
第一次个人编程作业
| 这个作业属于哪个课程 | 22级计科12班 |
|---|---|
| 这个作业要求在哪里 | 作业要求 |
| 这个作业的目标 | 设计一个论文查重算法,学习PSP表格和commit规范,学习单元测试 |
Github项目链接
一、PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 60 | 60 |
| Estimate | 估计这个任务需要多少时间 | 400 | 450 |
| Development | 开发 | 300 | 320 |
| Analysis | 需求分析 (包括学习新技术) | 100 | 120 |
| Design Spec | 生成设计文档 | 30 | 30 |
| Design Review | 设计复审 | 30 | 40 |
| Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 30 | 50 |
| Design | 具体设计 | 60 | 60 |
| Coding | 具体编码 | 120 | 150 |
| Code Review | 代码复审 | 60 | 80 |
| Test | 测试(自我测试,修改代码,提交修改) | 60 | 60 |
| Reporting | 报告 | 60 | 80 |
| Test Repor | 测试报告 | 30 | 50 |
| Size Measurement | 计算工作量 | 30 | 30 |
| Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 30 | 30 |
| 合计 | 1400 | 1610 |
二、计算模块接口的设计与实现过程
项目结构
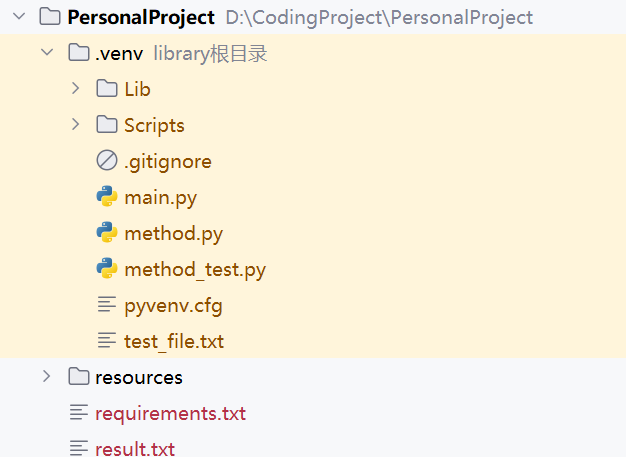
函数设计
def hash_value(s):生成 64 位哈希值
def simhash(text, hash_bits=64):计算文本的 SimHash
def hamming_distance(hash1, hash2):计算两个SimHash的汉明距离
def read_file(file_path: str) -> str:从文件中读取中文文本内容
def preprocess_text(text: str) -> str:对中文文本进行去除标点以及分词处理
流程分析
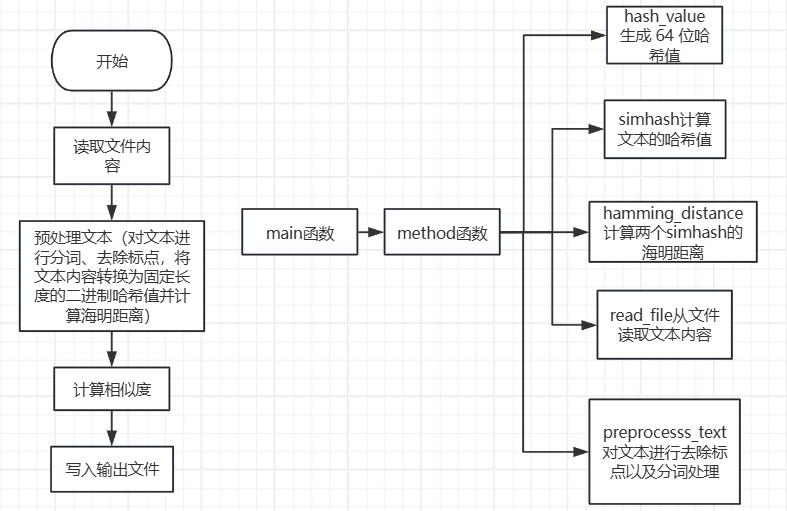
算法关键
本次论文查重算法采用的是Simhash算法,它是一种用于近似字符串相似性检测的哈希算法,其核心思想是将文本内容转换为固定长度的二进制哈希值,从而可以用这些哈希值来计算文本之间的相似性。除此之外,这次设计还调用了jieba库,它是一个用于中文分词的 Python 库。它能够将一段连续的中文文本切分成一个个词语,适用于文本分析和自然语言处理。
三、计算模块接口部分的性能改进
优化前:
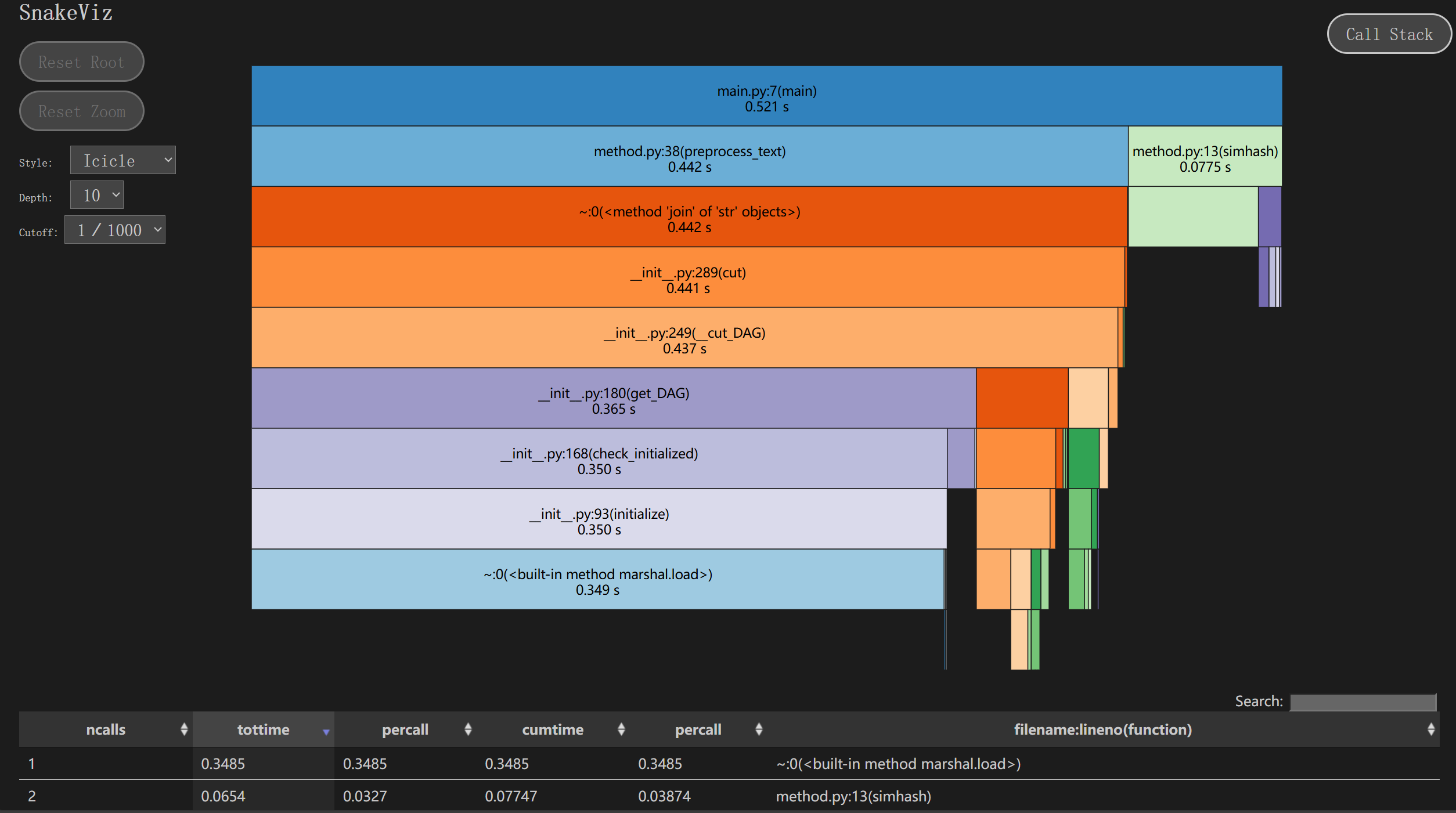
由图可知,main函数模块消耗的时间最多。
优化后:
