ELK学习之Logstash篇
Logstash在ELK这一整套解决方案中作为数据采集终端,支持对接Kafka、数据库(MySQL、Oracle)、文件等等。
而在Logstash内部的数据流转,主要经过三个环节:input -> filter -> output,顾名思义就是输入、过滤(处理)以及输出。接下来通过一个实际的操作案例来感受一下Logstash内部的数据流转过程。
首先在官网下载Logstash的运行包,https://www.elastic.co/fr/downloads/logstash,由于我本地是Windows环境,因此选择下载Windows对应的包:

将下载完毕的压缩包logstash-7.14.1-windows-x86_64.zip进行解压之后进入bin目录并创建logstash.conf文件用于对input、filter以及output进行相应的配置:

接下来在配置文件中进行响应的配置,直接给出完整的例子并在后文进行详解:
input { file { path => "D:/logstash-7.14.1/test-log/test.log" start_position => beginning } } filter { grok { match => { "message" => "(?<Time>[0-9]{6}\.[0-9]{3})\[(?<LogLevel>\d)\]\[(?<ThreadNo>[0-9]*)\].*(?<Tag>FindResponseByPage)\[fund\_account\=(?<FundAccount>[0-9]*)" } } if [Tag] != "FindResponseByPage" { drop {} } } output { file { path => "D:/logstash-7.14.1/test-log/logstash.log" codec => line { format => "Time: %{Time}, LogLevel: %{LogLevel}, ThreadNo: %{ThreadNo}, Tag: %{Tag}, FundAccount: %{FundAccount}" } } }
input 中添加 file 项表示通过文件进行输入,path 为文件的绝对路径(如果配置非绝对路径,Logstash会给出报错提示),start_position => beginning 表示每次从文件头开始读取。
filter中则进行对输入数据的相关处理进行配置(filter可以不配置,效果是原样输出)。
grok是Logstash的核心插件之一,可以根据配置的表达式进行数据筛选并存入指定的变量名中。grok提供了一系列标准的匹配模板,不过由于grok底层也是基于正则表达式,因此也可以直接输入正则表达式进行匹配。
这里搬运一个官网上的例子:
55.3.244.1 GET /index.html 15824 0.043
针对上述格式的数据,可以通过grok提供的标准表达式模板进行匹配:
%{IP:client} %{WORD:method} %{URIPATHPARAM:request} %{NUMBER:bytes} %{NUMBER:duration}
示例中,IP为预定义的模板,client为准备存入的变量名。很容易看出,grok的标准语法如下:
%{SYNTAX:SEMANTIC}
SYNTAX:匹配值的类型,例如15824可以用NUMBER类型所匹配,55.3.244.1可以使用IP类型匹配。
SEMANTIC:存储该值的一个变量名,例如GET可能代表的是REST请求中指定的方法,那么用method来进行保存。
当然,像上方的配置文件示例中一样,通过原生的正则表达式来进行匹配也可以,不使用预定义模板的格式如下:
(?<field_name>the pattern here)
其中field_name表示保存匹配到内容的变量名,后面部分则是表达式,例如:
093124.597[0][30100]
对应的匹配表达式为:
?<Time>[0-9]{6}\.[0-9]{3})\[(?<LogLevel>\d)\]\[(?<ThreadNo>[0-9]*)\]
根据匹配到的值可以通过drop进行一个筛选,例如只需要LogLevel值为error的数据,可以在filter中添加如下配置:
if [LogLevel] != "error" { drop {} }
output这里同样配置了file,也就是将输入的数据经过处理后输出到另一个指定文件中,path为输出文件的绝对路径,format则指定了输出的格式。
接下来启动Logstash来观察一下效果,在bin目录打开命令行并输入启动命令:
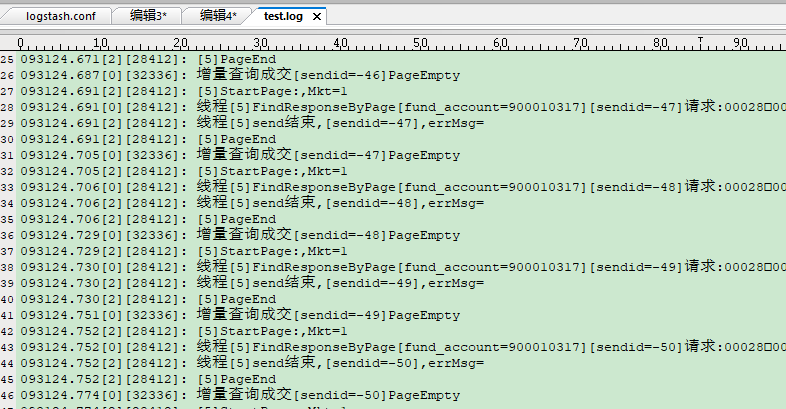
再看一下输入文件和输出文件中的效果,首先是输入文件test.log:
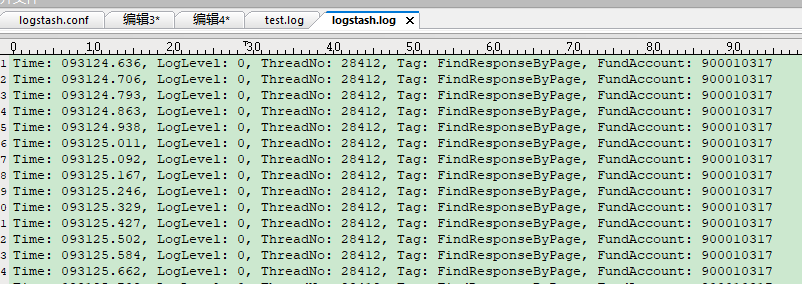
接下来是输出文件logstash.log,成功达到了了字段匹配以及筛选的效果:
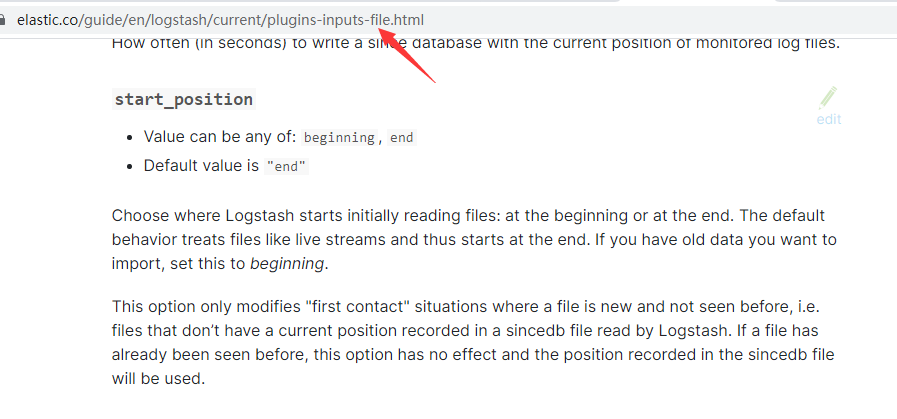
最后补充一点,Logstash的插件非常多,配置项也非常多。建议直接在官网进行学习,再介绍下如何阅读官网的配置详解:
导航栏右侧有input、filter、output等插件的栏目,通过点击导航栏或者左侧正文部分的具体配置项,可以点击进一步查看配置详情: