个chunk,充分的扩展写能力,弥补了范围分片的不足,但不能高效的服务范围查询,所有的范围查询要分发到后端所有的Shard才能找出满足条件的文档。
3.4 分片键选择建议
1****、递增的sharding key
数据文件挪动小。(优势)
因为数据文件递增,所以会把insert的写IO永久放在最后一片上,造成最后一片的写热点。同时,随着最后一片的数据量增大,将不断的发生迁移至之前的片上。
2****、随机的sharding key
数据分布均匀,insert的写IO均匀分布在多个片上。(优势)
大量的随机IO,磁盘不堪重荷。
3****、混合型key
大方向随机递增,小范围随机分布。
为了防止出现大量的chunk均衡迁移,可能造成的IO压力。我们需要设置合理分片使用策略(片键的选择、分片算法(range、hash))
分片注意:
分片键是不可变、分片键必须有索引、分片键大小限制512bytes、分片键用于路由查询。
MongoDB不接受已进行collection级分片的collection上插入无分片键的文档(也不支持空值插入)
4.部署分片集群
# 10个实例:38017-38026
# configserver:
3台构成的复制集(1主两从,不支持arbiter)38018-38020(复制集名字configsvr)
# shard节点:
sh1:38021-23 (1主两从,其中一个节点为arbiter,复制集名字sh1)
sh2:38024-26 (1主两从,其中一个节点为arbiter,复制集名字sh2)
# shard复制集配置:
# 1.目录创建:
mkdir -p /mongodb/38021/conf /mongodb/38021/log /mongodb/38021/data
mkdir -p /mongodb/38022/conf /mongodb/38022/log /mongodb/38022/data
mkdir -p /mongodb/38023/conf /mongodb/38023/log /mongodb/38023/data
mkdir -p /mongodb/38024/conf /mongodb/38024/log /mongodb/38024/data
mkdir -p /mongodb/38025/conf /mongodb/38025/log /mongodb/38025/data
mkdir -p /mongodb/38026/conf /mongodb/38026/log /mongodb/38026/data
# 2.修改配置文件:
# sh1:
cat >> /mongodb/38021/conf/mongodb.conf <<EOF
systemLog:
destination: file
path: /mongodb/38021/log/mongodb.log
logAppend: true
storage:
journal:
enabled: true
dbPath: /mongodb/38021/data
directoryPerDB: true
#engine: wiredTiger
wiredTiger:
engineConfig:
cacheSizeGB: 1
directoryForIndexes: true
collectionConfig:
blockCompressor: zlib
indexConfig:
prefixCompression: true
net:
port: 38021
replication:
oplogSizeMB: 2048
replSetName: sh1
sharding:
clusterRole: shardsvr
processManagement:
fork: true
EOF
cp /mongodb/38021/conf/mongodb.conf /mongodb/38022/conf/
cp /mongodb/38021/conf/mongodb.conf /mongodb/38023/conf/
sed 's#38021#38022#g' /mongodb/38022/conf/mongodb.conf -i
sed 's#38021#38023#g' /mongodb/38023/conf/mongodb.conf -i
# sh2:
cat >> /mongodb/38024/conf/mongodb.conf << EOF
systemLog:
destination: file
path: /mongodb/38024/log/mongodb.log
logAppend: true
storage:
journal:
enabled: true
dbPath: /mongodb/38024/data
directoryPerDB: true
wiredTiger:
engineConfig:
cacheSizeGB: 1
directoryForIndexes: true
collectionConfig:
blockCompressor: zlib
indexConfig:
prefixCompression: true
net:
port: 38024
replication:
oplogSizeMB: 2048
replSetName: sh2
sharding:
clusterRole: shardsvr
processManagement:
fork: true
EOF
cp /mongodb/38024/conf/mongodb.conf /mongodb/38025/conf/
cp /mongodb/38024/conf/mongodb.conf /mongodb/38026/conf/
sed 's#38024#38025#g' /mongodb/38025/conf/mongodb.conf -i
sed 's#38024#38026#g' /mongodb/38026/conf/mongodb.conf -i
# 3启动所有节点,并搭建复制集:
mongod -f /mongodb/38021/conf/mongodb.conf
mongod -f /mongodb/38022/conf/mongodb.conf