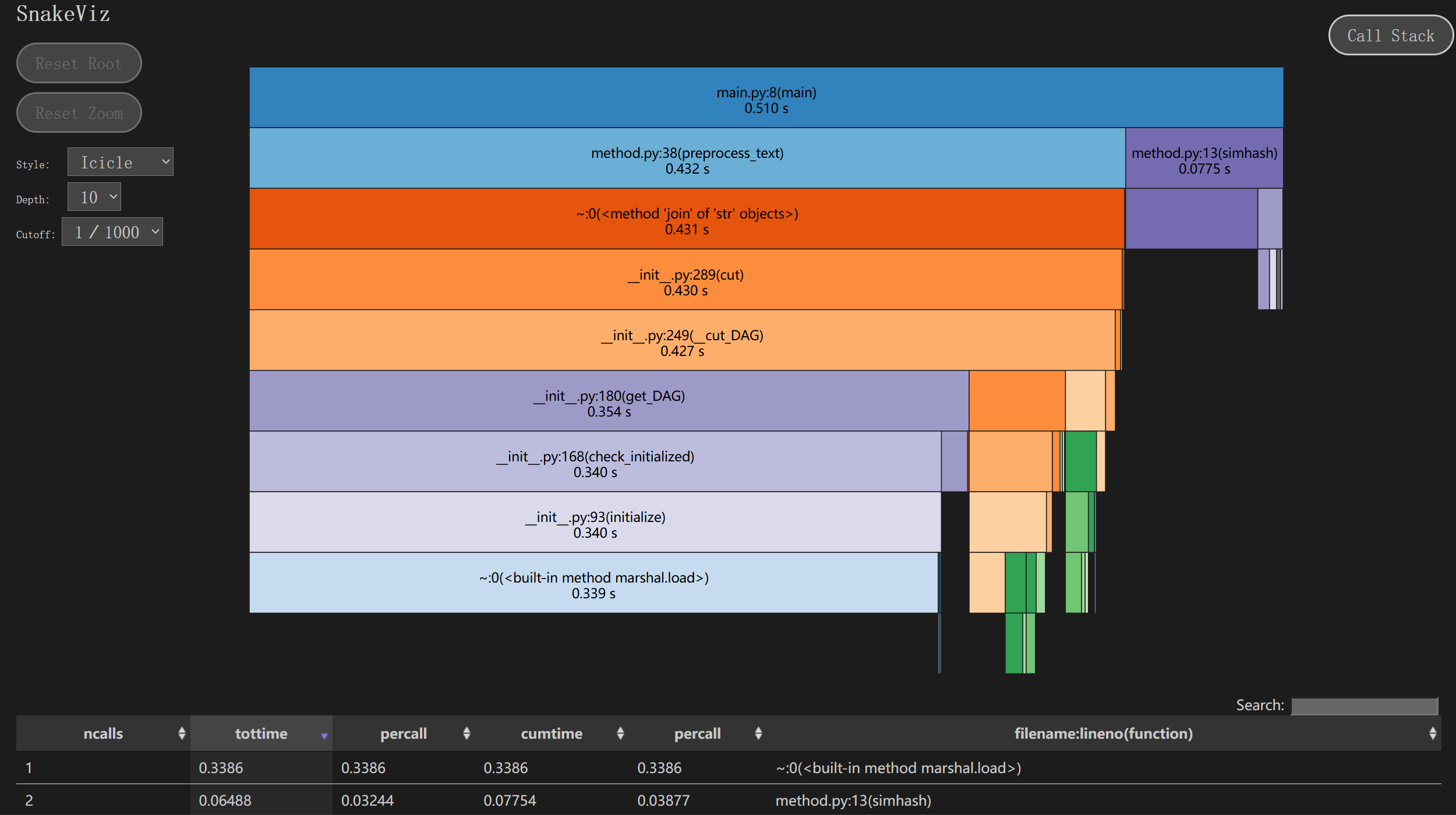
我的改进思路是减少文件操作的开销,将文件读取操作集中在程序的开头,这样文件的内容只被读取一次,并存储在内存中进行后续处理。
四、计算模块部分单元测试展示
部分单元测试代码
def test_hash_value(self):
# 测试 hash_value 函数
s = 'hello'
expected = int(hashlib.md5(s.encode('utf-8')).hexdigest(), 16)
result = method.hash_value(s)
self.assertEqual(result, expected, "hash_value 函数的结果不匹配")
def test_hamming_distance(self):
# 测试 hamming_distance 函数
hash1 = 0b10101010
hash2 = 0b01010101
expected_distance = bin(hash1 ^ hash2).count('1')
result = method.hamming_distance(hash1, hash2)
self.assertEqual(result, expected_distance, "hamming_distance 函数的结果不匹配")
def test_simhash(self):
# 测试 simhash 函数
text = '我 喜欢 编程'
processed_text = method.preprocess_text(text)
expected = self.compute_simhash_for_text(processed_text)
result = method.simhash(text)
self.assertEqual(result, expected, "simhash 函数的结果不匹配")
def compute_simhash_for_text(self, text):
# 辅助函数计算 simhash 值用于测试
v = [0] * 64
for word in text.split():
h = method.hash_value(word)
for i in range(64):
if h & (1 << i):
v[i] += 1
else:
v[i] -= 1
fingerprint = 0
for i in range(64):
if v[i] >= 0:
fingerprint |= (1 << i)
return fingerprint
def test_read_file(self):
# 测试 read_file 函数
with open('test_file.txt', 'w', encoding='utf-8') as file:
file.write('测试文件内容')
result = method.read_file('test_file.txt')
self.assertEqual(result, '测试文件内容', "read_file 函数的结果不匹配")
def test_preprocess_text(self):
