

Python之路,Day01-Python基础知识
本节内容
1.Python介绍
2.了解IDLE窗口
3.函数+模块=标准库
4.anaconda介绍
5.变量、赋值、数据
6.项目1
7.循环嵌套 练习if elif P18
8.for 循环 内置函数range()
9.random模块
10.项目及练习
一 python介绍
python的创始人为吉多·范罗苏姆(Guido van Rossum)。1989年的圣诞节期间,吉多·范罗苏姆为了在阿姆斯特丹打发时间,决心开发一个新的脚本解释程序,作为ABC语言的一种继承。
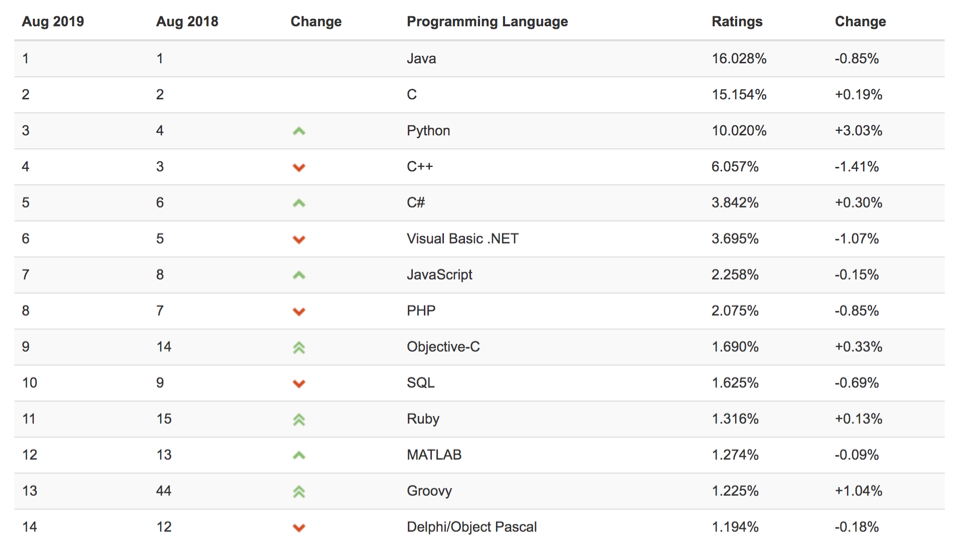
最新的TIOBE排行榜(https://www.tiobe.com/tiobe-index/),Python赶超C++占据第3, Python崇尚优美、清晰、简单,是一个优秀并广泛使用的语言。

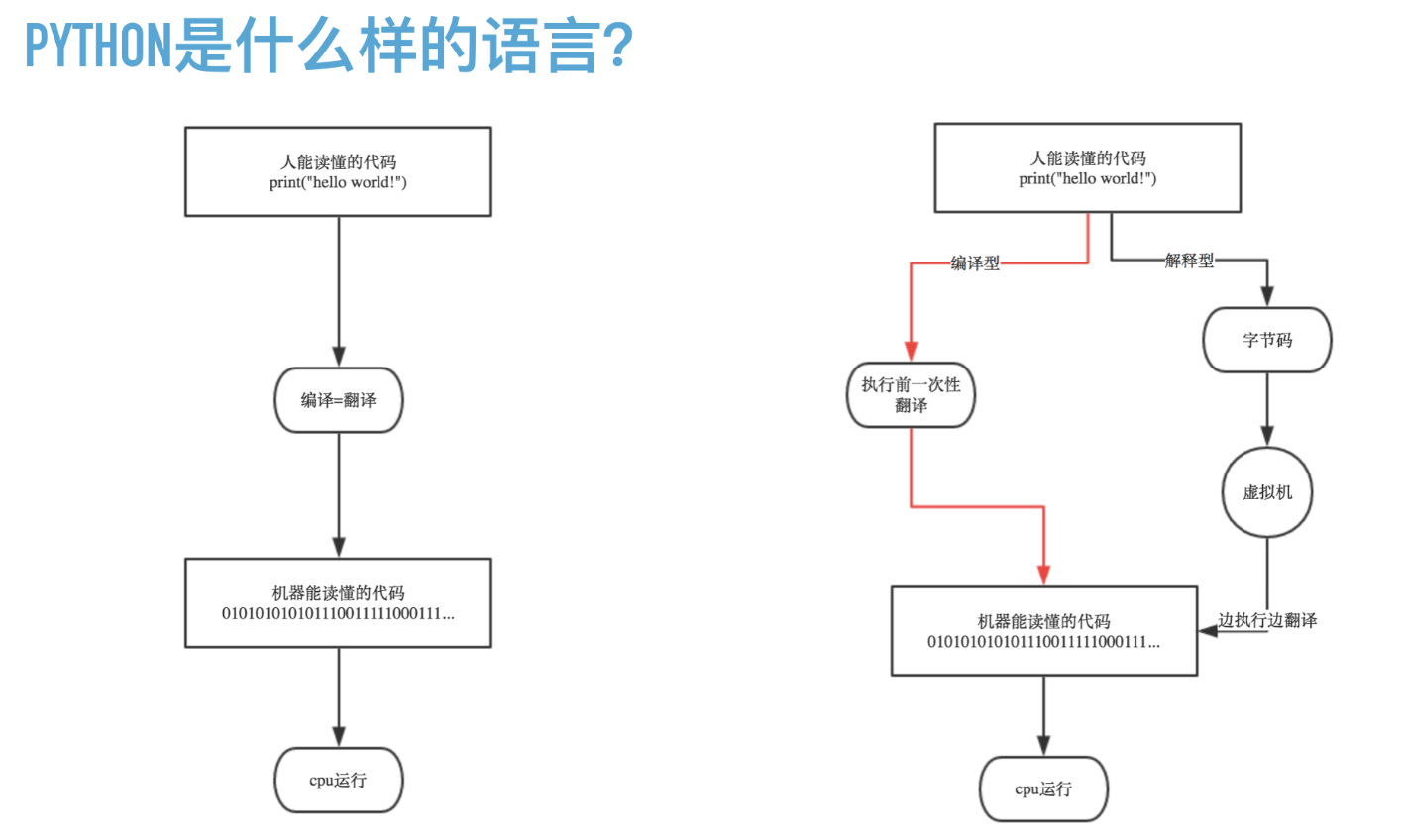
编程语言主要从以下几个角度为进行分类,编译型和解释型、静态语言和动态语言、强类型定义语言和弱类型定义语言,每个分类代表什么意思呢,我们一起来看一下。
编译和解释的区别是什么?
编译器是把源程序的每一条语句都编译成机器语言,并保存成二进制文件,这样运行时计算机可以直接以机器语言来运行此程序,速度很快;
而解释器则是只在执行程序时,才一条一条的解释成机器语言给计算机来执行,所以运行速度是不如编译后的程序运行的快的.
这是因为计算机不能直接认识并执行我们写的语句,它只能认识机器语言(是二进制的形式)
一、低级语言与高级语言
最初的计算机程序都是用0和1的序列表示的,程序员直接使用的是机器指令,无需翻译,从纸带打孔输入即可执行得到结果。后来为了方便记忆,就将用0、1序列表示的机器指令都用符号助记,这些与机器指令一一对应的助记符就成了汇编指令,从而诞生了汇编语言。无论是机器指令还是汇编指令都是面向机器的,统称为低级语言。因为是针对特定机器的机器指令的助记符,所以汇编语言是无法独立于机器(特定的CPU体系结构)的。但汇编语言也是要经过翻译成机器指令才能执行的,所以也有将运行在一种机器上的汇编语言翻译成运行在另一种机器上的机器指令的方法,那就是交叉汇编技术。
高级语言是从人类的逻辑思维角度出发的计算机语言,抽象程度大大提高,需要经过编译成特定机器上的目标代码才能执行,一条高级语言的语句往往需要若干条机器指令来完成。高级语言独立于机器的特性是靠编译器为不同机器生成不同的目标代码(或机器指令)来实现的。那具体的说,要将高级语言编译到什么程度呢,这又跟编译的技术有关了,既可以编译成直接可执行的目标代码,也可以编译成一种中间表示,然后拿到不同的机器和系统上去执行,这种情况通常又需要支撑环境,比如解释器或虚拟机的支持,Java程序编译成bytecode,再由不同平台上的虚拟机执行就是很好的例子。所以,说高级语言不依赖于机器,是指在不同的机器或平台上高级语言的程序本身不变,而通过编译器编译得到的目标代码去适应不同的机器。从这个意义上来说,通过交叉汇编,一些汇编程序也可以获得不同机器之间的可移植性,但这种途径获得的移植性远远不如高级语言来的方便和实用性大。
二、编译与解释
编译是将源程序翻译成可执行的目标代码,翻译与执行是分开的;而解释是对源程序的翻译与执行一次性完成,不生成可存储的目标代码。这只是表象,二者背后的最大区别是:对解释执行而言,程序运行时的控制权在解释器而不在用户程序;对编译执行而言,运行时的控制权在用户程序。
解释具有良好的动态特性和可移植性,比如在解释执行时可以动态改变变量的类型、对程序进行修改以及在程序中插入良好的调试诊断信息等,而将解释器移植到不同的系统上,则程序不用改动就可以在移植了解释器的系统上运行。同时解释器也有很大的缺点,比如执行效率低,占用空间大,因为不仅要给用户程序分配空间,解释器本身也占用了宝贵的系统资源。
编译器是把源程序的每一条语句都编译成机器语言,并保存成二进制文件,这样运行时计算机可以直接以机器语言来运行此程序,速度很快;
而解释器则是只在执行程序时,才一条一条的解释成机器语言给计算机来执行,所以运行速度是不如编译后的程序运行的快的.
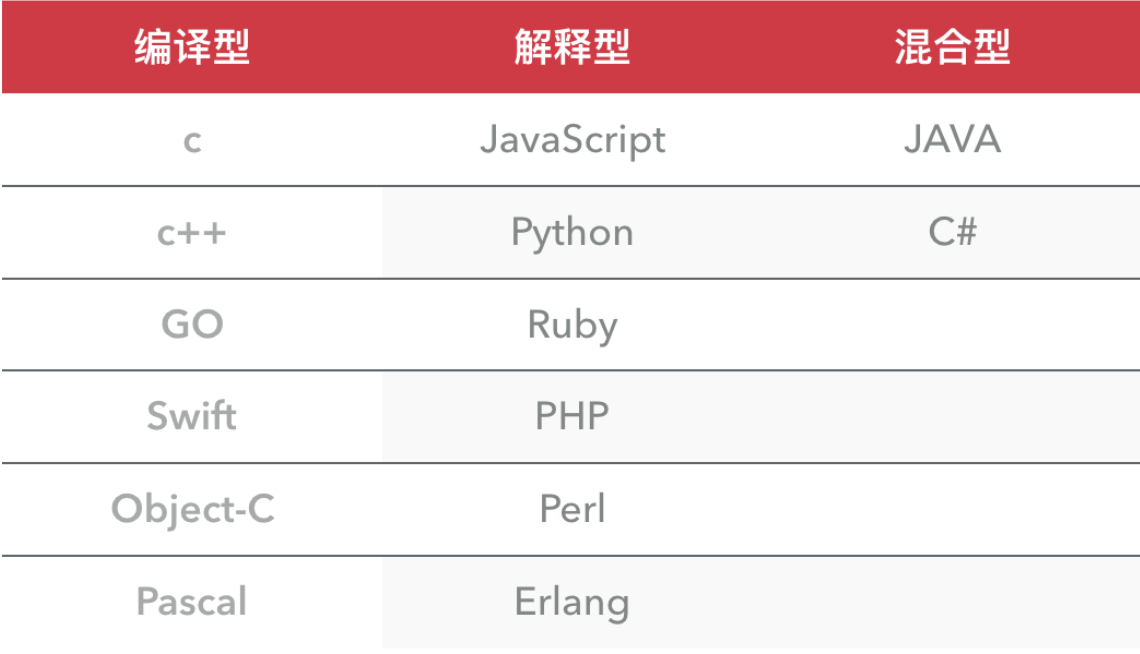
编译型和解释型
我们先看看编译型,其实它和汇编语言是一样的:也是有一个负责翻译的程序来对我们的源代码进行转换,生成相对应的可执行代码。这个过程说得专业一点,就称为编译(Compile),而负责编译的程序自然就称为编译器(Compiler)。如果我们写的程序代码都包含在一个源文件中,那么通常编译之后就会直接生成一个可执行文件,我们就可以直接运行了。但对于一个比较复杂的项目,为了方便管理,我们通常把代码分散在各个源文件中,作为不同的模块来组织。这时编译各个文件时就会生成目标文件(Object file)而不是前面说的可执行文件。一般一个源文件的编译都会对应一个目标文件。这些目标文件里的内容基本上已经是可执行代码了,但由于只是整个项目的一部分,所以我们还不能直接运行。待所有的源文件的编译都大功告成,我们就可以最后把这些半成品的目标文件“打包”成一个可执行文件了,这个工作由另一个程序负责完成,由于此过程好像是把包含可执行代码的目标文件连接装配起来,所以又称为链接(Link),而负责链接的程序就叫……就叫链接程序(Linker)。链接程序除了链接目标文件外,可能还有各种资源,像图标文件啊、声音文件啊什么的,还要负责去除目标文件之间的冗余重复代码,等等,所以……也是挺累的。链接完成之后,一般就可以得到我们想要的可执行文件了。
上面我们大概地介绍了编译型语言的特点,现在再看看解释型。噢,从字面上看,“编译”和“解释”的确都有“翻译”的意思,它们的区别则在于翻译的时机安排不大一样。打个比方:假如你打算阅读一本外文书,而你不知道这门外语,那么你可以找一名翻译,给他足够的时间让他从头到尾把整本书翻译好,然后把书的母语版交给你阅读;或者,你也立刻让这名翻译辅助你阅读,让他一句一句给你翻译,如果你想往回看某个章节,他也得重新给你翻译。
两种方式,前者就相当于我们刚才所说的编译型:一次把所有的代码转换成机器语言,然后写成可执行文件;而后者就相当于我们要说的解释型:在程序运行的前一刻,还只有源程序而没有可执行程序;而程序每执行到源程序的某一条指令,则会有一个称之为解释程序的外壳程序将源代码转换成二进制代码以供执行,总言之,就是不断地解释、执行、解释、执行……所以,解释型程序是离不开解释程序的。像早期的BASIC就是一门经典的解释型语言,要执行BASIC程序,就得进入BASIC环境,然后才能加载程序源文件、运行。解释型程序中,由于程序总是以源代码的形式出现,因此只要有相应的解释器,移植几乎不成问题。编译型程序虽然源代码也可以移植,但前提是必须针对不同的系统分别进行编译,对于复杂的工程来说,的确是一件不小的时间消耗,况且很可能一些细节的地方还是要修改源代码。而且,解释型程序省却了编译的步骤,修改调试也非常方便,编辑完毕之后即可立即运行,不必像编译型程序一样每次进行小小改动都要耐心等待漫长的Compiling…Linking…这样的编译链接过程。不过凡事有利有弊,由于解释型程序是将编译的过程放到执行过程中,这就决定了解释型程序注定要比编译型慢上一大截,像几百倍的速度差距也是不足为奇的。
编译型与解释型,两者各有利弊。前者由于程序执行速度快,同等条件下对系统要求较低,因此像开发操作系统、大型应用程序、数据库系统等时都采用它,像C/C++、Pascal/Object Pascal(Delphi)、VB等基本都可视为编译语言,而一些网页脚本、服务器脚本及辅助开发接口这样的对速度要求不高、对不同系统平台间的兼容性有一定要求的程序则通常使用解释性语言,如Java、JavaScript、VBScript、Perl、Python等等。
但既然编译型与解释型各有优缺点又相互对立,所以一批新兴的语言都有把两者折衷起来的趋势,例如Java语言虽然比较接近解释型语言的特征,但在执行之前已经预先进行一次预编译,生成的代码是介于机器码和Java源代码之间的中介代码,运行的时候则由JVM(Java的虚拟机平台,可视为解释器)解释执行。它既保留了源代码的高抽象、可移植的特点,又已经完成了对源代码的大部分预编译工作,所以执行起来比“纯解释型”程序要快许多。而像VB6(或者以前版本)、C#这样的语言,虽然表面上看生成的是.exe可执行程序文件,但VB6编译之后实际生成的也是一种中介码,只不过编译器在前面安插了一段自动调用某个外部解释器的代码(该解释程序独立于用户编写的程序,存放于系统的某个DLL文件中,所有以VB6编译生成的可执行程序都要用到它),以解释执行实际的程序体。C#(以及其它.net的语言编译器)则是生成.net目标代码,实际执行时则由.net解释系统(就像JVM一样,也是一个虚拟机平台)进行执行。当然.net目标代码已经相当“低级”,比较接近机器语言了,所以仍将其视为编译语言,而且其可移植程度也没有Java号称的这么强大,Java号称是“一次编译,到处执行”,而.net则是“一次编码,到处编译”。呵呵,当然这些都是题外话了。总之,随着设计技术与硬件的不断发展,编译型与解释型两种方式的界限正在不断变得模糊。
动态语言和静态语言
通常我们所说的动态语言、静态语言是指动态类型语言和静态类型语言。
(1)动态类型语言:动态类型语言是指在运行期间才去做数据类型检查的语言,也就是说,在用动态类型的语言编程时,永远也不用给任何变量指定数据类型,该语言会在你第一次赋值给变量时,在内部将数据类型记录下来。Python和Ruby就是一种典型的动态类型语言,其他的各种脚本语言如VBScript也多少属于动态类型语言。
(2)静态类型语言:静态类型语言与动态类型语言刚好相反,它的数据类型是在编译其间检查的,也就是说在写程序时要声明所有变量的数据类型,C/C++是静态类型语言的典型代表,其他的静态类型语言还有C#、JAVA等。
强类型定义语言和弱类型定义语言
(1)强类型定义语言:强制数据类型定义的语言。也就是说,一旦一个变量被指定了某个数据类型,如果不经过强制转换,那么它就永远是这个数据类型了。举个例子:如果你定义了一个整型变量a,那么程序根本不可能将a当作字符串类型处理。强类型定义语言是类型安全的语言。
(2)弱类型定义语言:数据类型可以被忽略的语言。它与强类型定义语言相反, 一个变量可以赋不同数据类型的值。
强类型定义语言在速度上可能略逊色于弱类型定义语言,但是强类型定义语言带来的严谨性能够有效的避免许多错误。另外,“这门语言是不是动态语言”与“这门语言是否类型安全”之间是完全没有联系的!
例如:Python是动态语言,是强类型定义语言(类型安全的语言); VBScript是动态语言,是弱类型定义语言(类型不安全的语言); JAVA是静态语言,是强类型定义语言(类型安全的语言)。
通过上面这些介绍,我们可以得出,python是一门动态解释性的强类型定义语言。
三、python的优缺点
先看优点
- Python的定位是“优雅”、“明确”、“简单”,所以Python程序看上去总是简单易懂,初学者学Python,不但入门容易,而且将来深入下去,可以编写那些非常非常复杂的程序。
- 开发效率非常高,Python有非常强大的第三方库,基本上你想通过计算机实现任何功能,Python官方库里都有相应的模块进行支持,直接下载调用后,在基础库的基础上再进行开发,大大降低开发周期,避免重复造轮子。
- 高级语言————当你用Python语言编写程序的时候,你无需考虑诸如如何管理你的程序使用的内存一类的底层细节
- 可移植性————由于它的开源本质,Python已经被移植在许多平台上(经过改动使它能够工 作在不同平台上)。如果你小心地避免使用依赖于系统的特性,那么你的所有Python程序无需修改就几乎可以在市场上所有的系统平台上运行
- 可扩展性————如果你需要你的一段关键代码运行得更快或者希望某些算法不公开,你可以把你的部分程序用C或C++编写,然后在你的Python程序中使用它们。
- 可嵌入性————你可以把Python嵌入你的C/C++程序,从而向你的程序用户提供脚本功能。
python


1 print("hello world")
c++
1 #include <iostream> 2 int main(void) 3 { 4 std::cout<<"Hello world"; 5 }
c
1 #include <stdio.h> 2 int main(void) 3 { 4 printf("\nhello world!"); 5 return 0; 6 }
java
1 public class HelloWorld{ 2 // 程序的入口 3 public static void main(String args[]){ 4 // 向控制台输出信息 5 System.out.println("Hello World!"); 6 } 7 }
php
1 <?php 2 echo "hello world!"; 3 ?>
ruby
puts "Hello world."