mongod -f /mongodb/38023/conf/mongodb.conf
mongod -f /mongodb/38024/conf/mongodb.conf
mongod -f /mongodb/38025/conf/mongodb.conf
mongod -f /mongodb/38026/conf/mongodb.conf
# 搭建sh1复制集
mongo --port 38021
use admin
config = {_id: 'sh1', members: [
{_id: 0, host: '10.0.0.200:38021'},
{_id: 1, host: '10.0.0.200:38022'},
{_id: 2, host: '10.0.0.200:38023',"arbiterOnly":true}]
}
rs.initiate(config)
# 搭建sh2复制集
mongo --port 38024
use admin
config = {_id: 'sh2', members: [
{_id: 0, host: '10.0.0.200:38024'},
{_id: 1, host: '10.0.0.200:38025'},
{_id: 2, host: '10.0.0.200:38026',"arbiterOnly":true}]
}
rs.initiate(config)
# config节点配置:
# 1目录创建:
mkdir -p /mongodb/38018/conf /mongodb/38018/log /mongodb/38018/data
mkdir -p /mongodb/38019/conf /mongodb/38019/log /mongodb/38019/data
mkdir -p /mongodb/38020/conf /mongodb/38020/log /mongodb/38020/data
# 2修改配置文件:
cat >> /mongodb/38018/conf/mongodb.conf << EOF
systemLog:
destination: file
path: /mongodb/38018/log/mongodb.conf
logAppend: true
storage:
journal:
enabled: true
dbPath: /mongodb/38018/data
directoryPerDB: true
#engine: wiredTiger
wiredTiger:
engineConfig:
cacheSizeGB: 1
directoryForIndexes: true
collectionConfig:
blockCompressor: zlib
indexConfig:
prefixCompression: true
net:
port: 38018
replication:
oplogSizeMB: 2048
replSetName: configReplSet
sharding:
clusterRole: configsvr
processManagement:
fork: true
EOF
cp /mongodb/38018/conf/mongodb.conf /mongodb/38019/conf/
cp /mongodb/38018/conf/mongodb.conf /mongodb/38020/conf/
sed 's#38018#38019#g' /mongodb/38019/conf/mongodb.conf -i
sed 's#38018#38020#g' /mongodb/38020/conf/mongodb.conf -i
# 3启动节点,并配置复制集
mongod -f /mongodb/38018/conf/mongodb.conf
mongod -f /mongodb/38019/conf/mongodb.conf
mongod -f /mongodb/38020/conf/mongodb.conf
mongo --port 38018
use admin
config = {_id: 'configReplSet', members: [
{_id: 0, host: '10.0.0.200:38018'},
{_id: 1, host: '10.0.0.200:38019'},
{_id: 2, host: '10.0.0.200:38020'}]
}
rs.initiate(config)
# 注:configserver 可以是一个节点,官方建议复制集。configserver不能有arbiter。
# 新版本中,要求必须是复制集。
# 注:mongodb 3.4之后,虽然要求config server为replica set,但是不支持arbiter
=============================================================================
# mongos节点配置:
# 1.创建目录:
mkdir -p /mongodb/38017/conf /mongodb/38017/log
# 2.配置文件:
cat >> /mongodb/38017/conf/mongos.conf <<EOF
systemLog:
destination: file
path: /mongodb/38017/log/mongos.log
logAppend: true
net:
port: 38017
sharding:
configDB: configReplSet/10.0.0.200:38018,10.0.0.200:38019,10.0.0.200:38020
processManagement:
fork: true
EOF
# 3启动mongos
mongos -f /mongodb/38017/conf/mongos.conf
# 除了mongos知道有config以外,都没有任何联系
# 分片集群操作:
# 连接到其中一个mongos(10.0.0.200),做以下配置
# 1.连接到mongs的admin数据库
su - mongod