# 测试 preprocess_text 函数
text = '我 爱 编程,编程很好!'
expected = '我 爱 编程 编程 很好'
result = method.preprocess_text(text)
self.assertEqual(result, expected, "preprocess_text 函数的结果不匹配")
测试函数说明
test_hash_value:
测试数据:使用字符串 'hello',计算其 MD5 哈希值,并将其与 method.hash_value 函数的返回值进行比较。
思路:通过 hashlib.md5 计算预期值,将其与 method.hash_value 的结果进行比对。
test_hamming_distance:
测试数据:使用两个二进制数 0b10101010 和 0b01010101,计算其汉明距离,并与 method.hamming_distance 的结果进行比较。
思路:通过异或操作计算两个数的不同位数,即汉明距离,并与 method.hamming_distance 的结果比对。
test_simhash:
测试数据:使用文本 '我 喜欢 编程',将其预处理并计算 SimHash 值。
思路:首先调用 method.preprocess_text 对文本进行预处理,然后计算文本的 SimHash 值,并与 compute_simhash_for_text 计算的预期值进行比对。
compute_simhash_for_text:
测试数据:预处理后的文本。
思路:通过对每个词的哈希值进行加权,计算 SimHash 值。
test_read_file:
测试数据:创建一个包含特定内容的测试文件。
思路:创建文件,写入内容后,读取文件并检查内容是否与预期匹配。
test_preprocess_text:
测试数据:使用文本 '我 爱 编程,编程很好!',对其进行预处理。
思路:对文本进行预处理并检查处理结果是否符合预期。
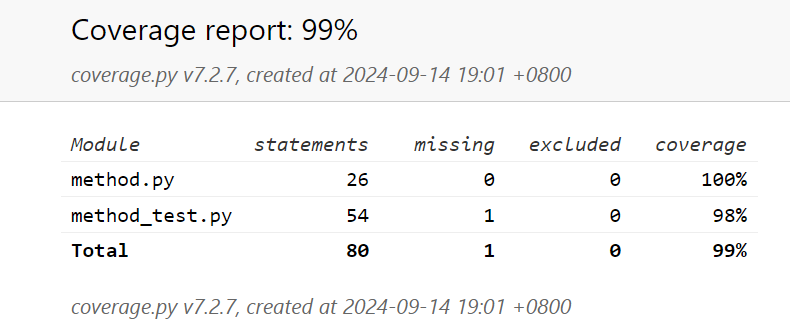
测试覆盖率
五、计算模块部分异常处理说明
hash_value 函数异常处理
- 设计目标:
输入类型检查: 确保输入是字符串,并能够安全地进行编码和哈希计算。 - 可能的异常:
TypeError: 如果传递给 hash_value 的不是字符串。 - 单元测试样例:
import unittest
import hashlib
class TestHashValue(unittest.TestCase):
def test_valid_string(self):
self.assertEqual(hash_value("test"), int(hashlib.md5("test".encode('utf-8')).hexdigest(), 16))
def test_invalid_input(self):
with self.assertRaises(TypeError):
hash_value(123) # 传递非字符串类型
if __name__ == '__main__':
unittest.main()
- 错误场景:
