XML学习笔记
XML
XML简介#
什么是xml?
xml是可扩展的标记性语言
xml的作用?
1. 用来保存数据,而且这些数据具有自我描述性
2. 可以作为项目或者魔抗的配置文件
3. 可以作为网络传输数据的格式(现在以JSON为主)
xml文件示例:
<?xml version="1.0" encoding="utf-8" ?>
<!--
<?xml version="1.0" encoding="utf-8" ?>
以上内容就是xml文件的声明
version="1.0" version 表示xml的版本
encoding="utf-8" encoding表示xml文件本身的编码
-->
<books><!--books 表示多个图书信息-->
<book sn="SN123456"><!-- book表示一个图书信息 sn属性表示图书序列号-->
<name>时间简史</name><!-- name标签表示书名-->
<author>霍金</author><!-- author标签表示作者-->
<price>75</price><!-- price表示图书价格-->
</book>
<book sn="SN123456"><!-- book表示一个图书信息 sn属性表示图书序列号-->
<name>java从入门到放弃</name><!-- name标签表示书名-->
<author>某个不愿意透露姓名的作者</author><!-- author标签表示作者-->
<price>30</price><!-- price表示图书价格-->
</book>
</books>
注意:<?xml version="1.0" encoding="UTF-8"?>中的<?xml要连在一起写,否则会报错
XML语法#
XML注释#
html 和 XML 注释 一样 : <!-- 注释 -->
XML元素#
XML元素指的是从(包括)开始标签直到(包括)结束标签的部分
元素可以包含其他元素、文本或者两者的混合物。元素也可以拥有属性。
元素是指从开始标签到结束标签的内容,例如:<title>java编程思想</title>
XML命名规则#
XML元素必须遵守以下命名规则:
- 名称可以含字母、数字以及其他的字符 例如:
<book id="SN213412341"> <!-- 描述一本书 -->
<author>班导</author> <!-- 描述书的作者信息 -->
<name>java 编程思想</name> <!-- 书名 -->
<price>9.9</price> <!-- 价格 -->
</book>
- 名称不能以数字或者标点符号开始
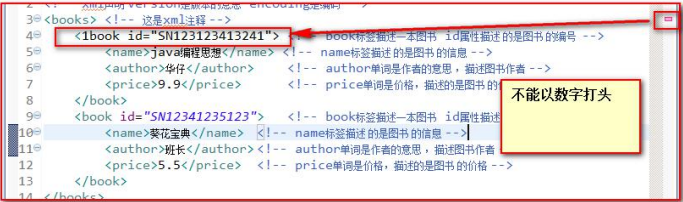
- 名称不能包含空格
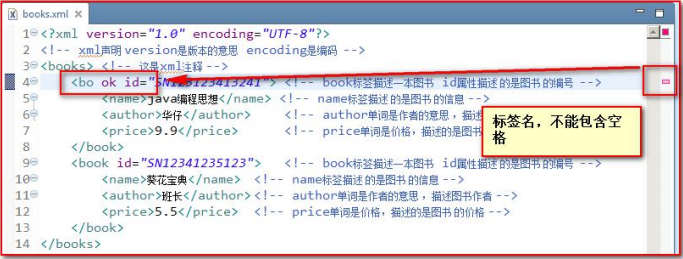
- xml 中的元素(标签)也 分成 单标签和双标签:
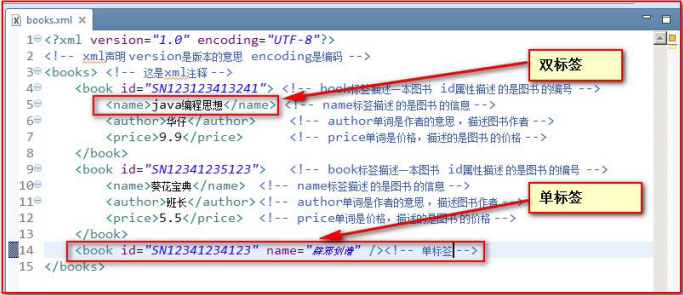
XML属性#
xml 的标签属性和 html 的标签属性是非常类似的,属性可以提供元素的额外信息
在标签上可以书写属性:
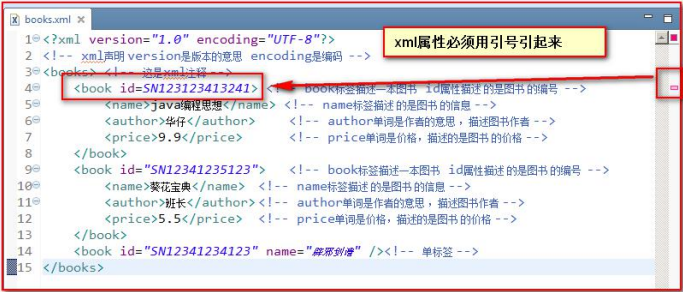
一个标签上可以说些多个属性。每个属性的值必须使用引号引起来
语法规则#
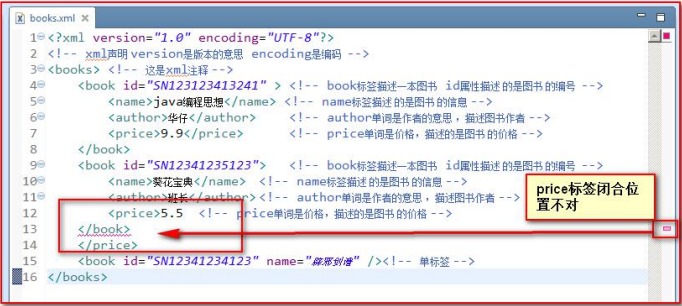
- 所以XML元素都必须有关闭标签(也就是闭合)
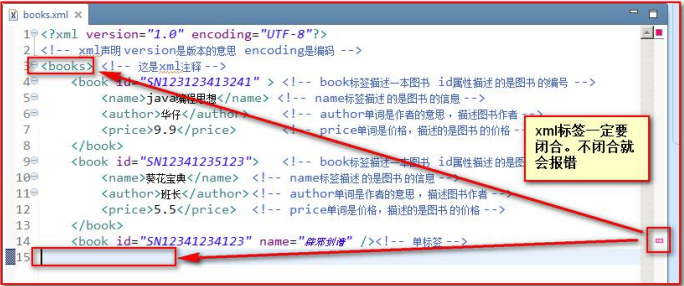
- XML 标签对大小写敏感
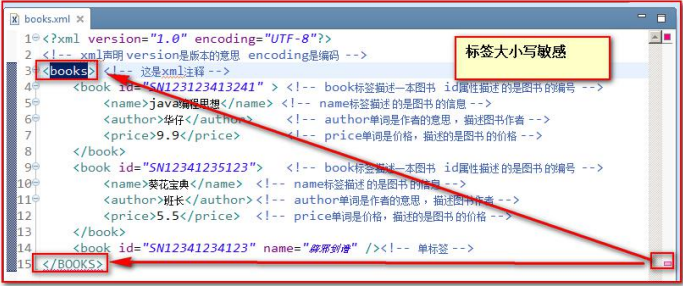
- XML 必须正确地嵌套
-
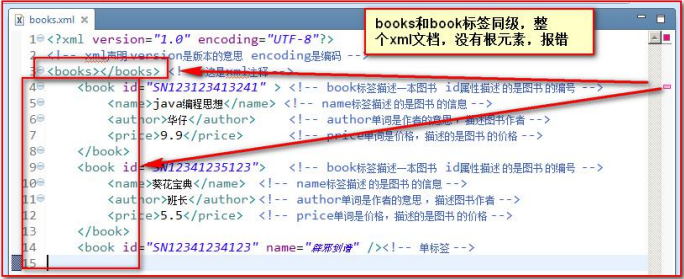
XML 文档必须有根元素
根元素就是顶级元素,没有父标签的元素,叫顶级元素
根元素是没有父标签的顶级元素,而且是唯一一个才行
- XML 的属性值必须加引号

- XML 中的特殊字符
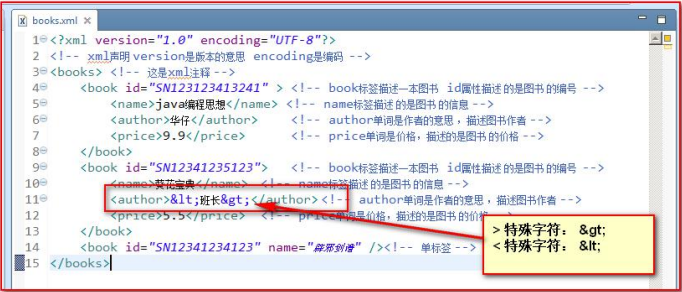
-
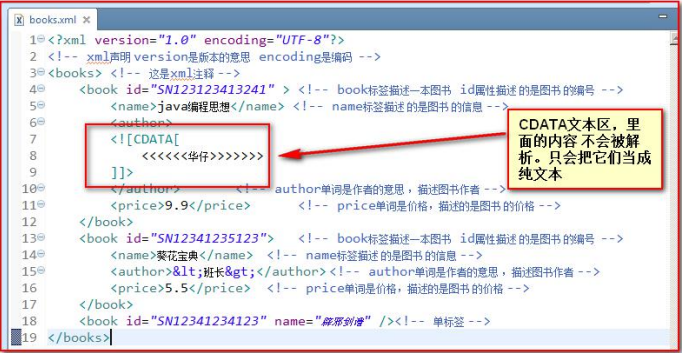
文本区域(CDATA 区)
CDATA 语法可以告诉 xml 解析器, CDATA 里的文本内容,只是纯文本,不需要 xml 语法解析
CDATA 格式:
<![CDATA[这里可以把你输入的字符原样显示,不会解析xml]]>
XML解析技术#
xml 是可扩展的标记语言。 不管是 html 文件还是 xml 文件它们都是标记型文档,都可以使用 w3c 组织制定的 dom 技术来解析
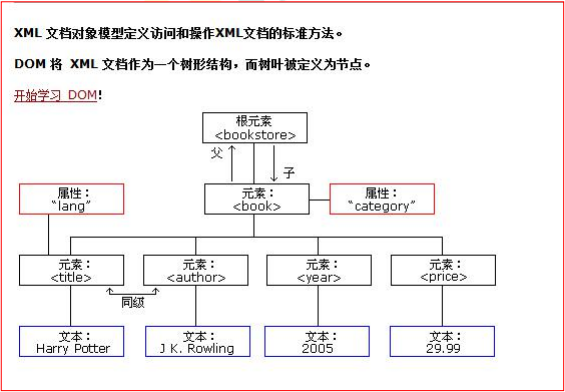
document 对象表示的是整个文档(可以是 html 文档,也可以是xml文档)
早期 JDK 为我们提供了两种 xml 解析技术 DOM 和 Sax 简介(已经过时,但我们需要知道这两种技术)
dom 解析技术是 W3C 组织制定的,而所有的编程语言都对这个解析技术使用了自己语言的特点进行实现。 Java 对 dom 技术解析标记也做了实现。
sun 公司在 JDK5 版本对 dom 解析技术进行升级:SAX( Simple API for XML ) SAX 解析,它跟 W3C 制定的解析不太一样。它是以类似事件机制通过回调告诉用户当前正在解析的内容。 它是一行一行的读取 xml 文件进行解析的。不会创建大量的 dom 对象。 所以它在解析 xml 的时候,在内存的使用上。和性能上。都优于 Dom 解析。
第三方的解析:
-
jdom 在 dom 基础上进行了封装
-
dom4j 又对 jdom 进行了封装。
-
pull 主要用在 Android 手机开发,是在跟 sax 非常类似都是事件机制解析 xml 文件。
Dom4j 它是第三方的解析技术。我们需要使用第三方给我们提供好的类库才可以解析 xml 文件。
Dom4j解析技术#
Dom4j 类库的使用#
由于 dom4j 它不是 sun 公司的技术,而属于第三方公司的技术,我们需要使用 dom4j 就需要到 dom4j 官网下载 dom4j 的 jar 包。
Dom4j 编程步骤#
- 先加载xml文件创建Document对象
- 通过Document对象拿到根元素对象
- 通过根元素.elements("标签名");可以返回一个集合,这个集合存放着所有你指定的标签名的元素对象
- 找到你想要修改、删除的子元素,进行相应的操作
- 保存到硬盘上
需要解析的books.xml文件内容
<?xml version="1.0" encoding="UTF-8"?>
<books>
<book sn="SN12341232">
<name>辟邪剑谱</name>
<price>9.9</price>
<author>班主任</author>
</book>
<book sn="SN12341231">
<name>葵花宝典</name>
<price>99.99</price>
<author>班长</author>
</book>
</books>
目录结构:
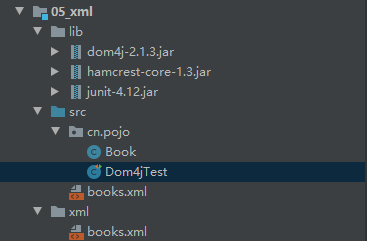
解析过程
package cn.pojo;
import org.dom4j.Document;
