6.B+Tree 检索原理
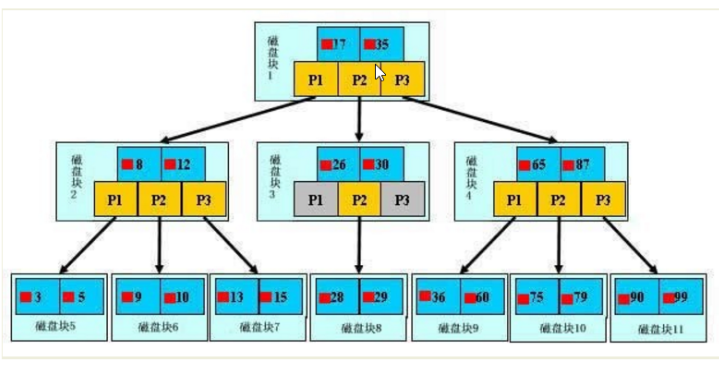

B+树的创建(索引的创建)
1.比如为phoneNum创建了一个索引,phoneNum这列保存了很多的手机号码
2.索引创建的过程中,会为这些数据进行适当的编码(根据这个数据所在的物理地址),如 3670 可能编成 66 这个号码
3.然后根据所有编成的号码,创建一些对比值,这些对比值实际上是不存在的,
4.将这些对比值作为根和支,编成的号码作为叶子,这些叶子节点都是一个一个的引用,指向了实际数据的物理地址
构成一颗多路径的树,可以是二叉,也可以是三、四叉
注:在和对比值比较的过程中,最后叶子节点的排列也是按照一定顺序的,如比它小,就排在左边,小就排在右边,所以索引是一种排好序的数据结构
5.将这棵树,以文件的方式存储在磁盘中
B+树的使用(索引的使用)
1.当使用的 sql语句用到了phoneNum时,这颗B树被加载到了内存中,此时我的查询条件比如说是 3670,
2.会使用 3670 对应的 编成的号码66,去查询这棵树,这样一层一层查下去,最终拿到66
3.拿到66之后,再去取出 3670
(66 这是一个引用,指向了 3670 对应的物理地址,)
树的高度决定了 io操作的次数,三层就会进行三次io操作,从磁盘中去读数据
B树和B+树区别:B+树是B树的一种变种
1.B树中同一键值不会出现多次,并且它有可能出现在叶结点,也有可能出现在非叶结点中。
而B+树的键一定会出现在叶结点中,并且有可能在非叶结点中也有可能重复出现,以维持B+树的平衡。
2.因为B树键位置不定,且在整个树结构中只出现一次,虽然可以节省存储空间,
但使得在插入、删除操作复杂度明显增加。B+树相比来说是一种较好的折中。
3.B树的查询效率与键在树中的位置有关,最大时间复杂度与B+树相同(在叶结点的时候),
最小时间复杂度为1(在根结点的时候)。而B+树的时候复杂度对某建成的树是固定的
事实上,在MySQL数据库中,诸多存储引擎使用的是B+树,即便其名字看上去是BTREE。Innodb和 Myisam 都是使用B+树来创建索引