再看缺点:
- 速度慢,Python 的运行速度相比C语言确实慢很多,跟JAVA相比也要慢一些,因此这也是很多所谓的大牛不屑于使用Python的主要原因,但其实这里所指的运行速度慢在大多数情况下用户是无法直接感知到的,必须借助测试工具才能体现出来,比如你用C运一个程序花了0.01s,用Python是0.1s,这样C语言直接比Python快了10倍,算是非常夸张了,但是你是无法直接通过肉眼感知的,因为一个正常人所能感知的时间最小单位是0.15-0.4s左右,哈哈。其实在大多数情况下Python已经完全可以满足你对程序速度的要求,除非你要写对速度要求极高的搜索引擎等,这种情况下,当然还是建议你用C去实现的。
- 代码不能加密,因为PYTHON是解释性语言,它的源码都是以名文形式存放的,不过我不认为这算是一个缺点,如果你的项目要求源代码必须是加密的,那你一开始就不应该用Python来去实现。
- 线程不能利用多CPU问题,这是Python被人诟病最多的一个缺点,GIL即全局解释器锁(Global Interpreter Lock),是计算机程序设计语言解释器用于同步线程的工具,使得任何时刻仅有一个线程在执行,Python的线程是操作系统的原生线程。在Linux上为pthread,在Windows上为Win thread,完全由操作系统调度线程的执行。一个python解释器进程内有一条主线程,以及多条用户程序的执行线程。即使在多核CPU平台上,由于GIL的存在,所以禁止多线程的并行执行。关于这个问题的折衷解决方法,我们在以后线程和进程章节里再进行详细探讨。
二 了解IDLE窗口
回顾解释型。什么是IDE?Python还有哪些IDE?
三 函数+模块=标准库
1、 python模块类型
a.标准库
b.开源模块(github等)
c.自定义模块
2、观察标准库
1 import sys 2 sys.platform
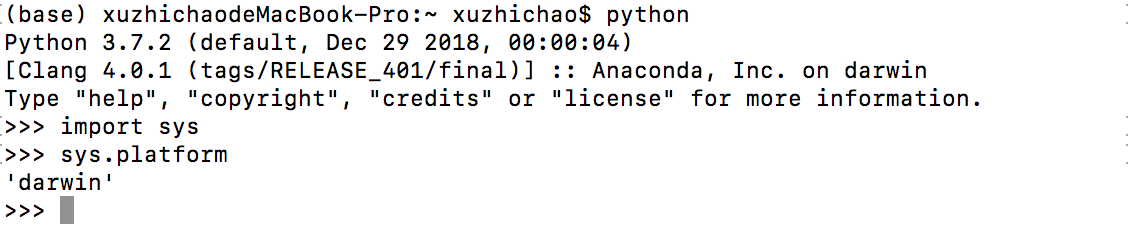
1 print(sys.version)

1 import os 2 os.getcwd()
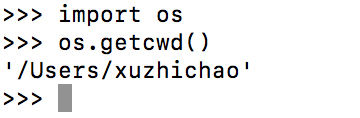
1 os.environ

1 import datetime 2 datetime.date.today()
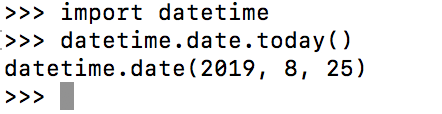
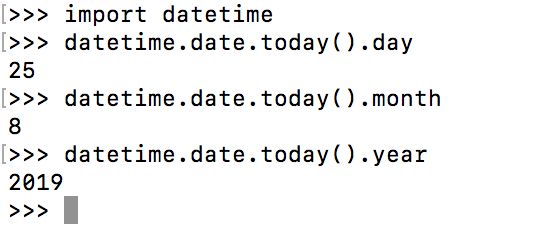
1 import datetime 2 datetime.date.today().day 3 datetime.date.today().month 4 datetime.date.today().year
1 datetime.date.isoformat(datetime.date.today())

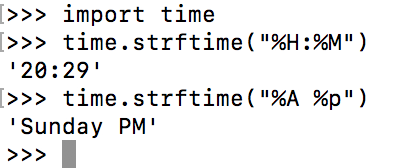
1 import time 2 time.strftime("%H:%M")
#%y 两位数的年份表示(00-99) #%Y 四位数的年份表示(000-9999) #%m 月份(01-12) #%d 月内中的一天(0-31) #%H 24小时制小时数(0-23) #%I 12小时制小时数(01-12) #%M 分钟数(00=59) #%S 秒(00-59) #%a 本地简化星期名称 #%A 本地完整星期名称 #%b 本地简化的月份名称 #%B 本地完整的月份名称 #%c 本地相应的日期表示和时间表示 #%j 年内的一天(001-366) #%p 本地A.M.或P.M.的等价符 #%U 一年中的星期数(00-53)星期天为星期的开始 #%w 星期(0-6),星期天为星期的开始 #%W 一年中的星期数(00-53)星期一为星期的开始 #%x 本地相应的日期表示 #%X 本地相应的时间表示 #%Z 当前时区的名称 #%% %号本身
1 import html 2 html.escape("This HTML fragment contains a <script>script</script> tag.") 3 html.unescape("I ♥ Python's <standard library>.")

问:怎么知道标准库的某个特定的模块做什么?
答:Python文档给出了标准库的所有答案:https://docs.python.org/3/library/index.html