传递非字符串参数: hash_value(123) 应引发 TypeError,因为 hashlib.md5() 期望的是字符串输入。
hamming_distance 函数异常处理
- 设计目标:
输入类型检查: 确保输入是整数,并且能够进行位运算。 - 可能的异常:
TypeError: 如果输入参数不是整数类型。 - 单元测试样例:
class TestHammingDistance(unittest.TestCase):
def test_valid_input(self):
self.assertEqual(hamming_distance(0b1010, 0b1001), 3)
def test_invalid_input(self):
with self.assertRaises(TypeError):
hamming_distance(0b1010, 'not_a_number') # 传递非整数类型
if __name__ == '__main__':
unittest.main()
- 错误场景:
传递非整数参数: hamming_distance(0b1010, 'not_a_number') 应引发 TypeError,因为 ^ 运算符需要整数类型参数。
simhash 函数异常处理
- 设计目标:
输入类型检查: 确保输入是字符串,并且能够进行哈希和位运算。
哈希位数验证: 确保 hash_bits 是一个合理的整数。 - 可能的异常:
TypeError: 如果 text 不是字符串,或者 hash_bits 不是整数。
ValueError: 如果 hash_bits 不是正整数。 - 单元测试样例:
class TestSimhash(unittest.TestCase):
def test_valid_text(self):
text = "this is a test"
result = simhash(text)
self.assertIsInstance(result, int) # 结果应为整数
def test_invalid_text(self):
with self.assertRaises(TypeError):
simhash(12345) # 传递非字符串类型
def test_invalid_hash_bits(self):
with self.assertRaises(ValueError):
simhash("text", hash_bits=-64) # 负值不合法
if __name__ == '__main__':
unittest.main()
- 错误场景:
传递非字符串参数: simhash(12345) 应引发 TypeError,因为 text 应为字符串。
无效的 hash_bits: simhash("text", hash_bits=-64) 应引发 ValueError,因为 hash_bits 必须是正整数。
read_file 函数异常处理
- 设计目标:
文件存在性检查: 确保文件路径有效且文件可读。
文件读取错误处理: 处理文件打开和读取过程中的异常。 - 可能的异常:
FileNotFoundError: 文件不存在时。