import org.dom4j.DocumentException;
import org.dom4j.Element;
import org.dom4j.io.SAXReader;
import org.junit.Test;
import java.util.List;
public class Dom4jTest {
/*
读取books.xml文件生成Book类
*/
@Test
public void test2(){
//1 读取boos.xml文件
//创建一个SaxReader输入流,去读取xml配置文件,生成Document对象
SAXReader saxReader = new SAXReader();
Document document = null;
//在JUnit测试中,相对路径是从模块名开始算
try {
document = saxReader.read("src/books.xml");
} catch (DocumentException e) {
e.printStackTrace();
}
//2 通过文档对象获取根元素
assert document != null;
Element rootElement = document.getRootElement();
System.out.println(rootElement);
//3 通过根元素获取book标签对象
//element()和elements()都是通过标签名查找子元素
List<Element> books = rootElement.elements("book");
//4 遍历,出来每个book标签转换为Book类
for(Element book : books){
//asXML()把标签对象转换为标签字符串
Element nameElement = book.element("name");
//System.out.println(nameElement.asXML());
//getText()可以获取标签中的文本内容
String nameText = nameElement.getText();
//直接获取指定标签名的文本内容
String priceText = book.elementText("price");
String authorText = book.elementText("author");
String snText = book.attributeValue("sn");
System.out.println(new Book(snText ,nameText, Double.parseDouble(priceText), authorText));
}
}
}
输出结果:
org.dom4j.tree.DefaultElement@754ba872 [Element: <books attributes: []/>]
Book{sn='SN12341232', name='辟邪剑谱', price=9.9, author='班主任'}
Book{sn='SN12341231', name='葵花宝典', price=99.99, author='班长'}
作者:xuzhuo123
出处:https://www.cnblogs.com/xuzhuo123/p/15376450.html
版权:本作品采用「署名-非商业性使用-相同方式共享 4.0 国际」许可协议进行许可。




【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)
· winform 绘制太阳,地球,月球 运作规律