mongo 10.0.0.200:38017/admin
# 2.添加分片
db.runCommand( { addshard : "sh1/10.0.0.200:38021,10.0.0.200:38022,10.0.0.200:38023",name:"shard1"} )
db.runCommand( { addshard : "sh2/10.0.0.200:38024,10.0.0.200:38025,10.0.0.200:38026",name:"shard2"} )
# 3.列出分片
mongos> db.runCommand( { listshards : 1 } )
# 4.整体状态查看
mongos> sh.status();
# 现在都搭建好了,除了分片功能以外
5.配置Hash分片
# 对oldguo库下的vast大表进行hash
# 创建哈希索引
# 1.对于oldguo开启分片功能
# 首先连接到mongos
mongo --port 38017 admin
use admin
admin> db.runCommand( { enablesharding : "oldguo" } )
# 2.对于oldguo库下的vast表建立hash索引
use oldguo
oldguo> db.vast.ensureIndex( { id: "hashed" } )
# 3.开启分片
use admin
admin > sh.shardCollection( "oldguo.vast", { id: "hashed" } )
# 4.录入10w行数据测试
use oldguo
for(i=1;i<=100000;i++){ db.vast.insert({"id":i,"name":"shenzheng","age":70,"date":new Date()}); }
# 5.hash分片结果测试
mongo --port 38021
use oldguo
db.vast.count();
mongo --port 38024
use oldguo
db.vast.count();
# 6.判断是否Shard集群
admin> db.runCommand({ isdbgrid : 1})
# 7.列出所有分片信息
admin> db.runCommand({ listshards : 1})
# 8.列出开启分片的数据库
admin> use config
config> db.databases.find( { "partitioned": true } )
或者:
config> db.databases.find() //列出所有数据库分片情况
# 9.查看分片的片键
config> db.collections.find().pretty()
{
"_id" : "test.vast",
"lastmodEpoch" : ObjectId("58a599f19c898bbfb818b63c"),
"lastmod" : ISODate("1970-02-19T17:02:47.296Z"),
"dropped" : false,
"key" : {
"id" : 1
},
"unique" : false
}
# 10.查看分片的详细信息
admin> db.printShardingStatus()
或
admin> sh.status()
# 11.删除分片节点(谨慎)
(1)确认blance是否在工作
sh.getBalancerState()
(2)删除shard2节点(谨慎)
mongos> db.runCommand( { removeShard: "shard2" } )
注意:删除操作一定会立即触发blancer。
七、备份
1、备份恢复工具介绍
- mongoexport/mongoimport
JSON虽然具有较好的跨版本通用性,但其只保留了数据部分,不保留索引,账户等其他基础信息。使用时应该注意。跨平台时推荐使用csv格式,csv是几乎所有的数据库都支持的格式
- mongodump/mongorestore
导入/导出的是BSON格式。
BSON则是二进制文件,体积小但对人类几乎没有可读性。
在一些mongodb版本之间,BSON格式可能会随版本不同而有所不同,所以不同版本之间用mongodump/mongorestore可能不会成功,具体要看版本之间的兼容性。当无法使用BSON进行跨版本的数据迁移的时候,使用JSON格式即mongoexport/mongoimport是一个可选项。
2.导出/mongoexport
Mongodb中的mongoexport工具可以把一个collection导出成JSON格式或CSV格式的文件。JSON可读性强但体积较大。
可以通过参数指定导出的数据项,也可以根据指定的条件导出数据。
特点:
(1)版本差异较大
(2)异构平台数据迁移
# 语法
mongoexport --help
参数说明:
-h:指明数据库宿主机的IP
-u:指明数据库的用户名
-p:指明数据库的密码
-d:指明数据库的名字
-c:指明collection的名字
-f:指明要导出那些列
-o:指明到要导出的文件名
-q:指明导出数据的过滤条件
--authenticationDatabase:验证库
# 1.单表备份至json格式
mongoexport -uroot -proot123 --port 27017 --authenticationDatabase admin -d oldguo -c log -o /mongodb/log.json
# 注:备份文件的名字可以自定义,默认导出了JSON格式的数据。
# 2. 单表备份至csv格式
# 如果我们需要导出CSV格式的数据,则需要使用----type=csv参数:
mongoexport -uroot -proot123 --port 27017 --authenticationDatabase admin -d oldguo -c log --type=csv -f uid,name,age,date -o /mongodb/log.csv
3.导入/mongoimport