UnicodeDecodeError: 文件内容无法按照 UTF-8 编码解码时。 - 单元测试样例:
class TestReadFile(unittest.TestCase):
def test_valid_file(self):
with open('test_file.txt', 'w', encoding='utf-8') as f:
f.write('test content')
self.assertEqual(read_file('test_file.txt'), 'test content')
def test_file_not_found(self):
with self.assertRaises(FileNotFoundError):
read_file('non_existing_file.txt') # 文件不存在
def test_read_error(self):
with open('read_error_file.txt', 'wb') as f:
f.write(b'\x80\x81') # 无法解码的内容
with self.assertRaises(UnicodeDecodeError):
read_file('read_error_file.txt')
if __name__ == '__main__':
unittest.main()
- 错误场景:
文件不存在: read_file('non_existing_file.txt') 应引发 FileNotFoundError。
读取文件编码错误: read_file('read_error_file.txt') 应引发 UnicodeDecodeError,因为文件内容不能用 UTF-8 解码。
preprocess_text 函数异常处理
- 设计目标:
输入类型检查: 确保输入是字符串,并能够进行正则替换和分词。 - 可能的异常:
TypeError: 如果 text 不是字符串。
NameError: 如果 cut 函数未定义。 - 单元测试样例:
class TestPreprocessText(unittest.TestCase):
def test_valid_text(self):
self.assertEqual(preprocess_text('你好,世界!'), '你好 世界')
def test_invalid_text(self):
with self.assertRaises(TypeError):
preprocess_text(12345) # 传递非字符串类型
def test_cut_function_not_defined(self):
with self.assertRaises(NameError):
preprocess_text('text') # 假设 cut 函数未定义
if __name__ == '__main__':
unittest.main()
- 错误场景:
传递非字符串参数: preprocess_text(12345) 应引发 TypeError,因为 text 应为字符串。
未定义的 cut 函数: 如果 cut 函数没有定义,则 preprocess_text('text') 应引发 NameError。