标准库
1.时间模块:time与datetime
在Python中,通常有这几种方式来表示时间:
1)时间戳 指格林威治时间1970年01月01日00时00分00秒(北京时间1970年01月01日08时00分00秒)到现在等秒数(UNIX诞生元年)。
1 import time 2 time.time()
2)格式化的时间字符串
按照自己等格式定义的字符串例如:(2019-08-25 08:30:56)等
3)元组(struct_time)共九个元素。由于Python的time模块实现主要调用C库,所以各个平台可能有所不同。
UTC(Coordinated Universal Time,世界协调时)亦即格林威治天文时间,世界标准时间。在中国为UTC+8。DST(Daylight Saving Time)即夏令时。
*help的使用
1 import time 2 help(time)
1 import time 2 time.localtime()
1 import time 2 time.sleep(2)
1 import time 2 #转换成UTC 3 help(time.gmtime) 4 time.gmtime()
四 anaconda介绍(python的正确姿势)
python的一般安装方法:
windows:
1、 https://www.python.org/downloads/ 选择适合自己电脑的最新版本 (30M)
2、配置环境变量
【右键计算机】--》【属性】--》【高级系统设置】--》【高级】--》【环境变量】--》【在第二个内容框中找到 变量名为Path 的一行,双击】 --> 【Python安装目录追加到变值值中,用 ; 分割】 如:原来的值;C:\python37,切记前面有分号管理工具为:pip 例:
1 pip install request
anaconda介绍及安装:
Anaconda 是Python的一个开源发行版本,主要面向科学计算(数据分析、数据挖掘等)。(500-700M)
预装了非常多标准库,例如numpy(矩阵计算)、PIL(图像处理)、pandas(数据分析)等。
anaconda安装:
1、https://www.anaconda.com/distribution/
2、选择自动配置环境变量,不需要手动配置。
3、手动配置:(默认C:\ProgramData)
C:\ProgramData\Anaconda3;
C:\ProgramData\Anaconda3\Library\mingw-w64\bin;
C:\ProgramData\Anaconda3\Library\usr\bin;
C:\ProgramData\Anaconda3\Library\bin;
C:\ProgramData\Anaconda3\Scripts;
管理工具:conda
1 conda install pandas
五 变量、赋值、数据
变量用于存储要在计算机程序中引用和操作的信息。它们还提供了一种用描述性名称标记数据的方法,以便读者和我们自己能够更清楚地理解我们的程序。将变量看作包含信息的容器是有帮助的。它们的唯一目的是在内存中标记和存储数据。然后可以在整个程序中使用这些数据。
声明变量
1 #_*_coding:utf-8_*_ 2 3 name ="Zhichao Xu"
上述代码声明了一个变量,变量名为: name,变量name的值为:"Zhichao Xu"
变量定义的规则:
- 变量名只能是 字母、数字或下划线的任意组合
- 变量名的第一个字符不能是数字
- 以下关键字不能声明为变量名
['and', 'as', 'assert', 'break', 'class', 'continue', 'def', 'del', 'elif', 'else', 'except', 'exec', 'finally', 'for', 'from', 'global', 'if', 'import', 'in', 'is', 'lambda','not', 'or', 'pass', 'print', 'raise', 'return', 'try', 'while', 'with', 'yield']
变量的命名(补充):
正确的姿势:
1 wait_time = 26 2 gf_of_liu = "Lucy" #_类型,比较常用的类型 3 GFOfLiu = "Lucy" #首字母大写
错误的一些例子:
1 2age = 18 2 and = "true" 3 $name ="James" 4 gender is = "male"
变量的赋值:
1 name = "Zhichao" 2 3 name2 = name 4 print(name,name2) 5 6 name = "Han-Teng" 7 8 print("What is the value of name2 now?")
六 项目1
1 from datetime import datetime 2 3 odds = [ 1, 3, 5, 7, 9, 11,13,15,17,19 4 21,23,25,27,29,31,33,35,37,39 5 41,43,45,47,49,51,53,55,57,59] 6 7 right_this_minute = datetime.today().minute 8 9 if right_this_minute in odds: 10 print("This minute seems a little odd.") 11 else: 12 print("Not an odd minute.")
注:if语句
if 条件:
if-语句块
if 条件:
if-语句块
else:
else-语句块
if 条件:
if-语句块
elif 条件:
elif-语句块
...
else:
else-语句块
可以进行嵌套。 不要超过3层, 最多5层
七 循环嵌套 练习if elif P18
1 if today == "Saturday": 2 print("Party!") 3 elif today == "Sunday": 4 if condition == "Headache": 5 print("Recover, then rest.") 6 else: 7 print("Rest.") 8 else: 9 print("Work, work, work.")
八 for 循环 内置函数range()
用例1 循环迭代数字变量
1 for i in [1,2,3]: 2 print(i)
用例2 循环迭代字符串变量
1 for ch in "Hi!": 2 print(ch)
用例3 迭代指定的次数
1 for num in range(5): 2 print('Head First Rocks!')
range 实验:
1 range(5) 2 3 list(range(5)) 4 5 list(range(5,10)) 6 7 list(range(0,10,2)) 8 9 list(range(10,0,-2)) 10 11 list(range(10,0,2)) 12 13 list(range(99,0,-1))
九 random模块
1 import random 2 print(random.random()) 3 #random.random()用于生成一个0到1的随机符点数: 0 <= n < 1.0
1 print (random.randint(1,7)) 2 #random.randint()的函数原型为:random.randint(a, b),用于生成一个指定范围内的整数。 3 # 其中参数a是下限,参数b是上限,生成的随机数n: a <= n <= b
大脑 P35测试 (改):
1 from datetime import datetime 2 3 import random 4 import time 5 6 odds = [1,3,5,7,9,11,13,15,17,19,21,23,25,27,29,31,33,35,37,39,41,43,45,47,49,51,53,55,57,59] 7 8 for i in range(5): 9 right_this_second = datetime.today().second 10 if right_this_second in odds: 11 print("This second seems a little odd.") 12 else: 13 print("Not an odd second.") 14 wait_time = random.randint(1,5) 15 time.sleep(wait_time)
十 练习
题目1:暂停一秒输出
题目2:输入某年某月某日,判断该日是这一年的第几天?
题目3:暂停一秒输出,并格式化当前的时间
附加题:1、有四个数字:1、2、3、4,能组成多少个互不相同且无重复数字的三位数?各是多少?
2、尝试输出9*9乘法表