Mongodb中的mongoimport工具可以把一个特定格式文件中的内容导入到指定的collection中。该工具可以导入JSON格式数据,也可以导入CSV格式数据。具体使用如下所示:
$ mongoimport --help
# 参数说明:
-h:指明数据库宿主机的IP
-u:指明数据库的用户名
-p:指明数据库的密码
-d:指明数据库的名字
-c:指明collection的名字
-f:指明要导入那些列
-j, --numInsertionWorkers=<number> number of insert operations to run concurrently (defaults to 1)
# 数据恢复:
# 1.恢复json格式表数据到log1,
mongoimport -uroot -proot123 --port 27017 --authenticationDatabase admin -d oldguo -c log1 /mongodb/log.json
# 2.恢复csv格式的文件到log2
上面演示的是导入JSON格式的文件中的内容,如果要导入CSV格式文件中的内容,则需要通过--type参数指定导入格式,具体如下所示:
(1)csv格式的文件头行,有列名字
# --headerline:指明第一行是列名,不需要导入。
# csv导出是第一行是列名,所以导入时要特别注意第一行不能作为数据导入
mongoimport -uroot -proot123 --port 27017 --authenticationDatabase admin -d oldguo -c log2 --type=csv --headerline --file /mongodb/log.csv
(2)csv格式的文件头行,没有列名字
mongoimport -uroot -proot123 --port 27017 --authenticationDatabase admin -d oldguo -c log3 --type=csv -f id,name,age,date --file /mongodb/log1.csv
4.异构平台迁移
# mysql -----> mongodb
# world数据库下city表进行导出,导入到mongodb
# 1.mysql开启安全路径
# 通过secure_file_priv 来完成对导入|导出的限制
# 限制mysqld 的导入 | 导出 只能发生在/tmp/目录下
vim /etc/my.cnf --->添加以下配置
secure-file-priv=/tmp
# 重启数据库生效
/etc/init.d/mysqld restart
# 2.导出mysql的city表数据
source /root/world.sql
select * from world.city into outfile '/tmp/city1.csv' fields terminated by ',';
# 3.处理备份文件
# 添加第一行列名信息
vim /tmp/city.csv
ID,Name,CountryCode,District,Population
# 4.在mongodb中导入备份
mongoimport -uroot -proot123 --port 27017 --authenticationDatabase admin -d world -c city --type=csv -f ID,Name,CountryCode,District,Population --file /tmp/city1.csv
八、mongodbAPI
# 单机链接
from pymongo import MongoClient
conn = MongoClient('localhost', 27017)
client = MongoClient('mongodb://localhost:27017/')
# 复制集 replication set 链接
from pymongo import MongoReplicaSetClient
conn = MongoReplicaSetClient("10.0.0.200:28017,10.0.0.200:28018,10.0.0.200:28019", replicaset='my_repl')
# replicaset:复制集主机名
print (conn)
print (conn.primary)
print (conn.seeds)
print (conn.secondaries)
print (conn.read_preference)
print (conn.server_info())
# 分片集群
conn = pymongo.Connection('192.168.1.1', 27017)
db = conn['test'] #假定名为test的db已经存在
db_admin = conn['admin'] #command的执行必须通过名为admin的db才能进行
col_data = db["data"]
for i in range(1, 50):
col_data.insert({'_id':i, 'value':(i*200)}) #插入测试数据,必须在分片之前保证shard key的存在,本例中为_id
db_admin.command('enablesharding', 'test') #确认目标db的sharding功能开启(这行代码一个数据库只执行一次有效,如果已经设置,则会抛出异常)
db_admin.command('shardcollection', 'test.data', key = {'_id':1}) #指定目标collection和对应的shard key(这行一个表执行一次,如果出现多表,表名不同的情况下,应该每张表都执行一次)
conn.close()
# 如何查看已经分片成功:
在linux中进入mongo命令界面,
use test
db.test.data.stats()
会打印出分片信息。
并且shard key可以指定多个,同建立复合索引类似:
db_admin.command('shardcollection', 'test.data', key = {'_id':1, 'a':1, 'b':1})
